
Vid: Aaron Bertrand | Uppdaterad: 2019-12-03 | Kommentarer (1) | Relaterad: För flera år sedan bloggade jag om hur du kan minska påverkan på transaktionsloggen genom att dela upp delete-operationer i bitar. Istället för att ta bort 100 000 rader i en stor transaktion kan du ta bort 100 eller 1 000 eller något annat godtyckligt antal rader i taget i flera mindre transaktioner i en slinga. Förutom att minska påverkan på loggboken kan du lindra långvariga blockeringar. Vid den tiden hade SSD-enheterna precis börjat ta fart och nyare tekniker som Clustered Columnstore Indexes, Delayed Durability och Accelererated Database Recovery fanns ännu inte. Så jag tänkte att det kanske var dags för en uppdatering för att ge en bättre bild av hur det här fungerar i SQL Server2019.
Lösning
Det är inte alltid det enda svaret att radera stora delar av en tabell. Om du raderar 95 % av en tabell och behåller 5 % kan det faktiskt vara snabbare att flytta de rader du vill behålla till en ny tabell, ta bort den gamla tabellen och byta namn på den nya eller kopiera ut de rader du vill behålla, truncera tabellen och sedan kopiera in dem igen. Men även när rensningen är så mycket större än behållningen är detta inte alltid möjligt på grund av andra begränsningar för tabellen, SLA:er och andra faktorer.
Och om det visar sig att du måste ta bort rader vill du minimera effekten på transaktionsloggen och hur operationerna påverkar resten av arbetsbelastningen.Chunking-ansatsen är inte en ny eller ny idé, men den kan fungera bra tillsammans med några av de här nyare teknikerna, så vi testar dem i en rad olika kombinationer.
För att ställa upp har vi flera konstanter som kommer att vara sanna för varje test:
- SQL Server 2019 RC1, med fyra kärnor och 32 GB RAM (max serverminne =28 GB)
- Tabell med 10 miljoner rader
- Starta om SQL Server efter varje test (för att återställa minne, buffertar, och plancache)
- Restore a backup that had stats already updated and auto-stats disabled(to prevent any triggered stats updates from interfering with delete operations)
Vi har också många variabler som kommer att ändras per test:
Detta kommer att ge 864 unika tester, och du kan tro att jag kommer att automatisera alla dessa permutationer.
Och de mätvärden som vi kommer att mäta:
- Alltid
- Genomsnittlig/spetsad CPU-användning
- Genomsnittlig/spetsad minnesanvändning
- Transaktionslogganvändning/filtillväxt
- Databasfilanvändning, storlek på versionslager (vid användning av Accelerated DatabaseRecovery)
- Delta radgruppstorlek (vid användning av Columnstore)
Källtabell
Först återställde jag en kopia av AdventureWorks (AdventureWorks2017.bak, för att vara specifik). För att skapa en tabell med 10 miljoner rader gjorde jag en kopia av Sales.SalesOrderDetail, med en egen identitetskolumn, och lade till en fyllnadskolumn bara för att ge varje rad lite mer kött och minska sidtätheten:
CREATE TABLE dbo.SalesOrderDetailCopy
(
SalesOrderDetailID int IDENTITY,
SalesOrderID int,
CarrierTrackingNumber nvarchar(25),
OrderQty smallint,
ProductID int,
SpecialOfferID int,
UnitPrice money,
UnitPriceDiscount money,
LineTotal numeric(38,6),
rowguid uniqueidentifier,
ModifiedDate datetime,
filler char(50) NOT NULL DEFAULT ''
);
GO
För att generera de 10 000 000 000 raderna infogade jag sedan 100 000 rader åt gången och gjorde infogningen 100 gånger:
INSERT dbo.SalesOrderDetailCopy
(
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
)
SELECT TOP(100000)
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
FROM Sales.SalesOrderDetail;GO 100
