

Provocarea subajustarea și supraajustarea în învățarea automată
În mod inevitabil vă veți confrunta cu această întrebare la un interviu cu un cercetător de date:
Puteți explica ce este subajustarea și supraajustarea în contextul învățării automate? Descrieți-o într-un mod pe care chiar și o persoană non-tehnică îl va înțelege.
Capacitatea dvs. de a explica acest lucru într-o manieră non-tehnică și ușor de înțeles ar putea foarte bine să decidă asupra potrivirii dvs. pentru rolul de om de știință a datelor!
Inclusiv atunci când lucrăm la un proiect de învățare automată, ne confruntăm adesea cu situații în care ne confruntăm cu diferențe neașteptate de performanță sau de rată de eroare între setul de antrenament și setul de testare (așa cum se arată mai jos). Cum poate un model să aibă performanțe atât de bune pe setul de instruire și la fel de slabe pe setul de testare?

Acest lucru se întâmplă foarte frecvent ori de câte ori lucrez cu modele predictive bazate pe arbori. Din cauza modului în care funcționează algoritmii, vă puteți imagina cât de complicat este să evitați să cădeți în capcana supraadaptării!
În plus, poate fi destul de descurajant atunci când nu reușim să găsim motivul subiacent pentru care modelul nostru predictiv prezintă acest comportament anormal.
Iată experiența mea personală – întrebați orice om de știință de date experimentat despre acest lucru și, de obicei, începe să vorbească despre o serie de termeni fanteziste precum supraadaptare, subadaptare, părtinire și varianță. Dar prea puțin vorbește cineva despre intuiția din spatele acestor concepte de învățare automată. Haideți să rectificăm acest lucru, da?
Să luăm un exemplu pentru a înțelege Underfitting vs. Overfitting
Vreau să explic aceste concepte folosind un exemplu din lumea reală. O mulțime de oameni vorbesc despre unghiul teoretic, dar eu cred că nu este suficient – trebuie să vizualizăm cum funcționează de fapt underfitting și overfitting.
Așa că, să ne întoarcem la zilele noastre de facultate pentru acest lucru.

Considerăm o clasă de matematică formată din 3 studenți și un profesor.
Acum, în orice clasă, putem împărți în linii mari studenții în 3 categorii. Vom vorbi despre ei unul câte unul.

Să spunem că elevul A seamănă cu un elev căruia nu-i place matematica. Nu este interesat de ceea ce se predă în clasă și, prin urmare, nu acordă prea multă atenție profesorului și conținutului pe care îl predă.

Să luăm în considerare elevul B. El este cel mai competitiv elev care se concentrează pe memorarea fiecărei întrebări predate în clasă în loc să se concentreze asupra conceptelor cheie. Practic, el nu este interesat să învețe abordarea de rezolvare a problemelor.

În cele din urmă, îl avem pe elevul ideal C. Este pur și simplu interesat să învețe conceptele cheie și abordarea de rezolvare a problemelor la ora de matematică, mai degrabă decât să memoreze pur și simplu soluțiile prezentate.

Cunoaștem cu toții din experiență ce se întâmplă într-o clasă. Profesorul ține mai întâi prelegeri și îi învață pe elevi despre probleme și cum să le rezolve. La sfârșitul zilei, profesorul pur și simplu dă un test pe baza a ceea ce a predat în clasă.
Obstacolul vine în testele semestriale3 pe care le stabilește școala. Aici apar întrebări noi (date nevăzute). Elevii nu au mai văzut aceste întrebări și cu siguranță nu le-au rezolvat în clasă. Vă sună cunoscut?
Așa că haideți să discutăm ce se întâmplă atunci când profesorul dă un test în clasă la sfârșitul zilei:

- Elevul A, care era distras în lumea lui, pur și simplu a ghicit răspunsurile și a obținut aproximativ 50% din punctaj la test
- Pe de altă parte, elevul care a memorat fiecare întrebare predată în clasă a reușit să răspundă aproape la fiecare întrebare din memorie și, prin urmare, a obținut 98% din punctaj la testul din clasă
- Pentru elevul C:
- , ea a rezolvat de fapt toate întrebările folosind abordarea de rezolvare a problemelor învățate în clasă și a obținut un punctaj de 92%
Elevul A, care a fost distras în lumea lui, pur și simplu a ghicit răspunsurile și a obținut aproximativ 50% din punctaj la test
Potem deduce clar că elevul care pur și simplu memorează totul obține un punctaj mai bun fără prea mari dificultăți.
Acum, iată întorsătura. Să ne uităm și la ce se întâmplă în timpul testului lunar, când elevii trebuie să se confrunte cu noi întrebări necunoscute, care nu sunt predate în clasă de către profesor.

- În cazul elevului A, lucrurile nu s-au schimbat prea mult și el încă răspunde la întâmplare la întrebări corect în ~50% din cazuri.
- În cazul elevului B, scorul său a scăzut semnificativ. Puteți ghici de ce? Acest lucru se datorează faptului că el a memorat întotdeauna problemele care au fost predate în clasă, dar acest test lunar conținea întrebări pe care nu le-a mai văzut niciodată. Prin urmare, performanța sa a scăzut semnificativ
- În cazul elevului C, scorul a rămas mai mult sau mai puțin același. Acest lucru se datorează faptului că s-a concentrat pe învățarea abordării de rezolvare a problemelor și, prin urmare, a reușit să aplice conceptele pe care le-a învățat pentru a rezolva întrebările necunoscute
Cum se leagă acest exemplu de subadaptarea și supraadaptarea în învățarea automată?
S-ar putea să vă întrebați cum se leagă acest exemplu de problema pe care am întâlnit-o în timpul scorurilor de formare și testare a clasificatorului arbore de decizie? Bună întrebare!
Așa că, haideți să lucrăm la conectarea acestui exemplu cu rezultatele clasificatorului arbore de decizie pe care vi le-am arătat mai devreme.

