
- Få tillgång till de bästa ML-projekten
- Maskininlärningsprojekt för nybörjare 2021
- Säljprognoser med hjälp av Walmart-dataset
- BigMart Sales Prediction ML Project
- Musikrekommendationssystem. Projekt
- Human Activity Recognition using Smartphone Dataset
- Stock Prices Predictor using TimeSeries
- Predicting Wine Quality using Wine Quality Dataset
- MNIST Klassificering av handskrivna siffror
- Lär dig att bygga rekommendationssystem med Movielens-dataset
- Boston Housing Price Prediction ML Project
- Analys av känslor i sociala medier med hjälp av Twitter Dataset
- Iris Flowers Classification ML Project
- Optimering av detaljhandelspriser med hjälp av maskininlärning
- Analys av förutsägelse av kundförluster
- 1. Försäljningsprognoser med hjälp av Walmart-dataset
- 2. BigMart Sales Prediction ML Project – Lär dig mer om oövervakade maskininlärningsalgoritmer
- Music Recommendation System Project
- Human Activity Recognition using Smartphone Dataset
- Stock Prices Predictor using TimeSeries
- Förutsägelse av vinkvalitet med hjälp av Wine Quality Dataset
- MNIST Handwritten Digit Classification
- Lär dig att bygga rekommendationssystem med Movielens Dataset
- Boston Housing Price Prediction ML Project
- Social Media Sentiment Analysis using Twitter Dataset
- Iris Flowers Classification ML Project- Lär dig om övervakade algoritmer för maskininlärning
- Maskininlärningsprojekt för nybörjare med källkod i Python för 2021
- 12) ML-projekt för optimering av detaljhandelspriser – Dynamisk prissättning Maskininlärningsmodell för en dynamisk marknad
- 13) Customer Churn Prediction Analysis Using Ensemble Techniques in Machine Learning
- Hur startar jag ett projekt för maskininlärning?
- 1) Första steget: Första steget är att skapa en plan för maskininlärning: Machine Learning Project Scoping
- 2) Andra steget: Data
- 3) Tredje steget – att bygga upp modellen
- 4) Fjärde steget -Model Deployment into Production
- Hur skriver du in maskininlärningsprojekt i ditt CV?
- What Next?
Få tillgång till de bästa ML-projekten
×
Senast uppdaterad: 05 mar 2021

Du vill lära dig maskininlärning men har svårt att komma igång med det. Böcker och kurser kanske inte bara räcker när det gäller maskininlärning även om de alltid ger exempel på koder och kodutdrag för maskininlärning får du inte möjlighet att implementera maskininlärning i verkliga problem och se hur dessa kodutdrag passar ihop. Det bästa sättet att komma igång med maskininlärning är att genomföra maskininlärningsprojekt på nybörjarnivå till avancerad nivå. Det är alltid bra att få inblick i hur riktiga människor börjar sin karriär inom maskininlärning genom att implementera end-to-end ML-projekt.
I det här blogginlägget kommer du att få reda på hur nybörjare som du kan göra stora framsteg när det gäller att tillämpa maskininlärning på verkliga problem med dessa fantastiska maskininlärningsprojekt för nybörjare som rekommenderas av branschexperter. ProjectPro:s branschexperter har noggrant kurerat listan över de bästa maskininlärningsprojekten för nybörjare som täcker de centrala aspekterna av maskininlärning som övervakad inlärning, oövervakad inlärning, djupinlärning och neurala nätverk. I alla dessa maskininlärningsprojekt kommer du att börja med verkliga dataset som är offentligt tillgängliga. Vi försäkrar att du kommer att finna den här bloggen absolut intressant och värd att läsa på grund av allt du kan lära dig här om de mest populära projekten för maskininlärning.
