

Le défi de l’underfitting et du overfitting dans l’apprentissage automatique
Vous serez inévitablement confronté à cette question lors d’un entretien avec un data scientist :
Pouvez-vous expliquer ce qu’est l’underfitting et l’overfitting dans le contexte de l’apprentissage automatique ? Décrivez-le d’une manière que même une personne non technique pourra saisir.
Votre capacité à expliquer cela d’une manière non technique et facile à comprendre pourrait bien décider de votre adéquation au rôle de data scientist !
Même lorsque nous travaillons sur un projet d’apprentissage automatique, nous sommes souvent confrontés à des situations où nous rencontrons des différences de performance ou de taux d’erreur inattendues entre l’ensemble d’entraînement et l’ensemble de test (comme indiqué ci-dessous). Comment un modèle peut-il être aussi performant sur l’ensemble d’apprentissage et tout aussi médiocre sur l’ensemble de test ?

Cela arrive très fréquemment chaque fois que je travaille avec des modèles prédictifs basés sur des arbres. En raison de la façon dont les algorithmes fonctionnent, vous pouvez imaginer à quel point il est délicat d’éviter de tomber dans le piège de l’overfitting !
De plus, cela peut être assez décourageant lorsque nous ne sommes pas en mesure de trouver la raison sous-jacente pour laquelle notre modèle prédictif présente ce comportement anormal.
Voici mon expérience personnelle – demandez à n’importe quel data scientist chevronné à ce sujet, ils commencent généralement à parler d’une panoplie de termes fantaisistes comme Overfitting, Underfitting, Bias, et Variance. Mais peu de gens parlent de l’intuition derrière ces concepts d’apprentissage automatique. Rectifions cela, voulez-vous ?
Prenons un exemple pour comprendre l’Underfitting vs. Overfitting
Je veux expliquer ces concepts à l’aide d’un exemple du monde réel. Beaucoup de gens parlent de l’angle théorique, mais je pense que ce n’est pas suffisant – nous devons visualiser comment l’underfitting et le overfitting fonctionnent réellement.
Donc, revenons à nos jours de collège pour cela.

Considérons une classe de mathématiques composée de 3 étudiants et d’un professeur.
Maintenant, dans n’importe quelle classe, nous pouvons largement diviser les étudiants en 3 catégories. Nous allons parler d’eux un par un.

Disons que l’élève A ressemble à un élève qui n’aime pas les mathématiques. Elle n’est pas intéressée par ce qui est enseigné en classe et ne prête donc pas beaucoup d’attention au professeur et au contenu qu’il enseigne.

Prenons l’étudiant B. Il est l’étudiant le plus compétitif qui se concentre sur la mémorisation de chaque question enseignée en classe au lieu de se concentrer sur les concepts clés. Fondamentalement, il n’est pas intéressé par l’apprentissage de l’approche de résolution de problèmes.

Enfin, nous avons l’étudiant idéal C. Elle est purement intéressée par l’apprentissage des concepts clés et l’approche de résolution de problèmes dans le cours de mathématiques plutôt que de simplement mémoriser les solutions présentées.

Nous savons tous par expérience ce qui se passe dans une salle de classe. Le professeur donne d’abord des cours et enseigne aux élèves les problèmes et la façon de les résoudre. A la fin de la journée, le professeur se contente de faire passer une interrogation basée sur ce qu’il a enseigné en classe.
L’obstacle vient lors des tests semestriels3 que l’école fixe. C’est là que de nouvelles questions (données non vues) apparaissent. Les étudiants n’ont pas vu ces questions auparavant et ne les ont certainement pas résolues en classe. Cela vous semble familier ?
Donc, discutons de ce qui se passe lorsque l’enseignant fait passer un test en classe à la fin de la journée :

- L’élève A, qui était distrait dans son propre monde, a simplement deviné les réponses et a obtenu environ 50% de notes au test
- En revanche, l’élève qui a mémorisé chacune des questions enseignées en classe a pu répondre à presque toutes les questions de mémoire et a donc obtenu 98% de notes au test de classe
- Pour l’élève C, elle a effectivement résolu toutes les questions en utilisant l’approche de résolution de problèmes qu’elle a apprise en classe et a obtenu 92%
Nous pouvons clairement en déduire que l’élève qui se contente de tout mémoriser obtient de meilleures notes sans grande difficulté.
Voici maintenant le rebondissement. Regardons également ce qui se passe pendant le test mensuel, lorsque les étudiants doivent faire face à de nouvelles questions inconnues qui ne sont pas enseignées en classe par le professeur.

- Dans le cas de l’étudiant A, les choses n’ont pas beaucoup changé et il répond encore aléatoirement aux questions correctement ~50% du temps.
- Dans le cas de l’étudiant B, son score a chuté de manière significative. Pouvez-vous deviner pourquoi ? C’est parce qu’il a toujours mémorisé les problèmes enseignés en classe, mais ce test mensuel contenait des questions qu’il n’avait jamais vues auparavant. Par conséquent, sa performance a baissé de manière significative
- Dans le cas de l’élève C, le score est resté plus ou moins le même. C’est parce qu’elle s’est concentrée sur l’apprentissage de l’approche de résolution de problèmes et a donc été capable d’appliquer les concepts qu’elle a appris pour résoudre les questions inconnues
Comment cela se rapporte-t-il à l’underfitting et au overfitting dans l’apprentissage automatique ?
Vous vous demandez peut-être comment cet exemple se rapporte au problème que nous avons rencontré pendant les scores de train et de test du classificateur d’arbre de décision ? Bonne question!
Alors, travaillons à connecter cet exemple avec les résultats du classificateur à arbre de décision que je vous ai montré plus tôt.