În primul rând, lucrarea de clasă și testul de clasă seamănă cu datele de instruire și, respectiv, cu predicția asupra datelor de instruire propriu-zise. Pe de altă parte, testul semestrial reprezintă setul de teste din datele noastre pe care le ținem deoparte înainte de a antrena modelul nostru (sau datele nevăzute într-un proiect de învățare automată din lumea reală).
Acum, amintiți-vă clasificatorul nostru cu arbore de decizie pe care l-am menționat mai devreme. Acesta a dat un scor perfect pe setul de antrenament, dar s-a luptat cu setul de testare. Comparând acest lucru cu exemplele de studenți pe care tocmai le-am discutat, clasificatorul stabilește o analogie cu studentul B care a încercat să memoreze fiecare întrebare din setul de instruire.
În mod similar, clasificatorul nostru de arbore de decizie încearcă să învețe fiecare punct din datele de instruire, dar suferă radical atunci când întâlnește un nou punct de date în setul de testare. Nu este capabil să generalizeze bine.

Această situație în care un anumit model are performanțe prea bune pe datele de instruire, dar performanțele scad semnificativ pe setul de testare se numește model supraadaptat.
De exemplu, modelele neparametrice, cum ar fi arborii de decizie, KNN și alți algoritmi bazați pe arbori, sunt foarte predispuși la supraadaptare. Aceste modele pot învăța relații foarte complexe care pot duce la supraadaptare. Graficul de mai jos rezumă acest concept:
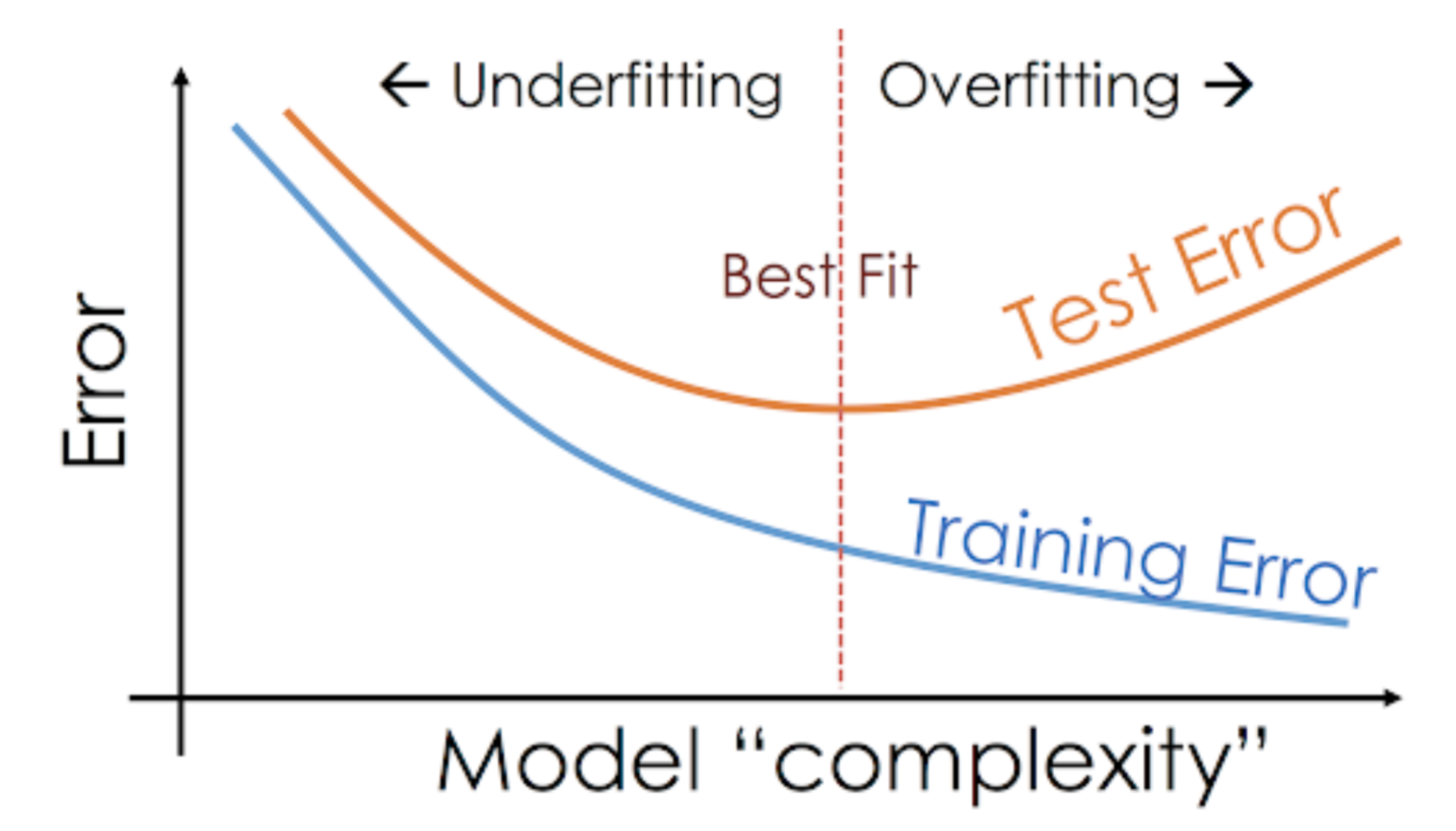
Pe de altă parte, dacă modelul are performanțe slabe pe setul de testare și pe setul de antrenament, atunci se numește un model subadaptat. Un exemplu al acestei situații ar fi construirea unui model de regresie liniară pe date neliniare.

.