”Vilka projekt kan jag göra med maskininlärning?” Vi får ofta den här frågan från nybörjare som börjar med maskininlärning. ProjectPro:s branschexperter rekommenderar att du utforskar några spännande, coola, roliga och enkla projektidéer för maskininlärning inom olika affärsområden för att få praktisk erfarenhet av de färdigheter i maskininlärning som du har lärt dig. Vi har sammanställt en lista över innovativa och intressanta maskininlärningsprojekt med källkod för yrkesverksamma som börjar sin karriär inom maskininlärning. Dessa nybörjarprojekt om maskininlärning är en perfekt blandning av olika typer av utmaningar som man kan stöta på när man arbetar som maskininlärningsingenjör eller datavetare.
Maskininlärningsprojekt för nybörjare 2021
-
Säljprognoser med hjälp av Walmart-dataset
-
BigMart Sales Prediction ML Project
-
Musikrekommendationssystem. Projekt
-
Human Activity Recognition using Smartphone Dataset
-
Stock Prices Predictor using TimeSeries
-
Predicting Wine Quality using Wine Quality Dataset
-
MNIST Klassificering av handskrivna siffror
-
Lär dig att bygga rekommendationssystem med Movielens-dataset
-
Boston Housing Price Prediction ML Project
-
-
Iris Flowers Classification ML Project
-
Optimering av detaljhandelspriser med hjälp av maskininlärning
-
Analys av förutsägelse av kundförluster
Vi kan dyka in!

1. Försäljningsprognoser med hjälp av Walmart-dataset
Försäljningsprognoser är ett av de vanligaste användningsområdena för maskininlärning för att identifiera faktorer som påverkar försäljningen av en produkt och uppskatta framtida försäljningsvolymer. Det här maskininlärningsprojektet använder sig av Walmart-dataset som har försäljningsdata för 98 produkter från 45 försäljningsställen. Datasetet innehåller försäljning per butik, per avdelning på veckobasis. Målet med detta maskininlärningsprojekt är att prognostisera försäljningen för varje avdelning i varje försäljningsställe för att hjälpa dem att fatta bättre datadrivna beslut för kanaloptimering och lagerplanering. Den utmanande aspekten av att arbeta med Walmart-dataset är att det innehåller utvalda markdown-händelser som påverkar försäljningen och som bör beaktas.
Detta är ett av de enklaste och coolaste maskininlärningsprojekten där du kommer att bygga en prediktiv modell med hjälp av Walmart-dataset för att uppskatta antalet försäljningar som de kommer att göra i framtiden och så här går det till –
- Importera datan och utforska den för att förstå strukturen och värdena i datan – Börja med att importera en CSV-fil och utföra grundläggande utforskande dataanalys (EDA).
- Förbered data för modellering – Slå samman flera dataset och tillämpa gruppering efter funktion för att analysera data.
- Plotta en tidsseriegrafik och analysera den.
- Fit de utvecklade försäljningsprognosmodellerna till träningsdata- Skapa en ARIMA-modell för tidsserieprognoser
- Genomföra de utvecklade modellerna på testdata.
- Optimera försäljningsprognosmodellerna genom att välja viktiga funktioner för att förbättra noggrannhetspoängen.
- Använd den bästa maskininlärningsmodellen för att förutsäga nästa års försäljning.
Efter att ha arbetat med det här Kaggle maskininlärningsprojektet kommer du att förstå hur kraftfulla maskininlärningsmodeller kan göra den övergripande försäljningsprognosprocessen enkel. Återanvänd dessa maskininlärningsmodeller för försäljningsprognoser från början till slut i produktionen för att prognostisera försäljningen för alla avdelningar och butiker.
Vill du arbeta med Walmart Dataset? Få tillgång till den fullständiga lösningen för detta fantastiska maskininlärningsprojekt här – Walmart Store Sales Forecasting Machine Learning Project
2. BigMart Sales Prediction ML Project – Lär dig mer om oövervakade maskininlärningsalgoritmer
BigMarts försäljningsdataset består av försäljningsdata från 2013 för 1559 produkter på 10 olika försäljningsställen i olika städer. Målet med BigMarts ML-projekt om försäljningsprediktion är att bygga en regressionsmodell för att förutsäga försäljningen av var och en av de 1559 produkterna för följande år i vart och ett av de 10 olika BigMart-butikerna. BigMarts försäljningsdataset består också av vissa attribut för varje produkt och butik. Denna modell hjälper BigMart att förstå vilka egenskaper hos produkter och butiker som spelar en viktig roll för att öka den totala försäljningen.
