

O Desafio do Sobreapetrechamento e do Sobreapetrechamento no Aprendizado de Máquinas
Vocês inevitavelmente enfrentarão esta questão numa entrevista com cientistas de dados:
Pode explicar o que é subapetrechamento e Sobreapetrechamento no contexto do Aprendizado de Máquinas? Descreva-a de uma forma que até uma pessoa não-técnica entenderá.
A sua capacidade de explicar isto de uma forma não-técnica e fácil de entender pode muito bem decidir o seu ajuste para o papel da ciência dos dados!
Quando estamos a trabalhar num projecto de aprendizagem de máquinas, muitas vezes enfrentamos situações em que estamos a encontrar um desempenho inesperado ou diferenças na taxa de erro entre o conjunto de treino e o conjunto de teste (como mostrado abaixo). Como pode um modelo ter um desempenho tão bom sobre o conjunto de treinamento e tão mau sobre o conjunto de teste?

Isto acontece com muita frequência sempre que estou trabalhando com modelos preditivos baseados em árvores. Devido à forma como os algoritmos funcionam, você pode imaginar como é complicado evitar cair na armadilha do sobreajuste!
Além disso, pode ser bastante assustador quando somos incapazes de encontrar a razão subjacente para o nosso modelo de previsão estar exibindo esse comportamento anômalo.
Aqui está a minha experiência pessoal – pergunte a qualquer cientista de dados experiente sobre isso, eles normalmente começam a falar sobre alguns termos extravagantes como Sobreajuste, Subajuste, Viés e Variância. Mas pouco se fala sobre a intuição por trás desses conceitos de aprendizagem da máquina. Vamos rectificar isso, devemos?
Vamos dar um exemplo para entender Underfitting vs. Overfitting
Quero explicar estes conceitos usando um exemplo do mundo real. Muitas pessoas falam sobre o ângulo teórico mas eu sinto que isso não é suficiente – precisamos visualizar como o underfitting e overfitting realmente funcionam.
Então, vamos voltar aos nossos dias de faculdade para isso.

Considerar uma aula de matemática composta por 3 alunos e um professor.
Agora, em qualquer sala de aula, podemos dividir amplamente os alunos em 3 categorias. Vamos falar sobre eles um a um.

Vamos dizer que o aluno A se assemelha a um aluno que não gosta de matemática. Ela não está interessada no que está sendo ensinado na aula e, portanto, não presta muita atenção ao professor e ao conteúdo que ele está ensinando.

Consideremos o aluno B. Ele é o aluno mais competitivo que se concentra na memorização de cada questão que está sendo ensinada na aula, em vez de se concentrar nos conceitos-chave. Basicamente, ele não está interessado em aprender a abordagem de resolução de problemas.

Finalmente, temos o aluno ideal C. Ela está puramente interessada em aprender os conceitos-chave e a abordagem de resolução de problemas na aula de matemática em vez de apenas memorizar as soluções apresentadas.

Todos nós sabemos por experiência própria o que acontece numa sala de aula. O professor primeiro faz palestras e ensina os alunos sobre os problemas e como resolvê-los. No final do dia, o professor simplesmente faz um teste baseado no que ensinou na aula.
O obstáculo vem no teste semestral3 que a escola estabelece. É aqui que surgem as novas perguntas (dados não vistos). Os alunos nunca viram estas questões antes e certamente ainda não as resolveram em sala de aula. Soa familiar?
Então, vamos discutir o que acontece quando o professor faz um teste em sala de aula no final do dia:

- O aluno A, que estava distraído em seu próprio mundo, simplesmente adivinhou as respostas e obteve aproximadamente 50% de nota no teste
- Por outro lado, o aluno que memorizou cada pergunta ensinada na sala de aula foi capaz de responder quase todas as perguntas pela memória e, portanto, obteve 98% de nota no teste de classe
- Para o aluno C, ela realmente resolveu todas as questões usando a abordagem de solução de problemas que ela aprendeu na sala de aula e marcou 92%
Nós podemos inferir claramente que o aluno que simplesmente memoriza tudo está pontuando melhor sem muita dificuldade.
Agora aqui está a reviravolta. Vejamos também o que acontece durante o teste mensal, quando os alunos têm que enfrentar novas perguntas desconhecidas que não são ensinadas na aula pelo professor.

- No caso do aluno A, as coisas não mudaram muito e ele ainda responde as perguntas corretamente ~50% do tempo.
- No caso do aluno B, sua pontuação caiu significativamente. Você pode adivinhar por quê? Isto porque ele sempre memorizou os problemas que eram ensinados na aula, mas este teste mensal continha perguntas que ele nunca tinha visto antes. Portanto, seu desempenho caiu significativamente
- No caso do Aluno C, a pontuação permaneceu mais ou menos a mesma. Isto porque ela se concentrou na aprendizagem da abordagem de resolução de problemas e, portanto, foi capaz de aplicar os conceitos que aprendeu para resolver as questões desconhecidas
Como é que isto se relaciona com o sub-conjunto e o sobre-conjunto na aprendizagem de máquinas?
Você pode estar se perguntando como este exemplo se relaciona com o problema que encontramos durante o trem e as notas do classificador da árvore de decisão? Boa pergunta!
Então, vamos trabalhar para conectar este exemplo com os resultados do classificador da árvore de decisão que mostrei anteriormente.

