
- Accedi ai migliori progetti di ML
- Progetti di apprendimento automatico per principianti nel 2021
- Previsione delle vendite utilizzando Walmart Dataset
- Progetto ML di previsione delle vendite di BigMart
- Sistema di raccomandazione musicale Progetto
- Riconoscimento dell’attività umana usando il dataset dello smartphone
- Previsione dei prezzi delle azioni usando le serie temporali
- Previsione della qualità del vino usando il dataset della qualità del vino
- MNIST Classificazione delle cifre scritte a mano
- Imparare a costruire sistemi di raccomandazione con il dataset Movielens
- Progetto ML di previsione dei prezzi delle case a Boston
- Analisi del sentimento dei social media usando Twitter Dataset
- Progetto ML di classificazione dei fiori di iris
- Ottimizzazione dei prezzi al dettaglio usando l’apprendimento automatico
- Analisi di previsione del churn dei clienti
- 1. Previsione delle vendite usando il dataset di Walmart
- 2. BigMart Sales Prediction ML Project – Learn about Unsupervised Machine Learning Algorithms
- Music Recommendation System Project
- Riconoscimento dell’attività umana usando il dataset dello smartphone
- Previsione dei prezzi delle azioni utilizzando TimeSeries
- Predicendo la qualità del vino usando il dataset della qualità del vino
- MNIST Handwritten Digit Classification
- Impara a costruire sistemi di raccomandazione con Movielens Dataset
- Boston Housing Price Prediction ML Project
- Analisi del sentimento dei social media utilizzando il dataset di Twitter
- Iris Flowers Classification ML Project- Learn about Supervised Machine Learning Algorithms
- Progetti di apprendimento automatico per principianti con codice sorgente in Python per il 2021
- 12) Progetto ML di ottimizzazione dei prezzi al dettaglio – Modello di apprendimento automatico dei prezzi dinamico per un mercato dinamico
- 13) Customer Churn Prediction Analysis Using Ensemble Techniques in Machine Learning
- Come posso iniziare un progetto di apprendimento automatico?
- 1) Primo passo: Machine Learning Project Scoping
- 2) Secondo passo: Dati
- 3) Terzo passo – Costruire il modello
- 4) Quarto passo – Distribuzione del modello nella produzione
- Come mettere i progetti di apprendimento automatico sul tuo curriculum?
- Che altro?
Accedi ai migliori progetti di ML
×
Ultimo aggiornamento: 05 Mar 2021

Vuoi imparare l’apprendimento automatico ma hai problemi ad iniziare. I libri e i corsi potrebbero non essere sufficienti quando si tratta di apprendimento automatico, anche se danno sempre esempi di codici di apprendimento automatico e snippet, non si ha l’opportunità di implementare l’apprendimento automatico ai problemi del mondo reale e vedere come questi snippet di codice si adattano insieme. Il modo migliore per iniziare a imparare l’apprendimento automatico è quello di implementare progetti di apprendimento automatico dal livello principiante a quello avanzato. E’ sempre utile ottenere informazioni su come le persone reali stanno iniziando le loro carriere nell’apprendimento automatico implementando progetti ML end-to-end.
In questo post del blog, scoprirai come i principianti come te possono fare grandi progressi nell’applicazione dell’apprendimento automatico ai problemi del mondo reale con questi fantastici progetti di apprendimento automatico per principianti raccomandati dagli esperti del settore. Gli esperti del settore ProjectPro hanno curato attentamente la lista dei migliori progetti di apprendimento automatico per principianti che coprono gli aspetti fondamentali dell’apprendimento automatico come l’apprendimento supervisionato, l’apprendimento non supervisionato, l’apprendimento profondo e le reti neurali. In tutti questi progetti di apprendimento automatico inizierete con set di dati del mondo reale che sono pubblicamente disponibili. Vi assicuriamo che troverete questo blog assolutamente interessante e degno di essere letto a causa di tutte le cose che potrete imparare da qui sui progetti di apprendimento automatico più popolari.