Access the complete solution to this ML Project Here – BigMart Sales Prediction Machine Learning Project Solution
Music Recommendation System Project
Det här är ett av de populäraste projekten för maskininlärning och kan användas inom olika områden. Du kanske är mycket bekant med ett rekommendationssystem om du har använt någon e-handelswebbplats eller film- eller musikwebbplats. På de flesta e-handelssajter som Amazon rekommenderar systemet produkter som du kan lägga till i din varukorg när du går till kassan. På samma sätt visar systemet på Netflix eller Spotify liknande filmer eller låtar som du kanske gillar, baserat på de filmer du har gillat. Hur gör systemet detta? Detta är ett klassiskt exempel där maskininlärning kan tillämpas.
I det här projektet använder vi datasetet från Asiens ledande musikstreamingtjänst för att bygga ett bättre musikrekommendationssystem. Vi kommer att försöka avgöra vilken ny låt eller vilken ny artist en lyssnare kan tänkas gilla baserat på deras tidigare val. Den primära uppgiften är att förutsäga chanserna för att en användare ska lyssna på en låt upprepade gånger inom en tidsram. I datasetet markeras förutsägelsen som 1 om användaren har lyssnat på samma låt inom en månad. Datasetet består av vilken låt som har hörts av vilken användare och vid vilken tidpunkt.
Vill du bygga ett rekommendationssystem – kolla in detta lösta ML-projekt här – Music Recommendation Machine Learning Project
Human Activity Recognition using Smartphone Dataset
Smartphonedataset består av inspelningar av fitnessaktivitet av 30 personer som fångats med hjälp av smartphone-aktiverade med tröghetssensorer. Målet med detta maskininlärningsprojekt är att bygga en klassificeringsmodell som exakt kan identifiera mänskliga fitnessaktiviteter. Genom att arbeta med det här maskininlärningsprojektet kommer du att förstå hur man löser problem med flera klassificeringar.
Få tillgång till källkoden för detta ML-projekt här Human Activity Recognition using Smartphone Dataset Project
Klicka här för att se en lista med 50+ lösta, projektlösningar för Big Data och maskininlärning (återanvändbar kod + videor)
Stock Prices Predictor using TimeSeries
Detta är en annan intressant projektidé för maskininlärning för datavetare/maskinininlärningsingenjörer som arbetar eller planerar att arbeta med finansområdet. En aktiekursförutsägare är ett system som lär sig om ett företags resultat och förutsäger framtida aktiekurser. Utmaningarna i samband med att arbeta med aktiekursdata är att de är mycket granulära, och dessutom finns det olika typer av data som volatilitetsindex, priser, globala makroekonomiska indikatorer, fundamentala indikatorer med mera. En bra sak med att arbeta med aktiemarknadsdata är att finansmarknaderna har kortare återkopplingscykler vilket gör det lättare för dataexperter att validera sina förutsägelser på nya data. För att börja arbeta med aktiemarknadsdata kan du plocka upp ett enkelt maskininlärningsproblem som att förutsäga prisrörelser på 6 månader baserat på fundamentala indikatorer från en organisations kvartalsrapport. Du kan ladda ner aktiemarknadsdataset från Quandl.com eller Quantopian.com. Det finns olika tidsserieprognosmetoder för att prognostisera aktiekurser, efterfrågan etc.
Kolla in det här maskininlärningsprojektet där du lär dig att avgöra vilken prognosmetod som ska användas när och hur den ska tillämpas med tidsserieprognos exempel. Aktiekursförutsägelse med hjälp av TimeSeries Project
Förutsägelse av vinkvalitet med hjälp av Wine Quality Dataset
Det är ett känt faktum att ju äldre vinet är, desto bättre är smaken. Det finns dock flera andra faktorer än ålder som ingår i certifieringen av vinets kvalitet, vilket inkluderar fysiokemiska tester som alkoholkvantitet, fast syra, flyktig syra, bestämning av densitet, pH med mera. Huvudsyftet med detta maskininlärningsprojekt är att bygga en maskininlärningsmodell för att förutsäga kvaliteten på viner genom att utforska deras olika kemiska egenskaper. Datasetetet för vinkvalitet består av 4898 observationer med 11 oberoende och 1 beroende variabel.