Primeiro, o trabalho de classe e o teste de classe assemelham-se aos dados de treinamento e à previsão sobre os próprios dados de treinamento, respectivamente. Por outro lado, o teste semestral representa o conjunto de testes dos nossos dados que guardamos de lado antes de treinarmos o nosso modelo (ou dados não vistos num projecto de aprendizagem de máquinas do mundo real).
Agora, lembre-se do nosso classificador de árvore de decisão que mencionei anteriormente. Ele deu uma pontuação perfeita sobre o conjunto de treinamento, mas teve dificuldades com o conjunto de testes. Comparando com os exemplos de alunos que acabamos de discutir, o classificador estabelece uma analogia com o aluno B que tentou memorizar cada uma das questões do conjunto de treinamento.
Similiarmente, nosso classificador da árvore de decisão tenta aprender cada ponto dos dados de treinamento, mas sofre radicalmente quando encontra um novo ponto de dados no conjunto de teste. Ele não é capaz de generalizá-lo bem.

Esta situação em que qualquer modelo está tendo um desempenho muito bom nos dados de treinamento, mas o desempenho cai significativamente sobre o conjunto de teste é chamado de modelo overfitting.
Por exemplo, modelos não paramétricos como árvores de decisão, KNN, e outros algoritmos baseados em árvores são muito propensos a overfitting. Estes modelos podem aprender relações muito complexas que podem resultar em sobreajustamento. O gráfico abaixo resume este conceito:
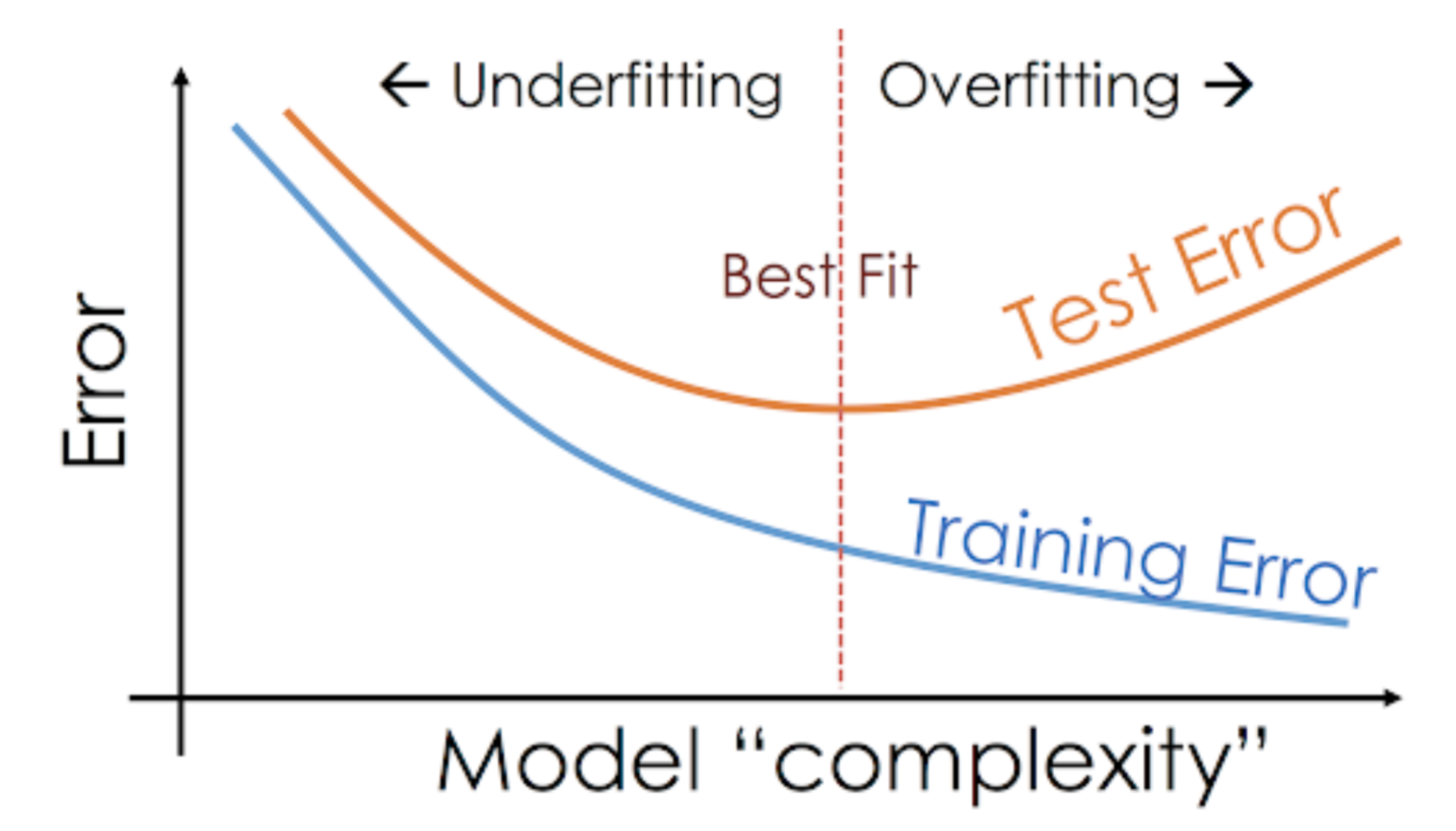
Por outro lado, se o modelo está a ter um mau desempenho no teste e no conjunto de comboios, então chamamos a isto um modelo de subajustamento. Um exemplo desta situação seria construir um modelo de regressão linear sobre dados não lineares.
