

Utmaningen med underanpassning och överanpassning vid maskininlärning
Du kommer oundvikligen att ställas inför den här frågan i en intervju med en datavetare:
Kan du förklara vad som är underanpassning och överanpassning i samband med maskininlärning? Beskriv det på ett sätt som även en icke-teknisk person kan förstå.
Din förmåga att förklara detta på ett icke-tekniskt och lättförståeligt sätt kan mycket väl avgöra om du är lämplig för rollen som datavetare!
Även när vi arbetar med ett projekt för maskininlärning möter vi ofta situationer där vi stöter på oväntade skillnader i prestanda eller felfrekvens mellan träningsuppsättningen och testuppsättningen (som visas nedan). Hur kan en modell prestera så bra på träningsuppsättningen och lika dåligt på testuppsättningen?

Detta händer mycket ofta när jag arbetar med trädbaserade prediktiva modeller. På grund av hur algoritmerna fungerar kan du föreställa dig hur svårt det är att undvika att hamna i överanpassningsfällan!
Det kan dessutom vara ganska skrämmande när vi inte kan hitta den underliggande orsaken till varför vår prediktiva modell uppvisar detta onormala beteende.
Här är min personliga erfarenhet – om du frågar en erfaren datavetare om det här, börjar de vanligtvis prata om en rad fina termer som överanpassning, underanpassning, bias och varians. Men det är få som talar om intuitionen bakom dessa begrepp för maskininlärning. Låt oss rätta till det, ska vi?
Låt oss ta ett exempel för att förstå Underfitting vs. Overfitting
Jag vill förklara dessa begrepp med hjälp av ett exempel från den verkliga världen. Många pratar om den teoretiska vinkeln men jag känner att det inte räcker – vi måste visualisera hur underfitting och overfitting faktiskt fungerar.
Så, låt oss gå tillbaka till vår collegetid för detta.

Tänk på en matematikklass som består av tre elever och en professor.
Nu, i varje klassrum, kan vi i stort sett dela in eleverna i tre kategorier. Vi kommer att tala om dem en och en.

Låt oss säga att elev A liknar en elev som inte gillar matematik. Hon är inte intresserad av det som lärs ut i klassen och ägnar därför inte mycket uppmärksamhet åt professorn och det innehåll han lär ut.

Låt oss tänka på elev B. Han är den mest tävlingsinriktade eleven som fokuserar på att memorera varje fråga som lärs ut i klassen i stället för att fokusera på de viktigaste begreppen. I grund och botten är han inte intresserad av att lära sig problemlösningsmetoden.

Slutligt har vi den ideala eleven C. Hon är enbart intresserad av att lära sig nyckelbegreppen och problemlösningsmetoden i matematiklektionen i stället för att bara memorera de lösningar som presenteras.

Vi vet alla av erfarenhet vad som händer i ett klassrum. Professorn håller först föreläsningar och lär eleverna om problemen och hur de ska lösas. I slutet av dagen tar professorn helt enkelt en frågesport baserad på det han lärde ut i klassen.
Hindret kommer i de termins3 prov som skolan lägger upp. Det är där nya frågor (osynliga uppgifter) dyker upp. Studenterna har inte sett dessa frågor tidigare och har definitivt inte löst dem i klassrummet. Låter det bekant?
Så, låt oss diskutera vad som händer när läraren gör ett klassrumstest i slutet av dagen:

- Student A, som var distraherad i sin egen värld, gissade helt enkelt svaren och fick ungefär 50 % poäng på provet
- Å andra sidan kunde den student som memorerade varenda fråga som lärdes ut i klassrummet svara på nästan varje fråga utantill och fick därför 98 % poäng på klassprovet
- För student C, löste hon faktiskt alla frågor med hjälp av den problemlösningsmetod som hon lärt sig i klassrummet och fick 92 %
Vi kan tydligt dra slutsatsen att den elev som helt enkelt lär sig allting utantill får bättre resultat utan större svårigheter.
Nu kommer det nya. Låt oss också titta på vad som händer under månadstestet, när eleverna måste möta nya okända frågor som läraren inte har lärt ut i klassen.

- I fallet med elev A förändrades inte saker och ting särskilt mycket och han svarar fortfarande slumpmässigt på frågorna korrekt ~50 % av gångerna.
- I fallet med elev B sjönk hans poäng avsevärt. Kan du gissa varför? Detta beror på att han alltid memorerade de problem som lärdes ut i klassen, men det här månadstestet innehöll frågor som han aldrig har sett förut. Därför sjönk hans prestation avsevärt
- I fallet med elev C förblev poängen mer eller mindre oförändrad. Detta beror på att hon fokuserade på att lära sig problemlösningsmetoden och därför kunde tillämpa de begrepp hon lärt sig för att lösa de okända frågorna
Hur relaterar detta till underanpassning och överanpassning i maskininlärning?
Du kanske undrar hur det här exemplet relaterar till problemet som vi stötte på under tränings- och testpoängen för klassificeraren beslutsträd? Bra fråga!
Så, låt oss arbeta på att koppla ihop det här exemplet med resultaten av beslutsträdsklassificatorn som jag visade dig tidigare.