“Quali progetti posso fare con l’apprendimento automatico? Questa domanda ci viene spesso posta dai principianti che iniziano a lavorare con il machine learning. Gli esperti del settore ProjectPro ti raccomandano di esplorare alcune idee di progetti di machine learning eccitanti, interessanti, divertenti e facili in diversi domini di business per fare esperienza pratica sulle competenze di machine learning che hai imparato. Abbiamo curato una lista di progetti di apprendimento automatico innovativi e interessanti con codice sorgente per i professionisti che iniziano la loro carriera nell’apprendimento automatico. Questi progetti per principianti sull’apprendimento automatico sono una miscela perfetta di vari tipi di sfide che si possono incontrare quando si lavora come ingegnere di apprendimento automatico o scienziato dei dati.
Progetti di apprendimento automatico per principianti nel 2021
-
Previsione delle vendite utilizzando Walmart Dataset
-
Progetto ML di previsione delle vendite di BigMart
-
Sistema di raccomandazione musicale Progetto
-
Riconoscimento dell’attività umana usando il dataset dello smartphone
-
Previsione dei prezzi delle azioni usando le serie temporali
-
Previsione della qualità del vino usando il dataset della qualità del vino
-
MNIST Classificazione delle cifre scritte a mano
-
Imparare a costruire sistemi di raccomandazione con il dataset Movielens
-
Progetto ML di previsione dei prezzi delle case a Boston
-
-
Progetto ML di classificazione dei fiori di iris
-
Ottimizzazione dei prezzi al dettaglio usando l’apprendimento automatico
-
Analisi di previsione del churn dei clienti
Tuffiamoci!

1. Previsione delle vendite usando il dataset di Walmart
La previsione delle vendite è uno dei casi d’uso più comuni del machine learning per identificare i fattori che influenzano le vendite di un prodotto e stimare il volume delle vendite future. Questo progetto di apprendimento automatico utilizza il dataset di Walmart che ha dati di vendita per 98 prodotti in 45 punti vendita. Il dataset contiene le vendite per negozio, per reparto su base settimanale. L’obiettivo di questo progetto di apprendimento automatico è quello di prevedere le vendite per ogni reparto in ogni punto vendita per aiutarli a prendere decisioni migliori basate sui dati per l’ottimizzazione del canale e la pianificazione delle scorte. L’aspetto impegnativo del lavoro con il dataset di Walmart è che contiene selezionati eventi di sconto che influenzano le vendite e dovrebbero essere presi in considerazione.
Questo è uno dei progetti di apprendimento automatico più semplici e interessanti in cui costruirai un modello predittivo utilizzando il set di dati Walmart per stimare il numero di vendite che faranno in futuro ed ecco come –
- Importa i dati ed esplorali per capire la struttura e i valori all’interno dei dati – Inizia importando un file CSV ed eseguendo un’analisi esplorativa di base dei dati (EDA).
- Preparare i dati per la modellazione – Unire più set di dati e applicare la funzione “group by” per analizzare i dati.
- Plottare un grafico di serie temporali e analizzarlo.
- Adattare i modelli di previsione delle vendite sviluppati ai dati di formazione – Creare un modello ARIMA per la previsione delle serie temporali
- Confrontare i modelli sviluppati sui dati di prova.
- Ottimizzare i modelli di previsione delle vendite scegliendo caratteristiche importanti per migliorare il punteggio di precisione.
- Utilizzare il miglior modello di apprendimento automatico per prevedere le vendite del prossimo anno.
Dopo aver lavorato a questo progetto di apprendimento automatico Kaggle capirete come potenti modelli di apprendimento automatico possono rendere semplice il processo generale di previsione delle vendite. Riutilizza questi modelli di machine learning di previsione delle vendite end-to-end in produzione per prevedere le vendite di qualsiasi reparto o negozio al dettaglio.
Vuoi lavorare con Walmart Dataset? Accedi alla soluzione completa di questo fantastico progetto di apprendimento automatico qui – Walmart Store Sales Forecasting Machine Learning Project
2. BigMart Sales Prediction ML Project – Learn about Unsupervised Machine Learning Algorithms
Il dataset di vendite BigMart consiste in dati di vendita 2013 per 1559 prodotti in 10 diversi punti vendita in diverse città. L’obiettivo del progetto ML di previsione delle vendite di BigMart è quello di costruire un modello di regressione per prevedere le vendite di ciascuno dei 1559 prodotti per l’anno successivo in ciascuno dei 10 diversi punti vendita BigMart. Il dataset delle vendite di BigMart consiste anche in alcuni attributi per ogni prodotto e negozio. Questo modello aiuta BigMart a capire le proprietà dei prodotti e dei negozi che giocano un ruolo importante nell’aumentare le loro vendite complessive.