Tout d’abord, le travail de classe et le test de classe ressemblent respectivement aux données de formation et à la prédiction sur les données de formation elles-mêmes. D’autre part, le test de semestre représente l’ensemble de test de nos données que nous gardons de côté avant de former notre modèle (ou des données non vues dans un projet d’apprentissage automatique du monde réel).
Maintenant, rappelez-vous notre classificateur d’arbre de décision que j’ai mentionné plus tôt. Il a donné un score parfait sur l’ensemble d’entraînement mais a lutté avec l’ensemble de test. En comparant cela aux exemples d’étudiants dont nous venons de parler, le classificateur établit une analogie avec l’étudiant B qui a essayé de mémoriser chaque question de l’ensemble d’entraînement.
De même, notre classificateur à arbre de décision essaie d’apprendre chaque point des données d’entraînement mais souffre radicalement lorsqu’il rencontre un nouveau point de données dans l’ensemble de test. Il n’est pas en mesure de bien le généraliser.

Cette situation où un modèle donné est trop performant sur les données d’apprentissage mais où la performance chute de manière significative sur l’ensemble de test est appelée un modèle surajusté.
Par exemple, les modèles non paramétriques comme les arbres de décision, KNN, et d’autres algorithmes basés sur les arbres sont très enclins au surajustement. Ces modèles peuvent apprendre des relations très complexes, ce qui peut entraîner un surajustement. Le graphique ci-dessous résume ce concept :
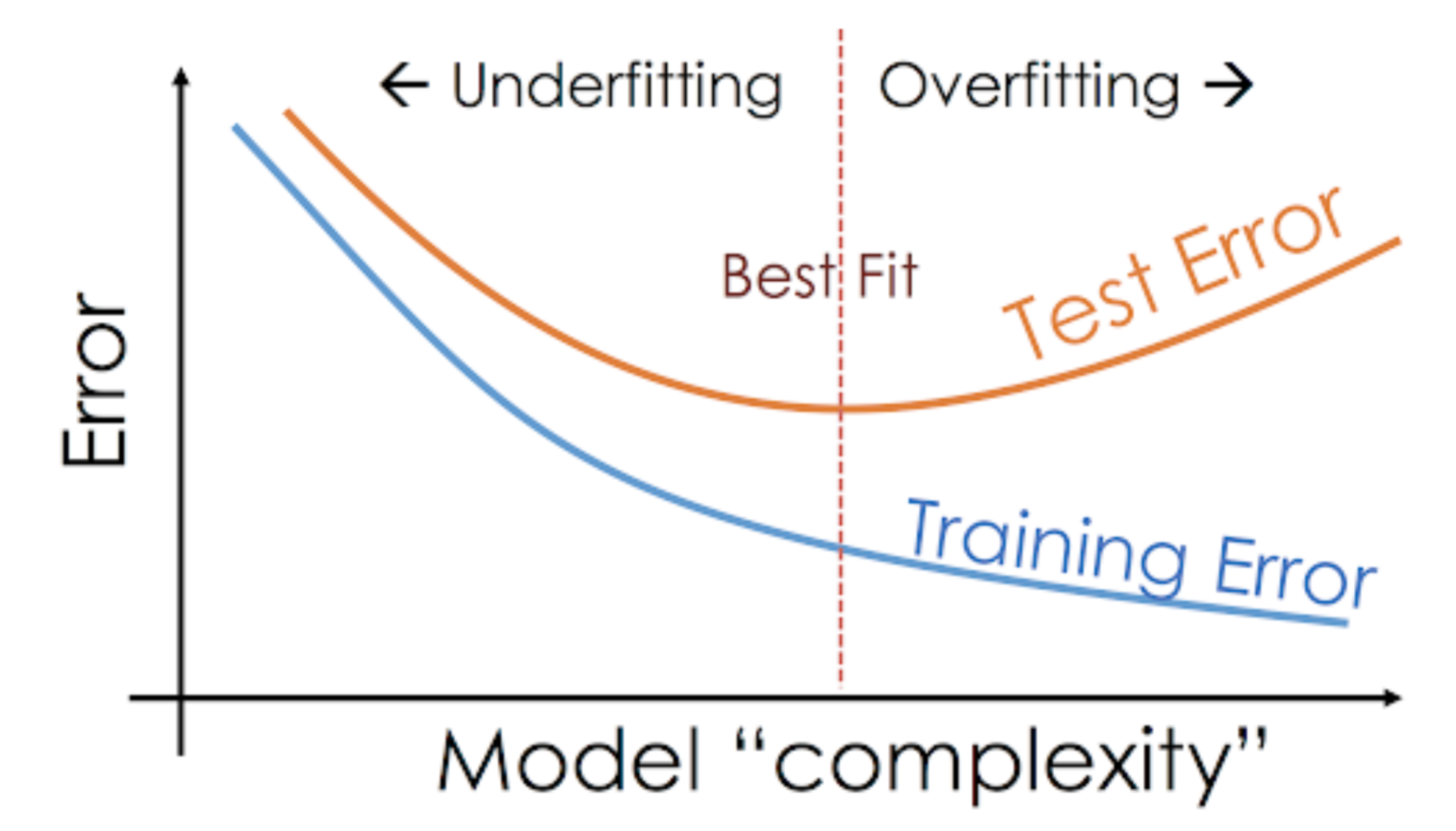
D’autre part, si le modèle a des performances médiocres sur l’ensemble de test et l’ensemble d’entraînement, on parle alors de modèle sous-adapté. Un exemple de cette situation serait de construire un modèle de régression linéaire sur des données non linéaires.

.