För det första liknar klassarbetet och klasstestet träningsdata respektive förutsägelsen över själva träningsdata. Å andra sidan representerar terminstestet testuppsättningen från våra data som vi håller åt sidan innan vi tränar vår modell (eller osynliga data i ett verkligt maskininlärningsprojekt).
Nu kan du erinra dig vår klassificerare med beslutsträd som jag nämnde tidigare. Den gav ett perfekt resultat för träningsuppsättningen men hade problem med testuppsättningen. Om man jämför det med de elevexempel som vi just diskuterade, upprättar klassificeraren en analogi med elev B som försökte memorera varenda fråga i träningsuppsättningen.
På samma sätt försöker vår klassificerare av beslutsträd lära sig varenda punkt från träningsdata, men lider radikalt när den möter en ny datapunkt i testuppsättningen. Den kan inte generalisera den väl.

Denna situation där en given modell presterar för bra på träningsdata men prestandan sjunker avsevärt över testuppsättningen kallas för en överanpassningsmodell.
Till exempel är icke-parametriska modeller som beslutsträd, KNN och andra trädbaserade algoritmer mycket benägna att överanpassas. Dessa modeller kan lära sig mycket komplexa relationer vilket kan resultera i överanpassning. Grafen nedan sammanfattar detta begrepp:
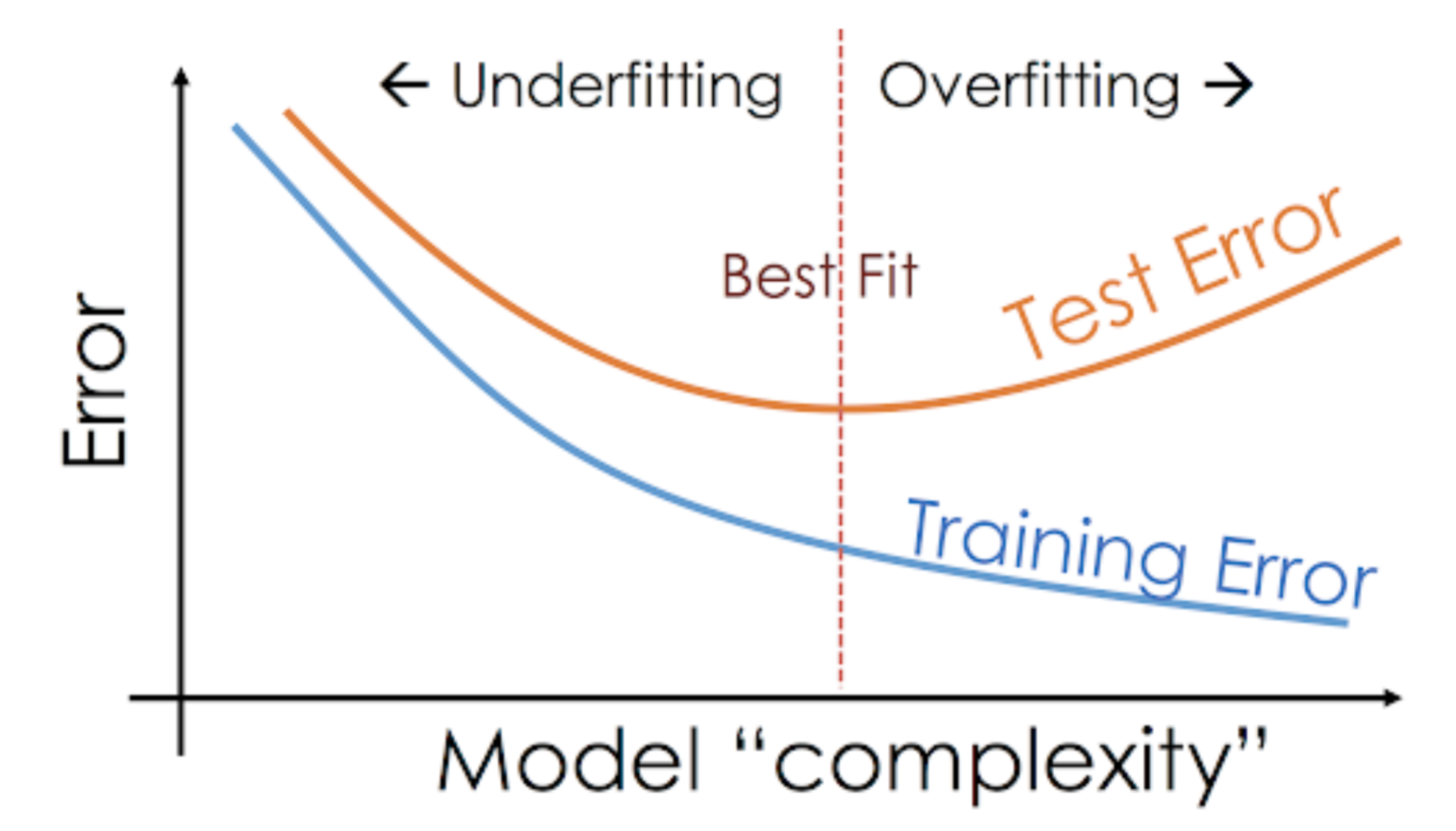
Om modellen å andra sidan presterar dåligt i test- och träningsuppsättningen kallar vi den för en underanpassad modell. Ett exempel på denna situation är att bygga en linjär regressionsmodell över icke-linjära data.