Accedi alla soluzione completa di questo progetto ML qui – BigMart Sales Prediction Machine Learning Project Solution
Music Recommendation System Project
Questo è uno dei progetti di apprendimento automatico più popolari e può essere utilizzato in diversi domini. Potreste avere molta familiarità con un sistema di raccomandazione se avete usato un qualsiasi sito di E-commerce o un sito di film/musica. Nella maggior parte dei siti di e-commerce come Amazon, al momento del checkout, il sistema consiglierà i prodotti che possono essere aggiunti al carrello. Allo stesso modo su Netflix o Spotify, in base ai film che ti sono piaciuti, ti mostrerà film o canzoni simili che potrebbero piacerti. Come fa il sistema a fare questo? Questo è un classico esempio in cui il Machine Learning può essere applicato.
In questo progetto, usiamo il dataset del principale servizio di streaming musicale dell’Asia per costruire un migliore sistema di raccomandazione musicale. Cercheremo di determinare quale nuova canzone o quale nuovo artista potrebbe piacere a un ascoltatore in base alle sue scelte precedenti. Il compito principale è quello di predire le possibilità che un utente ascolti una canzone ripetutamente in un periodo di tempo. Nel set di dati, la previsione è segnata come 1 se l’utente ha ascoltato la stessa canzone entro un mese. Il dataset consiste in quale canzone è stata ascoltata da quale utente e in quale momento.
Vuoi costruire un sistema di raccomandazione – controlla questo progetto ML risolto qui – Music Recommendation Machine Learning Project
Riconoscimento dell’attività umana usando il dataset dello smartphone
Il dataset dello smartphone consiste in registrazioni di attività di fitness di 30 persone catturate attraverso smartphone con sensori inerziali. L’obiettivo di questo progetto di apprendimento automatico è quello di costruire un modello di classificazione che possa identificare con precisione le attività di fitness umane. Lavorare su questo progetto di apprendimento automatico vi aiuterà a capire come risolvere problemi di multiclassificazione.
Accedi al codice sorgente di questo progetto ML qui Human Activity Recognition using Smartphone Dataset Project
Clicca qui per vedere una lista di 50+ risolti, end-to-end Big Data and Machine Learning Project Solutions (codice riutilizzabile + video)
Previsione dei prezzi delle azioni utilizzando TimeSeries
Questa è un’altra interessante idea di progetto di apprendimento automatico per scienziati di dati/ingegneri di apprendimento automatico che lavorano o progettano di lavorare nel campo della finanza. Un predittore di prezzi azionari è un sistema che impara a conoscere le prestazioni di una società e a prevedere i prezzi futuri delle azioni. Le sfide associate al lavoro con i dati sui prezzi delle azioni è che sono molto granulari, e inoltre ci sono diversi tipi di dati come indici di volatilità, prezzi, indicatori macroeconomici globali, indicatori fondamentali e altro. Una cosa positiva del lavorare con i dati del mercato azionario è che i mercati finanziari hanno cicli di feedback più brevi che rendono più facile per gli esperti di dati convalidare le loro previsioni sui nuovi dati. Per iniziare a lavorare con i dati del mercato azionario, si può prendere un semplice problema di apprendimento automatico come prevedere i movimenti di prezzo a 6 mesi sulla base di indicatori fondamentali dal rapporto trimestrale di un’organizzazione. Puoi scaricare i set di dati del mercato azionario da Quandl.com o Quantopian.com. Ci sono diversi metodi di previsione delle serie temporali per prevedere il prezzo delle azioni, la domanda, ecc.
Guarda questo progetto di apprendimento automatico dove imparerai a determinare quale metodo di previsione deve essere utilizzato quando e come applicare con l’esempio di previsione delle serie temporali. Stock Prices Predictor using TimeSeries Project
Predicendo la qualità del vino usando il dataset della qualità del vino
È un fatto noto che più vecchio è il vino, migliore è il gusto. Tuttavia, ci sono diversi fattori diversi dall’età che entrano nella certificazione della qualità del vino che includono test fisiochimici come la quantità di alcol, l’acidità fissa, l’acidità volatile, la determinazione della densità, il pH, e altro ancora. L’obiettivo principale di questo progetto di apprendimento automatico è quello di costruire un modello di apprendimento automatico per prevedere la qualità dei vini esplorando le loro varie proprietà chimiche. Il set di dati sulla qualità del vino consiste in 4898 osservazioni con 11 variabili indipendenti e 1 variabile dipendente.
