機械学習におけるアンダーフィットとオーバーフィットの課題
データサイエンティストの面接では、必ずこの質問に直面します:
機械学習のコンテキストでアンダーフィットとオーバーフィットとは何かを説明できますか。 非技術者でも把握できるように説明してください。
非技術的でわかりやすい方法で説明できるかどうかで、データサイエンスの役割への適合性が決まるかもしれません!
機械学習プロジェクトに取り組んでいるときでも、トレーニングセットとテストセットで予想外のパフォーマンスやエラー率の差(以下のような)に直面することがよくあります。 あるモデルが、トレーニング セットでは非常に良いパフォーマンスなのに、テスト セットでは同じように悪いとはどういうことでしょうか。

これは、私が木ベースの予測モデルを使用しているときに、非常に頻繁に起こります。 アルゴリズムの動作のため、オーバーフィッティングの罠にはまらないようにするのがどれほど厄介か想像がつくでしょう!
さらに、予測モデルがこの異常な動作を示す根本的な理由を見つけることができない場合、かなり気が重くなることがあります。 しかし、これらの機械学習の概念の背後にある直感についてはほとんど語られることはありません。 8070>
アンダーフィットとオーバーフィットを理解するために例を挙げましょう
これらの概念を実世界の例を使って説明したいと思います。 多くの人が理論的な側面について話しますが、それだけでは不十分だと感じています。
では、大学時代に戻って考えてみましょう。

生徒Aは、数学が嫌いな生徒に似ているとしましょう。 彼女は授業で教えられていることに興味がないので、教授や教授が教えている内容にあまり注意を払いません。

学生 B について考えてみましょう。彼は最も競争力のある学生で、重要な概念に焦点を当てるのではなく、授業で教えられている一つ一つの問題を記憶することに焦点を当てます。 基本的に、彼は問題解決アプローチを学ぶことに興味がありません。

最後に、理想的な学生 C がいます。彼女は、提示された解をただ記憶するのではなく、純粋に数学のクラスで重要な概念と問題解決アプローチを学ぶことに興味があります。

私たちはみな経験から教室で何が起こっているかを理解しています。 教授はまず講義を行い、問題やその解き方について生徒に教えます。 一日の終わりには、教授は授業で教えたことに基づいて小テストをするだけです。
障害となるのは、学校が課す学期ごとのテストです。 そこで新しい問題(未見のデータ)が出てくる。 生徒たちはこの問題を見たことがないし、確かに授業で解いたこともない。 見覚えはありませんか?
そこで、先生が一日の終わりに教室のテストを受けるとどうなるかを説明しましょう。

- 自分の世界に気を取られていた生徒Aは、単に答えを推測し、テストでは約50%の点数を獲得しました
- 一方、教室で教えられた問題を一つ一つ暗記していた生徒は、ほとんどすべての問題を記憶で答えることができ、したがってクラステストでは98%の点数を獲得しました
- 生徒Cにとっては、。 7198>
このように、ただ丸暗記している生徒の方が、無理なく点数を取っていることがよくわかります。
さて、ここからがひねりどころです。 月例テストでは、教師が授業で教えていない新しい未知の問題に直面しなければなりません。

- 生徒Aの場合、状況はあまり変わらず、今でもランダムに問題を正解している割合は~50%です。
- 生徒Bの場合、スコアが大きく下がりました。 なぜかわかりますか? それは、いつも授業で習った問題を暗記していたのに、今回の月例テストでは見たこともないような問題が出題されたからです。 そのため、成績が大幅にダウンしてしまったのです
- 生徒Cの場合、点数はほぼ変わりませんでした。 これは、彼女が問題解決アプローチの学習に集中したため、未知の問題を解くために学んだ概念を適用することができたからです
機械学習におけるアンダーフィットとオーバーフィッティングにどう関係するか
この例が、決定木分類器の訓練とテストのスコアで遭遇した問題にどう関係しているかと思うかもしれませんが、いかがでしょう? 良い質問ですね!
それでは、この例と先ほどお見せした決定木分類器の結果を結びつけてみましょう。

まず、クラスワークとクラステストはそれぞれ学習データと学習データそのものに対する予測に類似しています。 一方、学期テストは、モデルを学習する前に取っておいたデータからのテストセット(実際の機械学習プロジェクトでは未見のデータ)を表します。
さて、先ほど紹介した決定木分類器を思い出してください。 訓練セットでは満点でしたが、テストセットでは苦戦しました。 先ほど説明した学生の例と比較すると、この分類器は、訓練セットの各質問を記憶しようとした学生 B との類似性を確立します。
同様に、決定木分類器は、訓練データから各ポイントを学習しようとしますが、テストセットで新しいデータ ポイントに遭遇すると急激に苦しくなります。 8070>

