

The Challenge of Underfitting and Overfitting in Machine Learning
Nieuchronnie spotkasz się z tym pytaniem podczas rozmowy kwalifikacyjnej z naukowcem danych:
Czy możesz wyjaśnić, co to jest underfitting i overfitting w kontekście uczenia maszynowego? Opisz to w sposób, który zrozumie nawet osoba nietechniczna.
Twoja zdolność do wyjaśnienia tego w sposób nietechniczny i łatwy do zrozumienia może zadecydować o Twoim dopasowaniu do roli data science!
Nawet gdy pracujemy nad projektem uczenia maszynowego, często spotykamy się z sytuacjami, w których napotykamy nieoczekiwane różnice w wydajności lub poziomie błędów między zbiorem treningowym a testowym (jak pokazano poniżej). Jak model może osiągać tak dobre wyniki na zbiorze treningowym i równie słabe na zbiorze testowym?

Takie sytuacje zdarzają się bardzo często, gdy pracuję z modelami predykcyjnymi opartymi na drzewach. Ze względu na sposób działania algorytmów, można sobie wyobrazić, jak trudno jest uniknąć wpadnięcia w pułapkę nadmiernego dopasowania!
Co więcej, może to być dość zniechęcające, gdy nie jesteśmy w stanie znaleźć podstawowego powodu, dla którego nasz model predykcyjny wykazuje to anomalne zachowanie.
Oto moje osobiste doświadczenie – zapytaj jakiegokolwiek doświadczonego naukowca danych o to, zazwyczaj zaczynają mówić o jakimś zestawie wymyślnych terminów, takich jak nadmierne dopasowanie, niedopasowanie, skośność i wariancja. Ale mało kto mówi o intuicji stojącej za tymi pojęciami uczenia maszynowego. Poprawmy to, dobrze?
Let’s Take an Example to Underfitting vs. Overfitting
Chcę wyjaśnić te pojęcia używając przykładu z prawdziwego świata. Wiele osób mówi o teoretycznym kącie, ale czuję, że to nie wystarczy – musimy zwizualizować, jak underfitting i overfitting faktycznie działa.
Więc, wróćmy do naszych czasów w college’u dla tego.

Rozważmy klasę matematyczną składającą się z 3 studentów i profesora.
Teraz, w każdej klasie, możemy ogólnie podzielić studentów na 3 kategorie. Będziemy o nich mówić po kolei.

Powiedzmy, że uczeń A przypomina ucznia, który nie lubi matematyki. Nie jest zainteresowany tym, co jest nauczane w klasie i dlatego nie zwraca zbytniej uwagi na profesora i treści, których uczy.

Zastanówmy się nad studentem B. Jest on najbardziej konkurencyjnym studentem, który skupia się na zapamiętywaniu każdego pytania nauczanego w klasie, zamiast skupiać się na kluczowych pojęciach. Zasadniczo nie jest zainteresowany uczeniem się podejścia do rozwiązywania problemów.

Wreszcie mamy idealnego studenta C. Jest ona całkowicie zainteresowana uczeniem się kluczowych pojęć i podejścia do rozwiązywania problemów w klasie matematycznej, a nie tylko zapamiętywaniem przedstawionych rozwiązań.

Wszyscy wiemy z doświadczenia, co dzieje się w klasie. Profesor najpierw wygłasza wykłady i uczy studentów o problemach i sposobach ich rozwiązywania. Na koniec dnia, profesor po prostu bierze quiz na podstawie tego, czego nauczył w klasie.
Przeszkoda pojawia się w semestrze3 testy, które szkoła ustanawia. Tu pojawiają się nowe pytania (niewidziane dane). Uczniowie nie widzieli tych pytań wcześniej i z pewnością nie rozwiązywali ich w klasie. Brzmi znajomo?
Przedyskutujmy więc, co się dzieje, gdy nauczyciel przeprowadza klasówkę na koniec dnia:

- Uczeń A, który był rozproszony w swoim własnym świecie, po prostu zgadywał odpowiedzi i uzyskał około 50% ocen w teście
- Z drugiej strony, uczeń, który zapamiętał każde pytanie nauczane w klasie, był w stanie odpowiedzieć na prawie każde pytanie z pamięci i dlatego uzyskał 98% ocen w teście klasowym
- W przypadku ucznia C, faktycznie rozwiązała wszystkie pytania przy użyciu podejścia do rozwiązywania problemów, którego nauczyła się w klasie i uzyskała 92%
Możemy jasno wywnioskować, że uczeń, który po prostu zapamiętuje wszystko, uzyskuje lepsze wyniki bez większych trudności.
Teraz następuje zwrot akcji. Przyjrzyjmy się również temu, co dzieje się podczas miesięcznego testu, kiedy uczniowie muszą zmierzyć się z nowymi, nieznanymi pytaniami, których nauczyciel nie nauczył ich na zajęciach.

- W przypadku ucznia A, sprawy nie zmieniły się zbytnio i nadal losowo odpowiada on na pytania poprawnie ~50% czasu.
- W przypadku ucznia B, jego wynik znacznie spadł. Czy domyślasz się dlaczego? To dlatego, że zawsze zapamiętywał problemy, które były nauczane na zajęciach, ale ten miesięczny test zawierał pytania, których nigdy wcześniej nie widział. Dlatego jego wyniki znacznie się pogorszyły
- W przypadku studentki C, jej wynik pozostał mniej więcej taki sam. To dlatego, że skupiła się na nauce podejścia do rozwiązywania problemów i dlatego była w stanie zastosować poznane koncepcje do rozwiązania nieznanych pytań
How Does This Relate to Underfitting and Overfitting in Machine Learning?
Możesz się zastanawiać, jak ten przykład odnosi się do problemu, który napotkaliśmy podczas trenowania i testowania wyników klasyfikatora drzewa decyzyjnego? Dobre pytanie!
Popracujmy więc nad połączeniem tego przykładu z wynikami klasyfikatora drzewa decyzyjnego, które pokazałem Ci wcześniej.

Po pierwsze, praca klasowa i test klasowy przypominają odpowiednio dane szkoleniowe i predykcję nad samymi danymi szkoleniowymi. Z drugiej strony, test semestralny reprezentuje zestaw testowy z naszych danych, które odkładamy na bok przed trenowaniem naszego modelu (lub niewidziane dane w prawdziwym projekcie uczenia maszynowego).
Teraz, przypomnij sobie nasz klasyfikator drzewa decyzyjnego, o którym wspomniałem wcześniej. Dał on doskonały wynik na zestawie treningowym, ale zmagał się z zestawem testowym. Porównując to do przykładów studentów, które właśnie omówiliśmy, klasyfikator ustanawia analogię do studenta B, który próbował zapamiętać każde pytanie w zestawie szkoleniowym.
Podobnie, nasz klasyfikator drzewa decyzyjnego próbuje nauczyć się każdego punktu z danych szkoleniowych, ale cierpi radykalnie, gdy napotyka nowy punkt danych w zestawie testowym. Nie jest w stanie dobrze go uogólnić.

