

La sfida di Underfitting e Overfitting in Machine Learning
Ti troverai inevitabilmente di fronte a questa domanda in un colloquio per data scientist:
Puoi spiegare cosa sono underfitting e overfitting nel contesto del machine learning? Descrivilo in un modo che anche una persona non tecnica possa capire.
La tua capacità di spiegarlo in un modo non tecnico e facile da capire potrebbe decidere la tua idoneità al ruolo di scienziato dei dati!
Anche quando stiamo lavorando a un progetto di apprendimento automatico, spesso ci troviamo di fronte a situazioni in cui incontriamo prestazioni inaspettate o differenze nel tasso di errore tra il set di allenamento e quello di test (come mostrato di seguito). Come può un modello performare così bene sul training set e altrettanto male sul test set?

Questo succede molto spesso quando lavoro con modelli predittivi basati su alberi. A causa del modo in cui funzionano gli algoritmi, potete immaginare quanto sia difficile evitare di cadere nella trappola dell’overfitting!
Inoltre, può essere abbastanza scoraggiante quando non siamo in grado di trovare la ragione di fondo per cui il nostro modello predittivo sta mostrando questo comportamento anomalo.
Ecco la mia esperienza personale – chiedete a qualsiasi scienziato di dati esperto di questo, in genere iniziano a parlare di una serie di termini fantasiosi come Overfitting, Underfitting, Bias e Varianza. Ma poco si parla dell’intuizione dietro questi concetti di apprendimento automatico. Rimediamo, che ne dite?
Facciamo un esempio per capire Underfitting vs. Overfitting
Voglio spiegare questi concetti usando un esempio del mondo reale. Un sacco di gente parla dell’angolo teorico, ma sento che non è abbastanza – abbiamo bisogno di visualizzare come funzionano effettivamente l’underfitting e l’overfitting.
Perciò, torniamo ai nostri giorni al college per questo.

Considera una classe di matematica composta da 3 studenti e un professore.
Ora, in qualsiasi classe, possiamo dividere gli studenti in 3 categorie. Parleremo di loro uno per uno.

Diciamo che lo studente A assomiglia ad uno studente che non ama la matematica. Non è interessato a ciò che viene insegnato in classe e quindi non presta molta attenzione al professore e al contenuto che sta insegnando.

Prendiamo in considerazione lo studente B. È lo studente più competitivo che si concentra sulla memorizzazione di ogni singola domanda insegnata in classe invece di concentrarsi sui concetti chiave. Fondamentalmente, non è interessato ad imparare l’approccio alla soluzione dei problemi.

Infine, abbiamo lo studente ideale C. È puramente interessato ad imparare i concetti chiave e l’approccio alla soluzione dei problemi nella lezione di matematica piuttosto che memorizzare semplicemente le soluzioni presentate.

Tutti noi sappiamo per esperienza cosa succede in un’aula. Il professore prima fa lezione e insegna agli studenti i problemi e come risolverli. Alla fine della giornata, il professore fa semplicemente un quiz basato su ciò che ha insegnato in classe.
L’ostacolo arriva nei test del semestre3 che la scuola stabilisce. È qui che vengono fuori nuove domande (dati non visti). Gli studenti non hanno visto queste domande prima e certamente non le hanno risolte in classe. Vi suona familiare?
Perciò, discutiamo di cosa succede quando l’insegnante fa un test in classe alla fine della giornata:

- Lo studente A, che era distratto nel suo mondo, ha semplicemente indovinato le risposte e ha ottenuto circa il 50% dei voti nel test
- D’altra parte, lo studente che ha memorizzato ogni singola domanda insegnata in classe è stato in grado di rispondere a memoria a quasi tutte le domande e quindi ha ottenuto il 98% dei voti nel test in classe
- Per lo studente C, ha effettivamente risolto tutte le domande usando l’approccio di problem-solving che ha imparato in classe e ha ottenuto il 92%
Possiamo chiaramente dedurre che lo studente che semplicemente memorizza tutto ottiene un punteggio migliore senza molte difficoltà.
Ora ecco il colpo di scena. Guardiamo anche cosa succede durante il test mensile, quando gli studenti devono affrontare nuove domande sconosciute che non sono state insegnate in classe dall’insegnante.

- Nel caso dello studente A, le cose non sono cambiate molto e lui risponde ancora casualmente alle domande correttamente ~50% delle volte.
- Nel caso dello studente B, il suo punteggio è sceso notevolmente. Puoi indovinare perché? Questo perché ha sempre memorizzato i problemi che gli sono stati insegnati in classe, ma questo test mensile conteneva domande che non aveva mai visto prima. Pertanto, il suo rendimento è sceso significativamente
- Nel caso dello studente C, il punteggio è rimasto più o meno lo stesso. Questo perché si è concentrata sull’apprendimento dell’approccio alla risoluzione dei problemi e quindi è stata in grado di applicare i concetti che ha imparato per risolvere le domande sconosciute
Come si relaziona questo con l’Underfitting e l’Overfitting nel Machine Learning?
Ti starai chiedendo come questo esempio si relaziona con il problema che abbiamo incontrato durante i punteggi di training e test del classificatore ad albero decisionale? Buona domanda!
Allora, lavoriamo per collegare questo esempio con i risultati del classificatore ad albero decisionale che ti ho mostrato prima.