Accedi alla soluzione completa di questo progetto di apprendimento automatico qui – Wine Quality Prediction in R
MNIST Handwritten Digit Classification
L’apprendimento profondo e le reti neurali giocano un ruolo vitale nel riconoscimento delle immagini, nella generazione automatica del testo e persino nelle auto a guida autonoma. Per iniziare a lavorare in queste aree, è necessario iniziare con un dataset semplice e gestibile come il dataset MNIST. È difficile lavorare con i dati di immagine rispetto ai dati relazionali piatti e, come principiante, ti suggeriamo di prendere e risolvere il MNIST Handwritten Digit Classification Challenge. Il dataset MNIST è troppo piccolo per entrare nella memoria del tuo PC ed è adatto ai principianti. Tuttavia, il riconoscimento delle cifre scritte a mano ti metterà alla prova.
Fai il tuo ingresso classico nella risoluzione dei problemi di riconoscimento delle immagini accedendo alla soluzione completa qui – MNIST Handwritten Digit Classification Project
Impara a costruire sistemi di raccomandazione con Movielens Dataset
Da Netflix a Hulu, la necessità di costruire un efficiente sistema di raccomandazione di film ha guadagnato importanza nel tempo con la crescente domanda da parte dei consumatori moderni di contenuti personalizzati. Uno dei set di dati più popolari disponibili sul web per i principianti per imparare a costruire sistemi di raccomandazione è il dataset Movielens che contiene circa 1.000.209 valutazioni di 3.900 film fatte da 6.040 utenti Movielens. Puoi iniziare a lavorare con questo dataset costruendo una visualizzazione world-cloud di titoli di film per costruire un sistema di raccomandazione di film.
L’accesso gratuito agli esempi di codice risolto può essere trovato qui (questi sono pronti all’uso per i tuoi progetti ML)
Boston Housing Price Prediction ML Project
Boston House Prices Dataset consiste nei prezzi delle case in diversi luoghi di Boston. Il dataset consiste anche di informazioni sulle aree di attività non commerciali (INDUS), il tasso di criminalità (CRIM), l’età delle persone che possiedono una casa (AGE), e diversi altri attributi (il dataset ha un totale di 14 attributi). Il dataset di Boston Housing può essere scaricato dall’UCI Machine Learning Repository. L’obiettivo di questo progetto di apprendimento automatico è quello di prevedere il prezzo di vendita di una nuova casa applicando concetti base di apprendimento automatico ai dati sui prezzi delle abitazioni. Questo set di dati è troppo piccolo con 506 osservazioni ed è considerato un buon inizio per i principianti dell’apprendimento automatico per iniziare a fare pratica sui concetti di regressione.
Lettura consigliata – 15+ Progetti di scienza dei dati per principianti
Le piattaforme dei social media come Twitter, Facebook, YouTube, Reddit generano enormi quantità di grandi dati che possono essere estratti in vari modi per capire le tendenze, i sentimenti pubblici e le opinioni. I dati dei social media oggi sono diventati rilevanti per il branding, il marketing e il business nel suo complesso. Un analizzatore di sentimento impara a conoscere i vari sentimenti dietro un “pezzo di contenuto” (potrebbe essere IM, email, tweet, o qualsiasi altro post sui social media) attraverso l’apprendimento automatico e predice lo stesso usando l’AI. I dati di Twitter sono considerati come un punto di ingresso definitivo per i principianti per praticare l’analisi del sentimento dei problemi di apprendimento automatico. Utilizzando il set di dati di Twitter, si può ottenere una miscela accattivante di contenuti di tweet e altri metadati correlati come hashtag, retweet, posizione, utenti e altro ancora che aprono la strada ad analisi approfondite. Il dataset di Twitter è composto da 31.962 tweet e ha una dimensione di 3MB. Utilizzando i dati di Twitter è possibile scoprire ciò che il mondo sta dicendo su un argomento, che si tratti di film, sentimenti sulle elezioni americane, o qualsiasi altro argomento di tendenza come prevedere chi avrebbe vinto la Coppa del Mondo FIFA 2018. Lavorare con il set di dati di Twitter vi aiuterà a capire le sfide associate al data mining dei social media e anche a conoscere i classificatori in profondità. Il problema principale su cui puoi iniziare a lavorare come principiante è costruire un modello per classificare i tweet come positivi o negativi.