Ta sytuacja, w której dany model radzi sobie zbyt dobrze na danych treningowych, ale jego wydajność spada znacząco na zbiorze testowym, jest nazywana modelem przepasowanym.
Na przykład, modele nieparametryczne, takie jak drzewa decyzyjne, KNN i inne algorytmy oparte na drzewach są bardzo podatne na przepasowanie. Modele te mogą uczyć się bardzo złożonych relacji, które mogą powodować przepasowanie. Poniższy wykres podsumowuje to pojęcie:
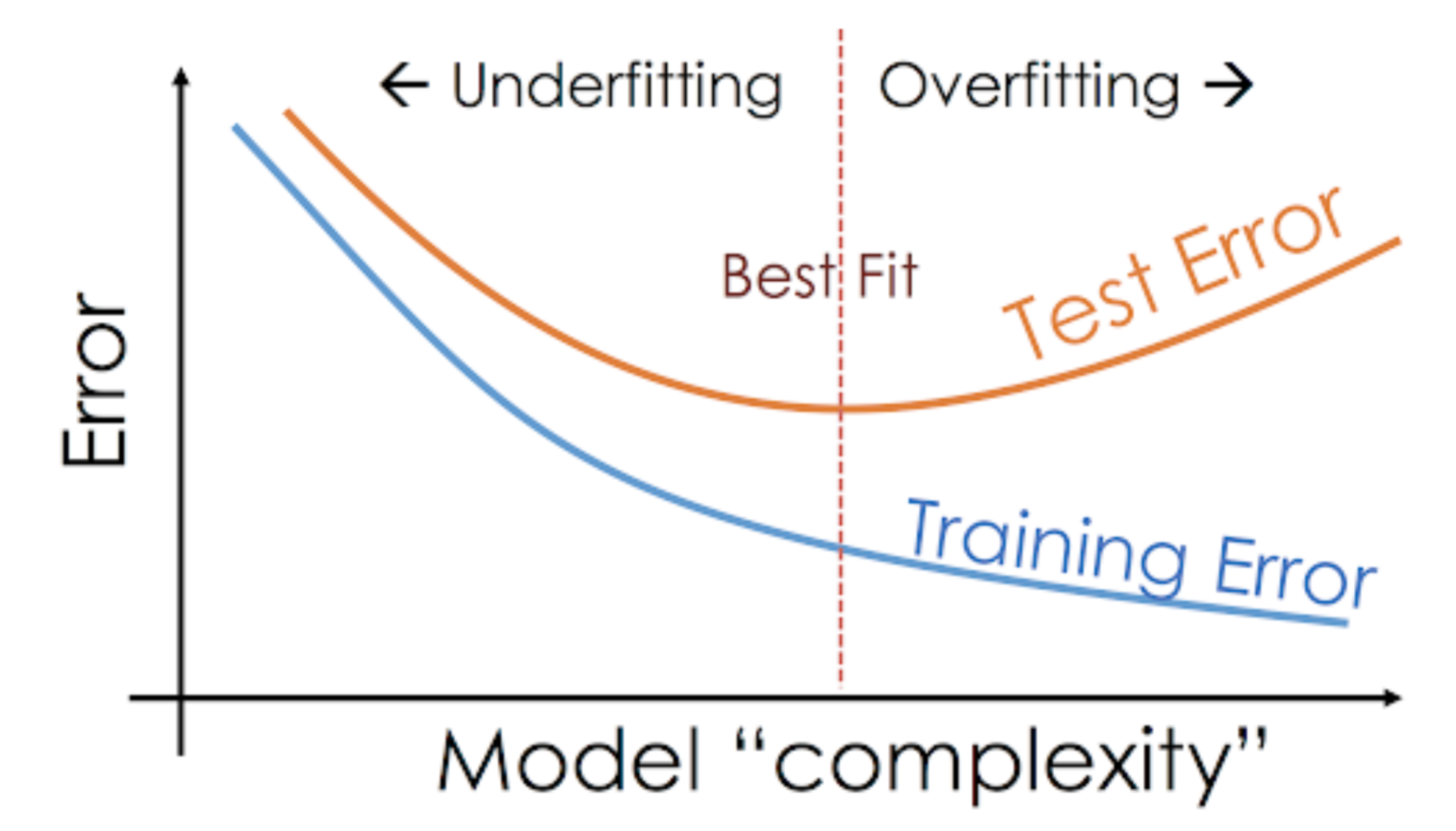
Z drugiej strony, jeśli model osiąga słabe wyniki na zbiorze testowym i szkoleniowym, wtedy nazywamy go modelem niedopasowanym. Przykładem takiej sytuacji może być budowanie modelu regresji liniowej na danych nieliniowych.

.