Få tillgång till den fullständiga lösningen för detta maskininlärningsprojekt här – Wine Quality Prediction in R
MNIST Handwritten Digit Classification
Djupinlärning och neurala nätverk spelar en viktig roll vid bildigenkänning, automatisk textgenerering och till och med självkörande bilar. För att börja arbeta inom dessa områden måste du börja med ett enkelt och hanterbart dataset som MNIST-dataset. Det är svårt att arbeta med bilddata över platta relationsdata och som nybörjare föreslår vi att du kan plocka upp och lösa MNIST Handwritten Digit Classification Challenge. MNIST-datasetet är för litet för att rymmas i datorns minne och är nybörjarvänligt. Men handskriven sifferigenkänning kommer att utmana dig.
Gör ditt klassiska inträde i att lösa bildigenkänningsproblem genom att få tillgång till den fullständiga lösningen här – MNIST Handwritten Digit Classification Project
Lär dig att bygga rekommendationssystem med Movielens Dataset
Från Netflix till Hulu har behovet av att bygga ett effektivt system för att rekommendera filmer fått större betydelse med tiden, med den ökande efterfrågan på skräddarsytt innehåll från moderna konsumenter. Ett av de mest populära dataset som finns på webben för nybörjare som vill lära sig att bygga rekommendationssystem är Movielens Dataset som innehåller cirka 1 000 209 filmbedömningar av 3 900 filmer gjorda av 6 040 Movielens-användare. Du kan börja arbeta med den här datamängden genom att bygga en world-cloud-visualisering av filmtitlar för att bygga ett filmrekommendationssystem.
Fri tillgång till lösta kodexempel finns här (dessa är färdiga att använda för dina ML-projekt)
Boston Housing Price Prediction ML Project
Boston House Prices Dataset består av priser på hus på olika platser i Boston. Datasetetet består också av information om områden med annan verksamhet än detaljhandel (INDUS), brottslighet (CRIM), ålder på personer som äger ett hus (AGE) och flera andra attribut (datasetetet har totalt 14 attribut). Boston Housing dataset kan laddas ner från UCI Machine Learning Repository. Målet med detta maskininlärningsprojekt är att förutsäga försäljningspriset för ett nytt hem genom att tillämpa grundläggande begrepp för maskininlärning på uppgifterna om bostadspriser. Det här datasetet är för litet med 506 observationer och anses vara en bra start för nybörjare inom maskininlärning för att få igång sin praktiska övning i regressionskoncept.
Rekommenderad läsning – 15+ Data Science Projects for Beginners
Social Media Sentiment Analysis using Twitter Dataset
Sociala medieplattformar som Twitter, Facebook, YouTube, Reddit genererar enorma mängder big data som kan utvinnas på olika sätt för att förstå trender, allmänna känslor och åsikter. Data från sociala medier har i dag blivit relevant för varumärkesbyggande, marknadsföring och affärsverksamhet som helhet. En sentimentanalysator lär sig om olika känslor bakom ett ”innehållsstycke” (kan vara en IM, ett e-postmeddelande, en tweet eller något annat inlägg i sociala medier) genom maskininlärning och förutspår samma sak med hjälp av artificiell intelligens.Twitterdata anses vara en definitiv ingångspunkt för nybörjare för att öva på problem med maskininlärning för sentimentanalys. Genom att använda Twitter-dataset kan man få en fängslande blandning av tweets innehåll och andra relaterade metadata som hashtaggar, retweets, plats, användare med mera som banar väg för insiktsfulla analyser. Twitter-datasetet består av 31 962 tweets och är 3 MB stort. Med hjälp av Twitterdata kan du ta reda på vad världen säger om ett ämne, oavsett om det handlar om filmer, känslor kring det amerikanska valet eller något annat trendigt ämne som att förutsäga vem som vinner fotbolls-VM 2018. Genom att arbeta med Twitter-dataset kan du förstå de utmaningar som är förknippade med datautvinning i sociala medier och även lära dig mer om klassificerare på djupet. Det främsta problemet som du kan börja arbeta med som nybörjare är att bygga en modell för att klassificera tweets som positiva eller negativa.
