
Por: Aaron Bertrand | Actualizado: 2019-12-03 | Comentários (1) | Relacionado: Mais > Ajuste de Performance
Problema
Several anos atrás, eu bloguei sobre como você pode reduzir o impacto no transactionlog bybreaking operações de exclusão em pedaços. Ao invés de excluir 100.000 linhas em uma grande transação, você pode excluir 100 ou 1.000 ou algum número arbitrário de linhas de uma vez, em várias transações menores, em um loop. Além de reduzir o impacto no log, é possível oferecer alívio ao bloqueio a longo prazo. Na época, os SSDs estavam apenas captando tração, e tecnologias mais novas como os índices de Columnstore Indexes, Durabilidade Atrasada e Recuperação Acelerada de Banco de Dados ainda não existiam. Então, eu pensei que talvez fosse hora de uma atualização para dar uma imagem melhor de como isso funciona no SQL Server2019.
Solution
Apagar grandes porções de uma tabela nem sempre é a única resposta. Se você está apagando 95% de uma tabela e mantendo 5%, pode ser mais rápido mover para dentro de uma nova tabela, soltar a tabela antiga e renomear a nova, ou copiar as linhas do mantenedor, truncar a tabela, e então copiá-las de volta para dentro. Buteven quando a purga é muito maior que a keep, isto nem sempre é possível devido a outras restrições na tabela, SLAs e outros fatores.
Again, se acontecer que você tem que excluir linhas, você vai querer minimizar o impacto no log de transações e como as operações afetam o resto da carga de trabalho.a abordagem chunking não é uma idéia nova ou nova, mas pode funcionar bem com algumas dessas novas tecnologias, então vamos colocá-las à prova em uma variedade de combinações.
Para configurar, temos várias constantes que serão verdadeiras para cada teste:
- ServidorSQL 2019 RC1, com quatro núcleos e 32 GB de RAM (memória máxima do servidor =28 GB)
- 10 milhões de linhas de tabela
- Restart SQL Server após cada teste (para reiniciar a memória, buffers, e plancache)
- Restaurar uma cópia de segurança que já tinha as estatísticas actualizadas e as estatísticas automáticas desactivadas(para evitar que qualquer actualização de estatísticas desencadeada interfira com as operações de eliminação)
Temos também muitas variáveis que irão mudar por teste:
Esta irá produzir 864 testes únicos, e é melhor acreditarem que vou automatizar todas estas permutações.
E as métricas que vamos medir:
- Duração total
- Média/utilização de pico de CPU
- Média/utilização de pico de memória
- Utilização de log de transacções/crescimento de ficheiros
- Utilização de ficheiro de base de dados, tamanho da versão store (quando usando Accelerated DatabaseRecovery)
- Delta tamanho do grupo de linha (quando usando Columnstore)
Source Table
First, I restored a copy of AdventureWorks (AdventureWorks2017.bak,para ser específico). Para criar uma tabela com 10 milhões de filas, fiz uma cópia de Vendas.SalesOrderDetail,com sua própria coluna de identidade, e adicionei uma coluna de preenchimento apenas para dar a cada linha um pouco mais de carne e reduzir a densidade de páginas:
CREATE TABLE dbo.SalesOrderDetailCopy
(
SalesOrderDetailID int IDENTITY,
SalesOrderID int,
CarrierTrackingNumber nvarchar(25),
OrderQty smallint,
ProductID int,
SpecialOfferID int,
UnitPrice money,
UnitPriceDiscount money,
LineTotal numeric(38,6),
rowguid uniqueidentifier,
ModifiedDate datetime,
filler char(50) NOT NULL DEFAULT ''
);
GO
Então, para gerar as 10.000.000 linhas, inseri 100.000 linhas de cada vez, e fiz o encarte 100 vezes:
INSERT dbo.SalesOrderDetailCopy
(
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
)
SELECT TOP(100000)
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
FROM Sales.SalesOrderDetail;GO 100
Não criei nenhum índice na tabela; dependendo da abordagem de armazenamento, criarei um novo índice agrupado (coluna de armazenamento na metade do tempo) após o banco de dados ser restaurado como parte de cada teste.
Testes de Automatização
Após a tabela de 10 milhões de linhas ter existido, eu defini algumas opções, fiz backup do banco de dados,fiz backup do log duas vezes, e então fiz backup do banco de dados novamente (para que o log tivesse o menor espaço utilizado possível quando restaurado):
Próximo, criei uma base de dados de Controlo, onde guardaria os procedimentos armazenados que executariam os testes, e as tabelas que guardariam os resultados dos testes (apenas o tempo de início e fim de cada teste) e as métricas de desempenho capturadas ao longo de todos os testes.
Capturar as permutações de todos os 864 testes que eu queria realizar levou alguns testes, mas acabei com isto:
Como esperado, isto inseriu 864 linhas com todas essas combinações.
Próximo, criei um procedimento armazenado para capturar o conjunto de métricas descritas anteriormente.Também estou monitorando a instância com oSentryOne SQL Sentry, então certamente haverá alguma outra informação interessante disponível lá, mas eu também queria capturar os detalhes importantes sem o uso de nenhuma ferramenta de terceiros. Aqui está o procedimento, que sai de seu caminho toproduzir todas as métricas para um determinado timestamp em uma única linha:
Eu coloquei esse procedimento armazenado em um passo de trabalho e o iniciei. Você pode querer usar um atraso diferente de três segundos – há um trade-off entre o custo da coleta e a completude dos dados que podem ser mais de uma maneira do que de outra para você.
Finalmente, eu criei o procedimento que conteria toda a lógica para determinar exatamente o que fazer com a combinação de parâmetros para cada teste individual.Isto novamente levou várias iterações, mas o produto final é o seguinte:
Há muita coisa acontecendo lá, mas a lógica básica é esta:
- Puxa os dados específicos do teste (TestID e todos os parâmetros) do dbo.Teststable
- Dê um chute no SQL Server fazendo uma mudança de configuração sp_configure e limpando buffers e o cache do plano
- Restaurar uma cópia limpa do AdventureWorks, com todas as 10 milhões de linhas intactas,e nenhum índice
- Alterar as opções da base de dados dependendo dos parâmetros para a corrente
- Criar ou um índice agrupado de colunas ou um índice agrupado de árvores B
- Actualizar manualmente as estatísticas na tabela, só para ter certeza
- Log que iniciamos o teste
- Determinar quantas iterações do laço precisamos, e quantas filas são necessárias dentro de cada iteração
- Inside the loop:
- Determinar se precisamos iniciar uma transação nesta iteração
- Executar o delete
- Determinar se precisamos submeter a transação nesta iteração
- Determinar se precisamos fazer checkpoint / backup do log nesta iteração
- Após o loop, nós registramos que este teste está terminado, e submetemos quaisquer transações não comprometidas
>
Para realmente executar o teste, eu não quero fazer isso no Management Studio(mesmo na mesma VM), por causa de todo o output, tráfego extra, e uso de recursos.Eu criei um procedimento armazenado e coloquei isso em um trabalho também:
Que demorou muito mais do que eu me sinto confortável em admitir. Parte disso foi porque eu tinha originalmente incluído um teste de 0,1% para o rowperloop que, em alguns casos, demorou várias horas. Então eu removi esses da tabela alguns dias atrás, e posso facilmente dizer: se você está removendo 1.000.000 linhas, apagar 1.000 linhas de cada vez é altamente improvável que seja uma escolha ótima, independentemente de qualquer outra variável:

(Embora isso pareça ser uma anomalia em comparação com a maioria dos outros testes, aposto que não seria muito mais rápido do que apagar uma ou 10 linhas de cada vez. E na verdade foi mais lento que apagar metade da tabela ou a maior parte da tabela em todos os outros cenários.)
Resultados de desempenho
Após descartar os resultados dos testes de 0,1%, coloquei o resto em uma tabela de segundos com as durações carregadas:
Tive que usar uma união externa na tabela de métricas porque alguns testes correram tão rápido que não houve tempo suficiente para capturar nenhum dado. Isto significa que, para alguns dos testes mais rápidos, não haverá nenhuma correlação com outros detalhes de desempenho além de quão rápido eles correram.
Então eu comecei a procurar por tendências e anomalias. Primeiro, eu verifiquei a duração e a CPU com base em se a Durabilidade Atrasada (DD) e/ou Recuperação Acelerada de Base de Dados (ADR) estavam ativadas:
Resultados (com as anomalias destacadas):

Parece que a duração total é melhorada, em média, mais ou menos a mesma quantidade, quando uma das opções é ativada (ou ambas – e quando ambas estão ativadas, o pico é menor). Parece haver um outlier de duração só para o ADR que não afetou a média (este teste específico envolveu apagar 9.000.000 linhas, 90.000 linhas de cada vez, em recuperação COMPLETO, em uma tabela de loja em linha). O outlier da CPU para DD também não afetou a média – este exemplo específico foi deletar 1.000.000 linhas, todas de uma vez, em uma tabela de columnstore.
E que tal diferenças gerais comparando rowstore e columnstore?
Resultados:

Columnstore é 20% mais lento, em média, mas requer menos memória. Eu também queria ver o impacto no tamanho e uso do arquivo de dados e log:
Resultados:

Finalmente, no hardware de hoje, apagar em pedaços não parece ter os mesmos benefícios que tinha antes, pelo menos em termos de duração. Os 18 fastestresults aqui, e 72 dos 100 mais rápidos, foram testes onde todas as linhas foram deletadas em um tiro, revelados por esta consulta:
Resultados:
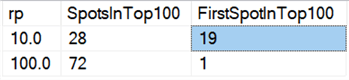
E se olharmos as médias em todos os dados, como nesta consulta:
Vemos que apagar todas as linhas de uma vez, independentemente de estarmos apagando10%, 50%, ou 90%, é mais rápido do que apagar um pedaço (novamente, em média):
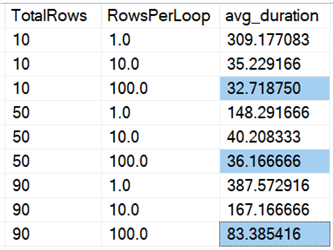
Em forma de gráfico:
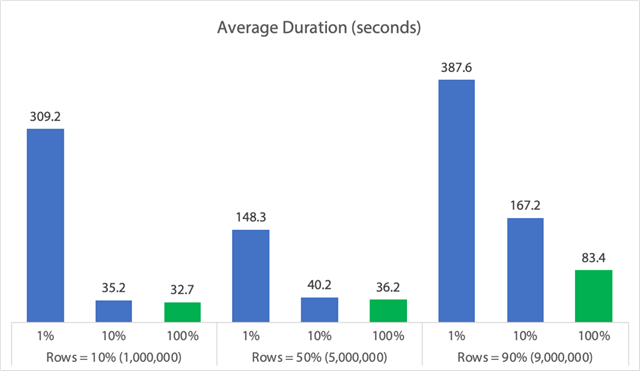
(Note que se retirarmos os 6,062 segundos de duração máxima identificada anteriormente, a primeira coluna cai de 309 segundos para 162 segundos.)
Agora, mesmo no melhor dos casos, isso ainda é 33, 36, ou 83 segundos onde a adelete está correndo e potencialmente bloqueando todos os outros, e isso está ignorando outros impactos medidos como memória, arquivo de log, CPU, e assim por diante. A duração certamente não deveria ser o seu único critério; acontece apenas que normalmente é a primeira (e às vezes apenas) coisa que as pessoas olham. Este arnês de teste foi feito para mostrar que você pode e deve capturar várias outras métricas também, e os resultados mostram que o outlierscan vem de qualquer lugar.
Usando este arnês como modelo, você pode construir seus próprios testes focados amanhã nas restrições e capacidades em seu ambiente. Eu não fiz um teste de métrica de todos os ângulos possíveis, já que isso é um monte de permutações, mas eu vou manter essa base de dados por aí. Portanto, se houver outras maneiras de você querer ver os dados cortados, basta me informar nos comentários abaixo, e eu verei o que eu posso fazer. Só não me peça para executar todos os testes novamente.
Cavernas
Isso tudo não considera uma carga de trabalho concorrente, o impacto das restrições da tabela como chaves estrangeiras, a presença de triggers e uma série de outros cenários possíveis.Outra coisa a ser testada (potencialmente numa futura dica) é ter múltiplos trabalhos que interagem com esta mesma tabela durante toda a operação, e medir coisas como durações de bloqueio, tipos e tempos de espera, e avaliar em que situações uma atividade seqüencial tem um impacto mais dramático sobre o outro conjunto.
Passos seguintes
Ler para dicas relacionadas e outros recursos:
- Operações deCRUD no SQL Server
- Diferenças entre Apagar e Truncar no SQL Server
- Apagar dados históricos de um grande banco de dados do SQL Server Highly Concurrent DatabaseTable
- Quebrar grandes operações de apagar em pedaços
- ServidorSQL Clustered and Nonclustered Columnstore Index Example
- Delayed Durability in SQL Server 2014
- Delayed Durability while Purging Data
- Accelerated Database Recovery in SQL Server 2019
Last Updated: 2019-12-03

>
 >
>>
>
>
Sobre o autor
>
 Aaron Bertrand (@AaronBertrand) é um tecnólogo apaixonado com experiência na indústria que remonta ao Classic ASP e SQL Server 6.5. Ele é editor-chefe do blog relacionado à performance, SQLPerformance.com, e também blogs em sqlblog.org.
Aaron Bertrand (@AaronBertrand) é um tecnólogo apaixonado com experiência na indústria que remonta ao Classic ASP e SQL Server 6.5. Ele é editor-chefe do blog relacionado à performance, SQLPerformance.com, e também blogs em sqlblog.org.Ver todas as minhas dicas
- Mais Dicas DBA Server SQL…