In primo luogo, il lavoro di classe e il test di classe assomigliano rispettivamente ai dati di addestramento e alla previsione sui dati di addestramento stessi. D’altra parte, il test di semestre rappresenta il set di test dei nostri dati che teniamo da parte prima di addestrare il nostro modello (o i dati non visti in un progetto di apprendimento automatico del mondo reale).
Ora, ricordate il nostro classificatore ad albero decisionale che ho menzionato prima. Ha dato un punteggio perfetto sul set di allenamento, ma ha faticato con il set di test. Confrontando questo con gli esempi degli studenti che abbiamo appena discusso, il classificatore stabilisce un’analogia con lo studente B che ha cercato di memorizzare ogni singola domanda nel set di allenamento.
Similmente, il nostro classificatore ad albero decisionale cerca di imparare ogni singolo punto dai dati di allenamento ma soffre radicalmente quando incontra un nuovo punto di dati nel set di test. Non è in grado di generalizzare bene.

Questa situazione in cui un dato modello funziona troppo bene sui dati di addestramento ma le prestazioni calano significativamente sul test set è chiamata modello overfitting.
Per esempio, i modelli non parametrici come gli alberi decisionali, KNN, e altri algoritmi basati su alberi sono molto inclini all’overfitting. Questi modelli possono imparare relazioni molto complesse che possono portare all’overfitting. Il grafico qui sotto riassume questo concetto:
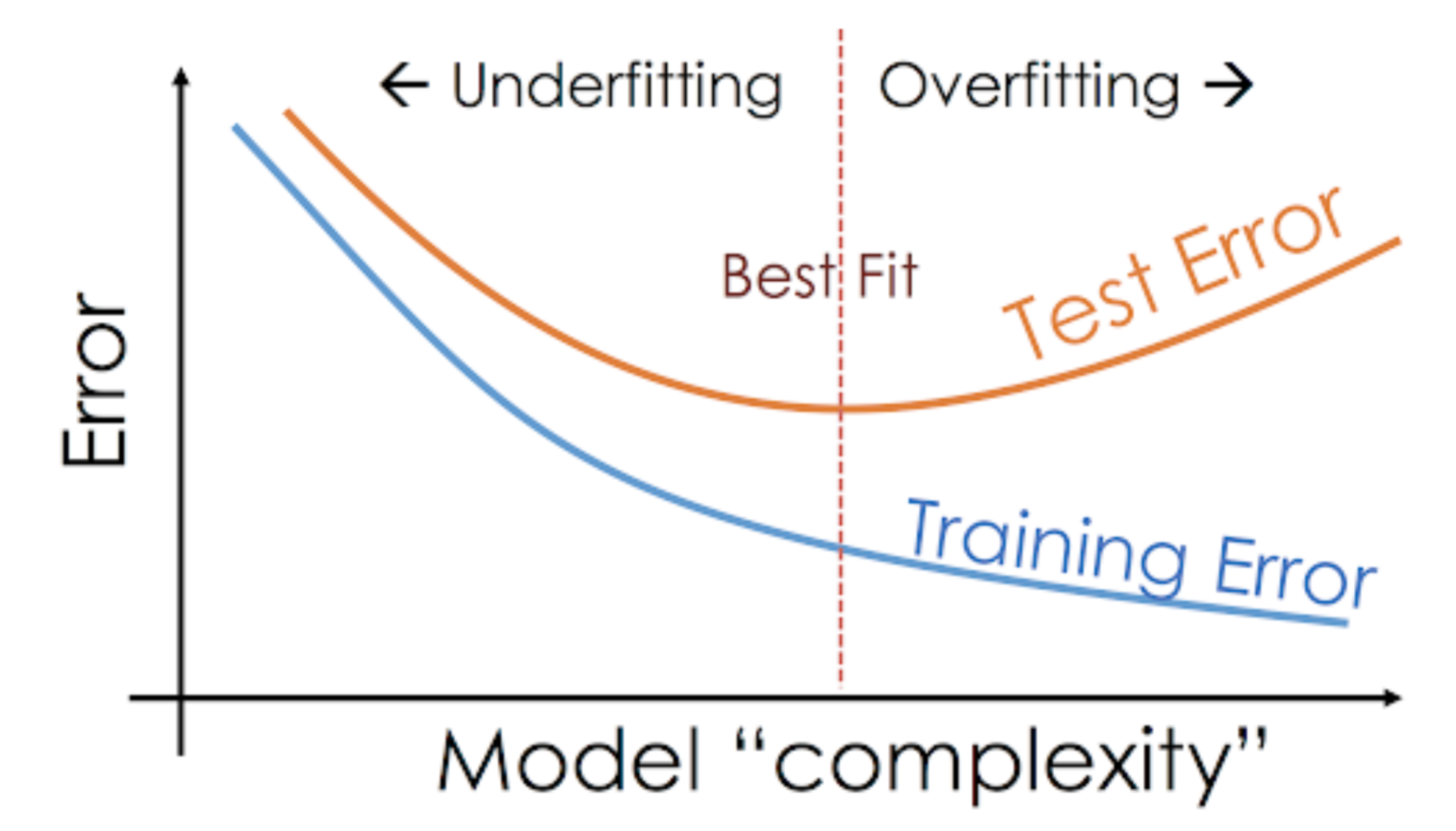
D’altra parte, se il modello ha prestazioni scarse sul test e sul train set, allora si chiama un modello underfitting. Un esempio di questa situazione sarebbe costruire un modello di regressione lineare su dati non lineari.