Fri tillgång till löst kod Python- och R-exempel finns här (dessa är färdiga att använda för dina datavetenskap- och ML-projekt)
Iris Flowers Classification ML Project- Lär dig om övervakade algoritmer för maskininlärning
Det här är ett av de enklaste projekten för maskininlärning, eftersom Iris Flowers är det enklaste datamaterialet för maskininlärning i klassificeringslitteraturen. Detta problem för maskininlärning kallas ofta för maskininlärningens ”Hello World”. Datamängden har numeriska attribut och nybörjare inom maskininlärning måste ta reda på hur man laddar in och hanterar data. Datasetetet för iris är litet och passar lätt in i minnet och kräver inga speciella transformationer eller skalning till att börja med.
Iris Dataset kan laddas ner från UCI ML Repository – Download Iris Flowers Dataset
Målet med det här maskininlärningsprojektet är att klassificera blommorna till en av de tre arterna – virginica, setosa eller versicolor, baserat på längden och bredden på kronblad och sepalblad.
Fri tillgång till lösta maskininlärning Python och R kod exempel kan hittas här (dessa är färdiga att använda för dina projekt)
Maskininlärningsprojekt för nybörjare med källkod i Python för 2021
12) ML-projekt för optimering av detaljhandelspriser – Dynamisk prissättning Maskininlärningsmodell för en dynamisk marknad
Prissättning tävlingar växer non-stop i alla vertikala branscher och optimering av priserna är nyckeln till att hantera vinsterna effektivt för alla företag. Att identifiera ett rimligt prisintervall och göra en justering av prissättningen av produkter för att öka försäljningen samtidigt som vinstmarginalerna hålls optimala har alltid varit en stor utmaning inom detaljhandeln. Det snabbaste sättet för detaljhandlare att säkerställa den högsta avkastningen idag samtidigt som de optimerar prissättningen är att utnyttja kraften i maskininlärning för att bygga effektiva prissättningslösningar. E-handelsjätten Amazon var en av de tidigaste användarna av maskininlärning för optimering av detaljhandelspriser, vilket bidrog till dess fantastiska tillväxt från 30 miljarder 2008 till cirka 1 biljon 2019.

Image Credit: spd. group
100+ Datasets for Machine Learning Projects Curated Specially For You
Lösningen på maskininlärningsproblemet för optimering av detaljhandelspriser kräver att man tränar en maskininlärningsmodell som kan prissätta produkter automatiskt på samma sätt som de skulle prissättas av människor. Maskininlärningsmodeller för optimering av detaljhandelspriser tar in historiska försäljningsdata, olika egenskaper hos produkterna och andra ostrukturerade data, t.ex. bilder och textinformation, för att lära sig prissättningsreglerna utan mänskligt ingripande, vilket hjälper detaljhandlare att anpassa sig till en dynamisk prismiljö för att maximera intäkterna utan att förlora på vinstmarginalerna. Maskininlärningsalgoritmen för optimering av detaljhandelspriser bearbetar ett oändligt antal prissättningsscenarier för att välja det optimala priset för en produkt i realtid genom att ta hänsyn till tusentals latenta relationer inom en produkt.
Kolla in det här coola maskininlärningsprojektet om optimering av detaljhandelspriser för att få en djupdykning i verklig analys av försäljningsdata för ett café, där du kommer att bygga en end-to-end maskininlärningslösning som automatiskt föreslår de rätta produktpriserna.