L’accesso gratuito al codice risolto Gli esempi di Python e R possono essere trovati qui (questi sono pronti all’uso per i tuoi progetti di Data Science e ML)
Iris Flowers Classification ML Project- Learn about Supervised Machine Learning Algorithms
Questo è uno dei più semplici progetti di apprendimento automatico con Iris Flowers che è il più semplice dataset di apprendimento automatico nella letteratura di classificazione. Questo problema di apprendimento automatico è spesso indicato come il “Hello World” dell’apprendimento automatico. Il set di dati ha attributi numerici e i principianti di ML devono capire come caricare e gestire i dati. Il dataset dell’iris è piccolo e si adatta facilmente alla memoria e non richiede alcuna trasformazione speciale o scalatura, per cominciare.
Iris Dataset può essere scaricato da UCI ML Repository – Download Iris Flowers Dataset
L’obiettivo di questo progetto di apprendimento automatico è classificare i fiori tra le tre specie – virginica, setosa, o versicolor in base alla lunghezza e larghezza dei petali e dei sepali.
L’accesso gratuito agli esempi risolti di codice Python e R di apprendimento automatico può essere trovato qui (questi sono pronti all’uso per i tuoi progetti)
Progetti di apprendimento automatico per principianti con codice sorgente in Python per il 2021
12) Progetto ML di ottimizzazione dei prezzi al dettaglio – Modello di apprendimento automatico dei prezzi dinamico per un mercato dinamico
Le gare di prezzo stanno crescendo senza sosta in ogni settore verticale e l’ottimizzazione dei prezzi è la chiave per gestire i profitti in modo efficiente per qualsiasi azienda. Identificare una fascia di prezzo ragionevole e fare un aggiustamento dei prezzi dei prodotti per aumentare le vendite mantenendo i margini di profitto ottimali è sempre stata una grande sfida nel settore della vendita al dettaglio. Il modo più veloce in cui i rivenditori possono garantire il più alto ROI oggi, ottimizzando i prezzi, è quello di sfruttare la potenza del machine learning per costruire soluzioni di prezzo efficaci. Il gigante dell’e-commerce Amazon è stato uno dei primi ad adottare il machine learning nell’ottimizzazione dei prezzi al dettaglio che ha contribuito alla sua crescita stellare da 30 miliardi nel 2008 a circa 1 trilione nel 2019.

Image Credit: spd. group
100+ Datasets for Machine Learning Projects Curated Specially For You
La soluzione del problema di apprendimento automatico dell’ottimizzazione dei prezzi al dettaglio richiede la formazione di un modello di apprendimento automatico in grado di prezzare automaticamente i prodotti come verrebbero prezzati dagli umani. I modelli di machine learning per l’ottimizzazione dei prezzi al dettaglio prendono i dati storici delle vendite, le varie caratteristiche dei prodotti e altri dati non strutturati come immagini e informazioni testuali per imparare le regole di prezzo senza l’intervento umano, aiutando i rivenditori ad adattarsi a un ambiente di prezzi dinamico per massimizzare le entrate senza perdere i margini di profitto. L’algoritmo di machine learning per l’ottimizzazione dei prezzi al dettaglio elabora un numero infinito di scenari di prezzo per selezionare il prezzo ottimale per un prodotto in tempo reale considerando migliaia di relazioni latenti all’interno di un prodotto.
Guarda questo bel progetto di machine learning sull’ottimizzazione dei prezzi al dettaglio per un’immersione profonda nell’analisi dei dati di vendita della vita reale per un Café dove si costruirà una soluzione di machine learning end-to-end che suggerisce automaticamente i prezzi giusti dei prodotti.