Jag skapade inga index för tabellen; beroende på lagringsmetoden kommer jag att skapa ett nytt klusterindex (columnstore hälften av gångerna) efter att databasen återställts som en del av varje test.
Automatisering av tester
När tabellen med 10 miljoner rader existerade ställde jag in några alternativ, säkerhetskopierade databasen, säkerhetskopierade loggen två gånger och säkerhetskopierade sedan databasen igen (så att loggen skulle ha minsta möjliga använda utrymme när den återställdes):
Nästan skapade jag en Control-databas, där jag skulle lagra de lagrade procedurerna som skulle köra testerna och tabellerna som skulle innehålla testresultaten (bara start- och sluttid för varje test) och prestandamått som registrerades under alla testerna.
Det tog några försök att fånga in permutationerna av alla de 864 tester som jag ville utföra, men det slutade med detta:
Som väntat infogades 864 rader med alla dessa kombinationer.
Nästan skapade jag en lagrad procedur för att fånga upp den uppsättning mätvärden som beskrivits tidigare.Jag övervakar också instansen medSentryOne SQL Sentry, så det kommer säkert att finnas annan intressant information tillgänglig där, men jag ville också fånga de viktiga detaljerna utan att använda några tredjepartsverktyg. Här är proceduren, som gör allt för att producera alla mätvärden för en given tidsstämpel i en enda rad:
Jag lade den lagrade proceduren i ett jobbsteg och startade det. Du kanske vill använda en annan fördröjning än tre sekunder – det finns en avvägning mellan kostnaden för insamlingen och fullständigheten av uppgifterna som kanske lutar mer åt det ena än det andra hållet för dig.
Slutligt skapade jag proceduren som skulle innehålla all logik för att bestämma exakt vad som ska göras med kombinationen av parametrar för varje enskilt test.Detta tog återigen flera iterationer, men slutprodukten ser ut på följande sätt:
Det är mycket som händer där, men den grundläggande logiken är följande:
- Hämta de testspecifika uppgifterna (TestID och alla parametrar) från dbo.Teststable
- Giv SQL Server en kick genom att göra en sp_configure-ändring och rensa buffersand plan cache
- Restaurera en ren kopia av AdventureWorks, med alla 10 miljoner rader intakta,och inga index
- Ändra databasens alternativ beroende på parametrarna för det aktuella testet
- Skapa antingen ett klustrad columnstore index eller ett klustrad B-tree index
- Uppdatera statistiken för tabellen manuellt, bara för att vara säker
- Logga att vi har startat testet
- Bestäm hur många iterationer av slingan vi behöver och hur många rader som ska raderas i varje iteration
- Inuti slingan:
- Bestäm om vi behöver starta en transaktion i den här iterationen
- Gör raderingen
- Bestäm om vi behöver bekräfta transaktionen i den här iterationen
- Bestäm om vi behöver kontrollera/backupera loggboken i den här iterationen
- Efter slingan, loggar vi att testet är avslutat och bekräftar eventuella ocommitterade transaktioner
För att faktiskt köra testet vill jag inte göra detta i Management Studio (inte ens på samma virtuella maskin), på grund av all utdata, extra trafik och resursanvändning.Jag skapade en lagrad procedur och lade detta i ett jobb också:
Det tog mycket längre tid än vad jag är bekväm med att erkänna. En del av det berodde på att jag ursprungligen hade inkluderat ett 0,1 %-test för rowperloopsom i vissa fall tog flera timmar. Så jag tog bort dessa från tabellen några dagar senare, och kan lätt säga: om du tar bort 1 000 000 rader är det högst osannolikt att det är ett optimalt val att ta bort 1 000 rader åt gången, oavsett andra variabler:

(Även om det verkar vara en anomali i förhållande till de flesta andra tester, så slår jag vad om att det inte skulle gå mycket fortare än att ta bort en rad eller 10 rader åt gången. Och i själva verket var det långsammare än att radera halva eller större delen av tabellen i alla andra scenarier.)
Prestationsresultat
Efter att ha kastat resultaten från 0,1 %-testerna lade jag in resten i en andrametriktabell med varaktigheterna inlästa:
Jag var tvungen att använda en yttre fogning på metriktabellen eftersom vissa tester kördes så snabbt att det inte fanns tillräckligt med tid för att fånga in några data. Detta innebär att det för vissa av de snabbare testerna inte kommer att finnas någon korrelation med andra prestandadetaljer än hur snabbt de sprang.
Därefter började jag leta efter trender och anomalier. Först kontrollerade jag varaktighet och CPU baserat på om Delayed Durability (DD) och/eller Accelerated Database Recovery (ADR) var aktiverade:
Resultat (med avvikelser markerade):

Det verkar som om den totala varaktigheten förbättras, i genomsnitt ungefär lika mycket, när något av alternativen är aktiverat (eller båda – och när båda är aktiverade är toppen lägre). Det tycks finnas ett utfall i fråga om varaktighet för enbart ADR som inte påverkade genomsnittet (det här specifika testet innebar att 9 000 000 rader, 90 000 rader åt gången, raderades i FULL recovery, på en rowstore-tabell). CPU-utfallet för DD påverkade inte heller genomsnittet – detta specifika exempel gällde radering av 1 000 000 000 rader på en gång i en columnstore-tabell.
Hur är det med de övergripande skillnaderna mellan rowstore och columnstore?
Resultat:

Columnstore är i genomsnitt 20 % långsammare, men krävde mindre minne. Jag ville också se hur datafilen och loggfilen påverkas när det gäller storlek och användning:
Resultat:

För dagens maskinvara verkar det inte vara lika fördelaktigt att ta bort delar av data på samma sätt som förr, åtminstone inte när det gäller varaktighet. De 18 snabbaste resultaten här, och 72 av de 100 snabbaste, var tester där alla rader raderades i ett svep, vilket avslöjas av denna fråga:
Resultat:
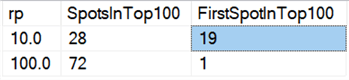
Och om vi tittar på medelvärden över alla data, som i denna fråga:
Vi ser att det går snabbare att radera alla rader på en gång, oavsett om vi raderar 10 %, 50 % eller 90 %, än att dela upp raderingarna i bitar på något sätt (återigen i genomsnitt):
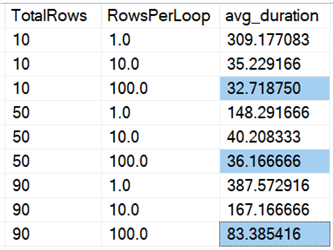
I diagramform:
(Observera att om vi tar bort den max_durationoutlier på 6 062 sekunder som vi identifierade tidigare, sjunker den första kolumnen från 309 sekunder till 162 sekunder.)
Även i bästa fall är det fortfarande 33, 36 eller 83 sekunder som adelete körs och potentiellt blockerar alla andra, och detta utan att ta hänsyn till andra mätbara effekter som minne, loggfil, CPU och så vidare. Varaktighet bör absolut inte vara det enda kriteriet; det råkar bara vara det första (och ibland enda) som folk tittar på. Den här testhärvan var tänkt att visa att du kan och bör fånga upp flera andra mätvärden också, och resultaten visar att outliers kan komma varifrån som helst.
Med den här testhärvan som modell kan du konstruera dina egna tester som är mer fokuserade på de begränsningar och möjligheter som finns i din miljö. Jag har inte angripit mätvärdena från alla möjliga vinklar, eftersom det är många permutationer, men jag kommer att behålla den här databasen. Så om det finns andra sätt som du vill se data uppdelade på, säg till i kommentarerna nedan, så ska jag se vad jag kan göra. Be mig bara inte att köra alla tester igen.
Caveats
Det här tar inte hänsyn till samtidig arbetsbelastning, effekten av tabellbegränsningar som utländska nycklar, förekomsten av triggers och en mängd andra möjliga scenarier.En annan sak att testa (eventuellt i ett framtida tips) är att ha flera jobb som interagerar med samma tabell under hela operationen, och mäta saker som blockeringsperioder, väntetyper och väntetider, och mäta i vilka situationer den ena aktivitetsuppsättningen har en mer dramatisk påverkan på den andra uppsättningen.
Nästa steg
Läs vidare för relaterade tips och andra resurser:
- CRUD-operationer i SQL Server
- Skillnader mellan Delete och Truncate i SQL Server
- Släcka historiska data från en stor SQL Server DatabaseTable med hög samtidighet
- Bryt stora delete-operationer i bitar
- SQL Server Clustered and Nonclustered Columnstore Index Example
- Skjuten hållbarhet i SQL Server 2014
- Skjuten hållbarhet vid rensning av data
- Snabbare databasåterställning i SQL Server 2019
Sist uppdaterad: 2019-12-03


Om författaren
 Aaron Bertrand (@AaronBertrand) är en passionerad tekniker med branscherfarenhet som går tillbaka till Classic ASP och SQL Server 6.5. Han är chefredaktör för den prestandarelaterade bloggen SQLPerformance.com och bloggar även på sqlblog.org.
Aaron Bertrand (@AaronBertrand) är en passionerad tekniker med branscherfarenhet som går tillbaka till Classic ASP och SQL Server 6.5. Han är chefredaktör för den prestandarelaterade bloggen SQLPerformance.com och bloggar även på sqlblog.org.Se alla mina tips
- Mer SQL Server DBA Tips…