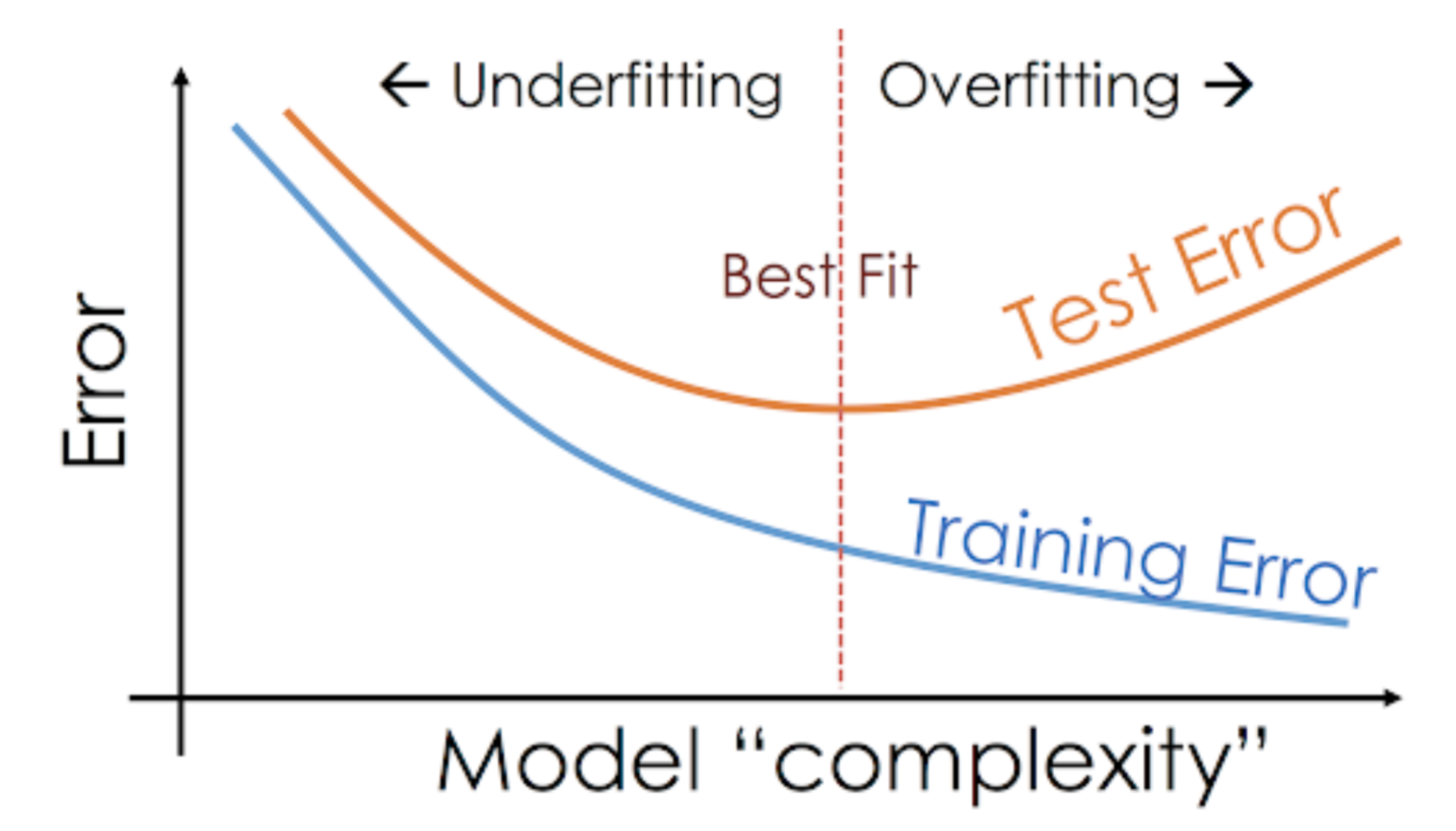
このように、任意のモデルがトレーニング データでは良好なパフォーマンスを示しているが、テスト セットではパフォーマンスが大幅に低下するという状況を、オーバーフィット モデルと呼びます。 これらのモデルは非常に複雑な関係を学習することができ、その結果、オーバーフィッティングが発生する可能性があります。 下のグラフはこの概念を要約したものです。
一方、テストセットと学習セットでモデルのパフォーマンスが低い場合、それをアンダーフィッティングモデルと呼びます。 このような状況の例としては、非線形のデータに対して線形回帰モデルを構築することです。