13) Customer Churn Prediction Analysis Using Ensemble Techniques in Machine Learning
I clienti sono la più grande risorsa di un’azienda e mantenere i clienti è importante per qualsiasi azienda per aumentare le entrate e costruire una relazione significativa e duratura con i clienti. Inoltre, il costo di acquisizione di un nuovo cliente è cinque volte superiore a quello di mantenimento di un cliente esistente. Il Customer Churn/Attrition è uno dei problemi più riconosciuti nel business in cui i clienti o gli abbonati smettono di fare affari con un servizio o un’azienda. Idealmente, smettono di essere clienti pagati. Si dice che un cliente è “churned” se è passato un determinato lasso di tempo dall’ultima interazione del cliente con l’azienda.
Identificare se e quando un cliente “churn” e fornire rapidamente informazioni attuabili finalizzate al mantenimento del cliente è fondamentale per ridurre il churn. Non è possibile per i nostri cervelli anticipare il churn di milioni di clienti, è qui che il machine learning può aiutare. Il machine learning fornisce metodi efficaci per identificare i fattori alla base del churn e strumenti proscrittivi per affrontarlo. Gli algoritmi di apprendimento automatico giocano un ruolo vitale nella gestione proattiva del churn in quanto rivelano i modelli comportamentali dei clienti che hanno già smesso di utilizzare i servizi o di acquistare prodotti. Poi, i modelli di apprendimento automatico controllano il comportamento dei clienti esistenti rispetto a tali modelli per identificare i potenziali churners.

Image Credit. :gallery.azure.ai
Ma come iniziare a risolvere il problema di apprendimento automatico della previsione del tasso di abbandono dei clienti? Come qualsiasi altro problema di apprendimento automatico, gli scienziati dei dati o gli ingegneri dell’apprendimento automatico devono raccogliere e preparare i dati per l’elaborazione. Affinché qualsiasi approccio di apprendimento automatico sia efficace, ha senso ingegnerizzare i dati nel formato giusto. Il Feature Engineering è la parte più creativa del modello di apprendimento automatico di previsione della rinuncia, dove gli specialisti dei dati usano la loro esperienza, il contesto aziendale, la conoscenza del dominio dei dati e la creatività per creare le caratteristiche e adattare il modello di apprendimento automatico per capire perché la rinuncia dei clienti avviene in un business specifico.
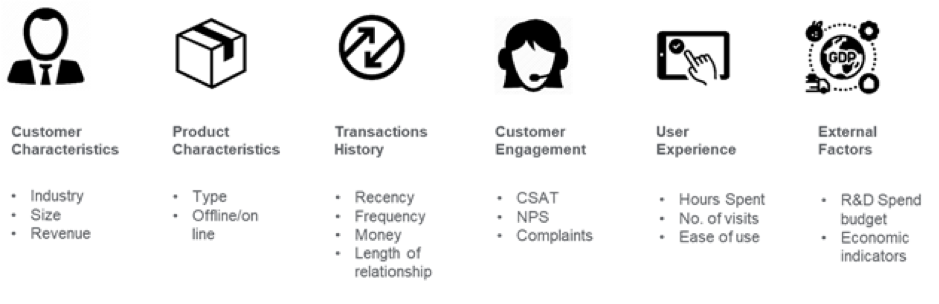
Image Credit: medium.com
Per esempio, nel settore bancario, due conti che hanno lo stesso saldo mensile possono essere difficili da differenziare per la previsione della rinuncia. Ma, l’ingegneria delle caratteristiche può aggiungere una dimensione temporale a questi dati in modo che gli algoritmi di ML possano differenziare se il saldo di chiusura mensile si è discostato da quello che ci si aspetta di solito da un cliente. Indicatori come i conti dormienti, l’aumento dei prelievi, le tendenze d’uso, il deflusso netto del saldo negli ultimi giorni possono essere segni premonitori di churn. Questi dati interni combinati con dati esterni come le offerte dei concorrenti possono aiutare a prevedere il churn dei clienti. Avendo identificato le caratteristiche, il passo successivo è quello di capire perché si verificano i casi di abbandono in un contesto aziendale e rimuovere le caratteristiche che non sono forti predittori per ridurre la dimensionalità.
Guarda questo progetto di apprendimento automatico end-to-end con codice sorgente in Python su Customer Churn Prediction Analysis using Ensemble Learning to combat churn.
Come posso iniziare un progetto di apprendimento automatico?
