
Bästa Python-bibliotek för maskininlärning och djupinlärning
Det finns många språk att välja mellan, men Python är ett av de mest utvecklarvänliga programmeringsspråken för maskininlärning och djupinlärning, och det har stöd av ett stort antal bibliotek som passar alla dina användningsfall och projekt.

● TensorFlow
Revolutionen är här! Välkommen till TensorFlow 2.0.
TensorFlow är ett snabbt, flexibelt och skalbart maskininlärningsbibliotek med öppen källkod för forskning och produktion.
TensorFlow är ett av de bästa biblioteken som finns tillgängliga för att arbeta med maskininlärning i Python. TensorFlow, som erbjuds av Google, gör det enkelt för både nybörjare och proffs att bygga ML-modeller.
Med TensorFlow kan du skapa och träna ML-modeller inte bara på datorer utan även på mobila enheter och servrar med hjälp av TensorFlow Lite och TensorFlow Serving som erbjuder samma fördelar men för mobila plattformar och högpresterande servrar.
Några av de väsentliga områden inom ML och DL där TensorFlow glänser är:
● Hantering av djupa neurala nätverk
● Behandling av naturligt språk
● Partiell differentialekvation
● Abstraktionsmöjligheter
● Bild-, text- och taligenkänning
● Mödosamt samarbete mellan idéer och kod
Kärnuppgift: För att förstå hur man utför en specifik uppgift i TensorFlow kan du läsa TensorFlow-tutorials.
● Keras
Keras är ett av de mest populära neurala nätverksbiblioteken för Python med öppen källkod. Keras utformades ursprungligen av en Google-ingenjör för ONEIROS, en förkortning för Open-Ended Neuro Electronic Intelligent Robot Operating System, och fick snart stöd i TensorFlows kärnbibliotek vilket gjorde det tillgängligt ovanpå TensorFlow. Keras innehåller flera av de byggstenar och verktyg som behövs för att skapa ett neuralt nätverk, t.ex:
● Neurala lager
● Aktiverings- och kostnadsfunktioner
● Mål
● Batch-normalisering
● Dropout
● Pooling
.

Keras utökar användbarheten av TensorFlow med dessa ytterligare funktioner för ML och DL-programmering. Med ett hjälpsamt community och en dedikerad Slack-kanal är det enkelt att få support. Stöd för konvolutionella och återkommande neurala nätverk finns också tillsammans med vanliga neurala nätverk. Du kan också hänvisa till andra exempelmodeller i Keras and Computer Vision class från Stanford.
Keras Cheat Sheet : https://s3.amazonaws.com/assets.datacamp.com/blog_assets/Keras_Cheat_Sheet_Python.pdf
Kärnuppgift: Bygg djupinlärningsmodeller
Keras –
● PyTorch
PyTorch är ett av de få biblioteken för maskininlärning för Python och har utvecklats av Facebook. Förutom Python har PyTorch även stöd för C++ med sitt C++-gränssnitt om du är intresserad av det. PyTorch anses vara en av de främsta utmanarna i tävlingen om att vara det bästa ramverket för maskininlärning och djupinlärning, men får konkurrens av TensorFlow. Du kan hänvisa till PyTorch-tutorials för andra detaljer.
Några av de viktigaste funktionerna som skiljer PyTorch från TensorFlow är:
● Tensorberäkning med möjlighet till accelererad bearbetning via Graphics Processing Units
● Lätt att lära sig, använda och integrera med resten av Pythons ekosystem
● Stöd för neurala nätverk som byggs på ett bandbaserat auto diff-system
De olika modulerna som PyTorch har med sig och som hjälper till att skapa och träna neurala nätverk:
● Tensorer – torch.Tensor

● Optimizers – torch.optim module
● Neural Networks – nn module
● Autograd
Pros: mycket anpassningsbar, används ofta inom forskning om djupinlärning
Cons: färre NLP-abstraktioner, inte optimerad för snabbhet
Kärnuppgift: Utveckla och träna modeller för djupinlärning
Keras vs Tensorflow vs PyTorch | Deep Learning Frameworks Comparison
● Scikit-learn
Scikit-learn är ett annat aktivt använt maskininlärningsbibliotek för Python. Det innehåller enkel integration med olika ML-programmeringsbibliotek som NumPy och Pandas. Scikit-learn har stöd för olika algoritmer som t.ex:
● Klassificering
● Regression
● Klusterindelning
● Dimensionalitetsreduktion
● Modellval
● Förbehandling
Byggd kring idén om att vara lätt att använda men ändå vara flexibel, Scikit-learn fokuserar på datamodellering och inte på andra uppgifter som laddning, hantering, manipulering och visualisering av data. Det anses vara tillräckligt tillräckligt för att användas som ett ML-system från början till slut, från forskningsfasen till driftsättning. För en djupare förståelse av scikit-learn kan du läsa Scikit-learn tutorials.
Kärnuppgift: Modellering
Lär dig Scikit-Learn-
● Pandas
Pandas är ett dataanalysbibliotek i Python och används främst för datamanipulering och analys. Det kommer in i bilden innan datamängden förbereds för träning. Pandas gör det enkelt för programmerare av maskininlärning att arbeta med tidsserier och strukturerade multidimensionella data. Några av de fantastiska funktionerna i Pandas när det gäller hantering av data är följande:
● Dataset reshaping and pivoting
● Merging and joining of datasets
● Handling of missing data and data alignment
● Various indexing options such as Hierarchical axis indexing, Fancy indexing
● Alternativ för filtrering av data