13) Customer Churn Prediction Analysis Using Ensemble Techniques in Machine Learning
Kunderna är ett företags största tillgång och att behålla kunderna är viktigt för alla företag för att öka intäkterna och bygga en långvarig meningsfull relation med kunderna. Dessutom är kostnaden för att skaffa en ny kund fem gånger högre än kostnaden för att behålla en befintlig kund. Kundförluster är ett av de mest kända problemen i näringslivet när kunder eller abonnenter slutar att göra affärer med en tjänst eller ett företag. Helst slutar de att vara betalande kunder. En kund sägs vara avstängd om det har gått en viss tid sedan kunden senast interagerade med företaget.
Att identifiera om och när en kund kommer att avstängas och snabbt leverera användbar information som syftar till att behålla kunderna är avgörande för att minska avstängningen. Det är inte möjligt för våra hjärnor att komma före kundbortfallet för miljontals kunder, det är här som maskininlärning kan hjälpa till. Maskininlärning ger effektiva metoder för att identifiera de underliggande faktorerna för kundbortfall och proscriptiva verktyg för att åtgärda dem. Algoritmer för maskininlärning spelar en viktig roll i den proaktiva hanteringen av churn eftersom de avslöjar beteendemönster hos kunder som redan har slutat använda tjänsterna eller köpa produkter. Sedan kontrollerar modellerna för maskininlärning beteendet hos de befintliga kunderna mot sådana mönster för att identifiera potentiella churners.

Image Credit. :gallery.azure.ai
Men hur ska man börja med att lösa problemet med maskininlärning för att förutsäga kundernas churn rate? Precis som alla andra maskininlärningsproblem måste datavetare eller maskininlärningsingenjörer samla in och förbereda data för bearbetning. För att alla metoder för maskininlärning ska vara effektiva är det vettigt att konstruera data i rätt format. Feature Engineering är den mest kreativa delen av modellen för maskininlärning för churn prediktion där dataspecialister använder sin erfarenhet, företagskontext, domänkunskap om data och kreativitet för att skapa funktioner och skräddarsy maskininlärningsmodellen för att förstå varför kundavgång sker i ett specifikt företag.
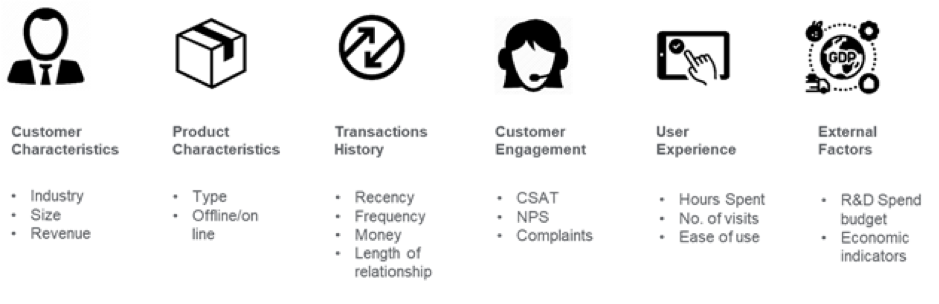
Bildkredit: medium.com
Till exempel, i bankbranschen, kan två konton som har samma månatliga slutsaldo vara svåra att skilja ut för churn prediktion. Men med hjälp av feature engineering kan man lägga till en tidsdimension till dessa data så att ML-algoritmerna kan särskilja om det månatliga slutsaldot har avvikit från vad som vanligtvis förväntas av en kund. Indikatorer som vilande konton, ökande uttag, användningstrender, utflöde av nettosaldo under de senaste dagarna kan vara tidiga varningssignaler på att en kund har slutat. Dessa interna uppgifter i kombination med externa uppgifter, t.ex. konkurrenters erbjudanden, kan hjälpa till att förutsäga kundbortfall. Efter att ha identifierat funktionerna är nästa steg att förstå varför churns inträffar i ett affärssammanhang och ta bort de funktioner som inte är starka prediktorer för att minska dimensionaliteten.
Kolla in det här maskininlärningsprojektet från början till slut med källkod i Python om Customer Churn Prediction Analysis using Ensemble Learning för att bekämpa churn.
Hur startar jag ett projekt för maskininlärning?