Nessun progetto procede con successo senza una solida pianificazione, e l’apprendimento automatico non fa eccezione. Costruire il vostro primo progetto di machine learning non è in realtà così difficile come sembra, a condizione che abbiate una solida strategia di pianificazione. Per iniziare qualsiasi progetto di ML, si deve seguire un approccio completo end-to-end – a partire dallo scoping del progetto fino alla distribuzione del modello e alla gestione in produzione Ecco il nostro punto sui passi fondamentali di un piano di progetto di machine learning per assicurarsi di ottenere il massimo da ogni progetto unico –
1) Primo passo: Machine Learning Project Scoping
Prima di tutto, capire quali sono i requisiti di business del progetto ML. Quando si inizia un progetto di ML, selezionare il caso d’uso rilevante per il business che il modello di machine learning sarà costruito per affrontare è il passo fondamentale. Scegliere il giusto caso d’uso del machine learning e valutare il suo ROI è importante per il successo di qualsiasi progetto di machine learning.
2) Secondo passo: Dati
I dati sono la linfa vitale di qualsiasi modello di apprendimento automatico ed è impossibile addestrare un modello di apprendimento automatico senza dati. La fase dei dati nel ciclo di vita di un progetto di machine learning è un processo in quattro fasi –
-
Requisiti dei dati – Capire che tipo di dati saranno necessari, il formato dei dati, le fonti di dati e i requisiti di conformità delle fonti di dati è importante.
-
Raccolta dei dati – Con l’aiuto di amministratori di database, architetti di dati o sviluppatori è necessario impostare la strategia di raccolta dei dati per estrarre i dati dai luoghi in cui vivono all’interno dell’organizzazione o da altri fornitori terzi.
-
Analisi esplorativa dei dati – Questa fase comporta fondamentalmente la convalida dei requisiti dei dati per assicurarsi di avere i dati corretti, i dati sono in buone condizioni e privi di errori.
-
Preparazione dei dati – Questa fase comporta la preparazione dei dati per l’uso da parte degli algoritmi di apprendimento automatico. La correzione degli errori, l’ingegneria delle caratteristiche, la codifica in formati di dati che le macchine possono capire, e la correzione delle anomalie sono i compiti coinvolti nella preparazione dei dati.
3) Terzo passo – Costruire il modello
A seconda della natura del progetto, questo passo potrebbe richiedere alcuni giorni o mesi. Nella fase di modellazione, si prende una decisione su quale algoritmo di apprendimento automatico utilizzare e si inizia ad addestrare il modello sui dati. Capire la misura di accuratezza, errore e correttezza a cui un modello di apprendimento automatico dovrebbe aderire è importante per la selezione del modello. Avendo addestrato il modello, lo si valuta sui dati di convalida in modo da analizzare le sue prestazioni e prevenire l’overfitting. La valutazione del modello è un passo critico perché se un modello funziona perfettamente con i dati storici e restituisce scarse prestazioni con i dati futuri, non è di alcuna utilità.
4) Quarto passo – Distribuzione del modello nella produzione
Questo passo comporta la distribuzione del software o dell’applicazione agli utenti finali in modo che nuovi dati possano fluire nel modello di apprendimento automatico per un ulteriore apprendimento. Distribuire il modello di apprendimento automatico non è sufficiente, è anche necessario assicurarsi che il modello di apprendimento automatico stia funzionando come previsto. Si dovrebbe riaddestrare il modello sui nuovi dati di produzione dal vivo per assicurare la sua accuratezza o le sue prestazioni – questo è il tuning del modello. Il tuning del modello richiede anche la convalida del modello per garantire che non stia andando alla deriva o diventando distorto.
Come mettere i progetti di apprendimento automatico sul tuo curriculum?