Pandas använder sig av DataFrames, vilket bara är en teknisk term för en tvådimensionell representation av data genom att erbjuda programmerare DataFrame-objekt.
Kärnuppgift: Datahantering och analys
Google Trends – Pandas intresse över tid

.
● NLTK
NLTK står för Natural Language Toolkit och är ett Pythonbibliotek för arbete med behandling av naturliga språk. Det anses vara ett av de mest populära biblioteken för att arbeta med data om mänskligt språk. NLTK erbjuder enkla gränssnitt tillsammans med ett brett utbud av lexikala resurser som FrameNet, WordNet, Word2Vec och flera andra för programmerare. Några av höjdpunkterna i NLTK är följande:
● Sökning av nyckelord i dokument
● Tokenisering och klassificering av texter
● Röst- och handskriftsigenkänning
● Lemmatisering och stamning av ord

NLTK och dess paketpaket anses vara ett pålitligt val för studenter, ingenjörer, forskare, lingvister och industrier som arbetar med språk.
Core Task: Textbehandling
● Spark MLlib
MLlib är Apache Spark’s skalbara maskininlärningsbibliotek
Spark MLlib är ett maskininlärningsbibliotek som utvecklas av Apache och som gör det möjligt att enkelt skala dina beräkningar. Det är enkelt att använda, snabbt, lätt att konfigurera och erbjuder smidig integration med andra verktyg. Spark MLlib blev omedelbart ett bekvämt verktyg för att utveckla algoritmer och tillämpningar för maskininlärning.
De verktyg som Spark MLlib tillför är:
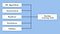
Spark Mllib Machine Learning Tools
Några populära algoritmer och API:er som programmerare som arbetar med maskininlärning med hjälp av Spark MLlib kan använda är:
● Regression
● Klustring
● Optimering
● Dimensionsreduktion
● Klassificering
● Grundläggande statistik
● Feature Extraction
● Theano
Theano är ett kraftfullt Pythonbibliotek som möjliggör enkel definition, optimering och utvärdering av kraftfulla matematiska uttryck. Några av de funktioner som gör Theano till ett robust bibliotek för att utföra vetenskapliga beräkningar i stor skala är följande:
● Stöd för GPU:er för att prestera bättre vid tunga beräkningar jämfört med CPU:er
● Starkt integrationsstöd med NumPy
● Snabbare och stabila utvärderingar av även de knepigaste variablerna
● Möjlighet att skapa anpassad C-kod för dina matematiska operationer
Med Theano, kan du uppnå snabb utveckling av några av de mest effektiva algoritmerna för maskininlärning. Ovanpå Theano byggs några av de välkända biblioteken för djupinlärning, t.ex. Keras, Blocks och Lasagne. För mer avancerade begrepp i Theano kan du läsa Theano-handledningen.
● MXNet
Ett flexibelt och effektivt bibliotek för djupinlärning

Om djupinlärning är ett av dina expertområden, kommer MXNet att passa perfekt. MXNet används för att träna och distribuera djupa neurala nätverk och är mycket skalbar och stöder snabb modellträning. Apaches MXNet fungerar inte bara med Python utan även med en mängd andra språk, inklusive C++, Perl, Julia, R, Scala, Go och några till.
MXNets portabilitet och skalbarhet gör att du kan ta det från en plattform till en annan och skala det till de krävande behoven i ditt projekt. Några av de största namnen inom teknik och utbildning som Intel, Microsoft, MIT med flera stöder för närvarande MXNet. Amazons AWS föredrar MXNet som sitt val av föredraget ramverk för djupinlärning.
● Numpy

NumPy-biblioteket för Python koncentrerar sig på hantering av omfattande flerdimensionella data och de invecklade matematiska funktionerna som opererar på dessa data. NumPy erbjuder snabb beräkning och utförande av komplicerade funktioner som arbetar på matriser. Några av de punkter som talar för NumPy är följande:
● Stöd för matematiska och logiska operationer
● Formhantering
● Sorterings- och valmöjligheter
● Diskreta Fouriertransformationer
● Grundläggande linjär algebra och statistiska operationer
● Slumpmässiga simuleringar
● Stöd för n-dimensionella matriser
NumPy arbetar enligt ett objektorienterat tillvägagångssätt och har verktyg för att integrera C, C++ och Fortran-kod, och detta gör NumPy mycket populärt bland forskarvärlden.
Kärnuppgift: Rengöring och hantering av data
Google Trends – Numpy Interest Over Time

.
Slutsats
Python är ett verkligt fantastiskt utvecklingsverktyg som inte bara fungerar som ett allmänt-ändamål programmeringsspråk utan även tillgodoser specifika nischer i dina projekt eller arbetsflöden. Med massor av bibliotek och paket som utökar Pythons möjligheter och gör det till ett universalspråk och en perfekt lösning för alla som vill börja utveckla program och algoritmer. Med några av de moderna biblioteken för maskininlärning och djupinlärning för Python som diskuteras kort ovan kan du få en uppfattning om vad vart och ett av dessa bibliotek har att erbjuda och göra ditt val.