Inget projekt går framåt med framgång utan gedigen planering, och maskininlärning är inget undantag. Att bygga upp ditt första maskininlärningsprojekt är faktiskt inte så svårt som det verkar, förutsatt att du har en solid planeringsstrategi. För att starta ett ML-projekt måste man följa en omfattande strategi från början till slut – från projektavgränsning till modellutnyttjande och hantering i produktion Här är vår syn på de grundläggande stegen i en projektplan för maskininlärning för att se till att du får ut det mesta av varje unikt projekt –
1) Första steget: Första steget är att skapa en plan för maskininlärning: Machine Learning Project Scoping
Förut ska du förstå vilka affärskrav som ställs på ML-projektet. När man startar ett ML-projekt är det grundläggande steget att välja det relevanta affärsanvändningsfallet som modellen för maskininlärning ska byggas för att hantera. Att välja rätt användningsfall för maskininlärning och utvärdera dess ROI är viktigt för att lyckas med ett projekt för maskininlärning.
2) Andra steget: Data
Data är livsnerven i alla modeller för maskininlärning och det är omöjligt att träna en modell för maskininlärning utan data. Datasteget i livscykeln för ett maskininlärningsprojekt är en process i fyra steg –
-
Datakrav – Det är viktigt att förstå vilken typ av data som kommer att behövas, datans format, datakällorna och datakällornas krav på efterlevnad.
-
Datainsamling – Med hjälp av databasadministratörer, dataarkitekter eller utvecklare måste du sätta upp en datainsamlingsstrategi för att extrahera data från de ställen där den finns inom organisationen eller från andra tredjepartsleverantörer.
-
Explorativ dataanalys – Det här steget innebär i princip att validera datakraven för att se till att du har rätt data, att datan är i gott skick och fri från fel.
-
Dataförberedelse – Det här steget innebär att du förbereder datan för att den ska kunna användas av algoritmer för maskininlärning. Felkorrigering, funktionsutveckling, kodning till dataformat som maskinerna kan förstå och korrigering av anomalier är de uppgifter som ingår i dataförberedelsen.
3) Tredje steget – att bygga upp modellen
Avhängigt av projektets karaktär kan det här steget ta några dagar eller månader. I modelleringsfasen fattar du ett beslut om vilken algoritm för maskininlärning som ska användas och börjar träna modellen på data. Det är viktigt att förstå vilket mått på noggrannhet, fel och korrekthet som en maskininlärningsmodell bör hålla sig till vid val av modell. När du har tränat modellen utvärderar du den på valideringsdata för att analysera dess prestanda och förhindra överanpassning. Modellutvärdering är ett kritiskt steg eftersom om en modell fungerar perfekt med historiska data och ger dålig prestanda med framtida data är den oanvändbar.
4) Fjärde steget -Model Deployment into Production
Detta steg innebär att man distribuerar mjukvara eller app till slutanvändare så att nya data kan flöda in i modellen för maskininlärning för ytterligare inlärning. Det räcker inte att distribuera modellen för maskininlärning, du måste också se till att modellen för maskininlärning fungerar som förväntat. Du bör träna om din modell på de nya levande produktionsdata för att säkerställa dess noggrannhet eller prestanda – detta är modellinställning. Modelljustering innebär också att man måste validera modellen för att se till att den inte avviker eller blir partisk.
Hur skriver du in maskininlärningsprojekt i ditt CV?