L’esperienza nel mondo reale ti prepara al successo finale come nient’altro. Come principiante dell’apprendimento automatico, più puoi acquisire esperienza in tempo reale lavorando su progetti di apprendimento automatico, più sarai preparato ad afferrare i lavori più caldi del decennio. Ottenere un lavoro di machine learning dopo aver completato la formazione sulla scienza dei dati o avere successo come scienziato dei dati dipenderà dalla tua capacità di venderti. Dopo aver seguito una formazione completa sulla scienza dei dati, il passo successivo per ottenere un lavoro come ingegnere dell’apprendimento automatico o scienziato dei dati è quello di costruire un portfolio eccezionale per mostrare la tua capacità di applicare le tecniche di apprendimento automatico ai tuoi potenziali datori di lavoro. Lavorare su interessanti progetti di ML è un ottimo modo per dare il via alla tua carriera come ingegnere aziendale di apprendimento automatico o scienziato dei dati. I datori di lavoro vogliono vedere che tipo di progetti relativi alla scienza dei dati e all’apprendimento automatico su cui hai lavorato per valutare la gamma delle tue capacità nel fare scienza dei dati e apprendimento automatico. Evidenziare alcuni esempi di progetti di data science e machine learning divertenti e interessanti sul tuo curriculum avrà più peso che dire loro quanto sai. Ecco come puoi aggiungere fantastici progetti al tuo curriculum di machine learning –
- Puoi menzionare i progetti di machine learning subito dopo la sezione delle tue esperienze lavorative nel curriculum di machine learning.
- Segui un ordine sequenziale di numerazione insieme al titolo dei progetti su cui hai lavorato.
- Il titolo del progetto dovrebbe essere seguito da un piccolo riassunto del dataset e del problema.
- Cita gli strumenti di apprendimento automatico e le tecnologie che hai usato per completare un progetto.
- Infine, ma non meno importante, nel tuo portfolio/resume collega ogni progetto di apprendimento automatico a GitHub, sito web personale o blog per una comprensione approfondita dei tuoi risultati.
Se vuoi costruire un forte portfolio di apprendimento automatico o vuoi mettere in pratica le abilità analitiche che hai imparato nel tuo corso di formazione sulla scienza dei dati, noi ti abbiamo coperto. Molti principianti dell’apprendimento automatico non sono sicuri da dove iniziare, quali progetti di apprendimento automatico fare, quali strumenti di apprendimento automatico, tecniche e strutture utilizzare. Abbiamo reso un compito senza problemi per i principianti della scienza dei dati e dell’apprendimento automatico curando una lista di idee interessanti per progetti di apprendimento automatico insieme alle loro soluzioni. Queste idee di progetti di apprendimento automatico sono prese dalle popolari sfide di scienza dei dati di Kaggle e sono un ottimo modo per imparare l’apprendimento automatico. Questo elenco di progetti è un modo perfetto per mettere progetti di apprendimento automatico sul tuo curriculum. La giusta mentalità, la volontà di imparare e un sacco di esplorazione dei dati sono tutti necessari per capire la soluzione ai progetti sulla scienza dei dati e l’apprendimento automatico. Puoi esplorare 50+ progetti di scienza dei dati e ML basati sull’insieme di competenze, strumenti e tecniche che devi imparare.
Prima di iniziare il tuo progetto, è utile avere accesso a una libreria di esempi di codice di progetti di apprendimento automatico. Così ogni volta che sei bloccato sul progetto puoi usare questi esempi risolti per sbloccarti.
Accedi agli esempi di codice per progetti di Data Science e Machine Learning
Che altro?
Si può diventare un maestro dell’apprendimento automatico solo con molta pratica e sperimentazione. Avere conoscenze teoriche aiuta sicuramente, ma è l’applicazione che aiuta di più il progresso. Nessuna quantità di conoscenza teorica può sostituire la pratica pratica. Tuttavia, vi aiuterà se familiarizzate con gli innovativi progetti di apprendimento automatico sopra elencati.
Se siete principianti e nuovi all’apprendimento automatico, lavorare sui progetti di apprendimento automatico progettati dagli esperti del settore di ProjectPro sarà uno dei migliori investimenti del vostro tempo. Questi progetti sono stati progettati per i principianti per aiutarli a migliorare le loro competenze di machine learning applicate rapidamente, dando loro la possibilità di esplorare casi d’uso interessanti in vari domini – vendita al dettaglio, finanza, assicurazioni, produzione e altro ancora. Quindi, se vuoi divertirti a imparare l’apprendimento automatico, rimanere motivato e fare rapidi progressi, allora gli interessanti progetti di ML di ProjectPro sono per te. Inoltre, aggiungi questi progetti di apprendimento automatico al tuo portafoglio e ottieni un lavoro al top con uno stipendio più alto e gratificanti vantaggi.

Clicca qui per visualizzare una lista di 50+ soluzioni di progetto risolte, end-to-end in Machine Learning e Big Data
|
PREVIOUS |
NEXT |