Erfarenhet från den verkliga världen förbereder dig för slutlig framgång som inget annat. Ju mer du som nybörjare inom maskininlärning kan skaffa dig erfarenhet i realtid av att arbeta med maskininlärningsprojekt, desto bättre förberedd kommer du att vara för att ta de hetaste jobben i detta årtionde. Att få ett maskininlärningsjobb efter att ha avslutat utbildningen i datavetenskap eller att bli framgångsrik som datavetare beror på din förmåga att sälja dig själv. Nästa steg för att få ett toppjobb som maskininlärningsingenjör eller datavetare är att bygga upp en enastående portfölj för att visa upp din förmåga att tillämpa tekniker för maskininlärning för dina potentiella arbetsgivare. Att arbeta med intressanta ML-projekt är ett utmärkt sätt att få igång din karriär som maskininlärningsingenjör eller datavetare på företag. Arbetsgivare vill se vilken typ av projekt med anknytning till datavetenskap och maskininlärning du har arbetat med för att utvärdera omfattningen av din förmåga att bedriva datavetenskap och maskininlärning. Att lyfta fram några roliga, coola och intressanta exempel på projekt inom datavetenskap och maskininlärning i ditt CV kommer att väga tyngre än att berätta hur mycket du vet. Så här kan du lägga till häftiga projekt i ditt CV om maskininlärning –
- Du kan nämna maskininlärningsprojekten direkt efter avsnittet om arbetslivserfarenhet i CV:et om maskininlärning.
- Följ en sekventiell ordning för numrering tillsammans med titeln på de projekt som du har arbetat med.
- Projektstiteln bör följas av en liten kortfattad beskrivning av datasetet och problemformulering.
- Nämn de verktyg och tekniker för maskininlärning som du använde för att slutföra ett projekt.
- Sist men inte minst, i din portfölj/resumé ska du länka varje maskininlärningsprojekt till GitHub, personlig webbplats eller blogg för att få en djupgående förståelse för dina prestationer.
Oavsett om du vill bygga upp en stark portfölj för maskininlärning eller om du vill öva upp de analytiska färdigheter som du lärde dig i din utbildning i datavetenskap, så har vi allt för dig. Många nybörjare inom maskininlärning är osäkra på var de ska börja, vilka maskininlärningsprojekt de ska göra, vilka verktyg, tekniker och ramverk för maskininlärning de ska använda. Vi har gjort det till en bekymmersfri uppgift för nybörjare inom datavetenskap och maskininlärning genom att sammanställa en lista med intressanta idéer för maskininlärningsprojekt tillsammans med deras lösningar. Dessa idéer för maskininlärningsprojekt är hämtade från populära Kaggle-datavetenskapliga utmaningar och är ett utmärkt sätt att lära sig maskininlärning. Den här listan över projekt är ett perfekt sätt att sätta maskininlärningsprojekt på ditt CV. Rätt inställning, vilja att lära sig och en hel del datautforskning är allt som krävs för att förstå lösningen på projekt om datavetenskap och maskininlärning. Du kan utforska 50+ projekt inom datavetenskap och ML baserat på den uppsättning färdigheter, verktyg och tekniker som du behöver lära dig.
Innan du börjar med ditt projekt är det bra att ha tillgång till ett bibliotek med kodexempel för projekt för maskininlärning. Så närhelst du fastnar i projektet kan du använda dessa lösta exempel för att komma loss.
Access Data Science and Machine Learning Project Code Examples
What Next?
Man kan bli en mästare i maskininlärning endast med mycket övning och experimenterande. Att ha teoretiska kunskaper hjälper säkert, men det är tillämpningen som hjälper till att göra framsteg mest. Ingen teoretisk kunskap kan ersätta praktisk övning. Det hjälper dock om du först bekantar dig med de ovan listade innovativa maskininlärningsprojekten.
Om du är nybörjare och nybörjare på maskininlärning så kommer arbetet med maskininlärningsprojekt som utformats av branschexperter på ProjectPro att göra några av de bästa investeringarna av din tid. Dessa projekt har utformats för nybörjare för att hjälpa dem att snabbt förbättra sina färdigheter i tillämpad maskininlärning samtidigt som de får en chans att utforska intressanta användningsfall inom olika områden – detaljhandel, finans, försäkring, tillverkning med mera. Så om du vill njuta av att lära dig maskininlärning, hålla dig motiverad och göra snabba framsteg är ProjectPro:s intressanta ML-projekt något för dig. Lägg dessutom till dessa maskininlärningsprojekt i din portfölj och landa ett toppjobb med högre lön och givande förmåner.

Klicka här för att se en lista med 50+ lösta, genomgående projektlösningar inom maskininlärning och Big Data
|
PREVIOUS |
NEXT |