
a.k.a. inter-rater reliability o concordance
In statistica, inter-rater reliability, inter-rater agreement, o concordance è il grado di accordo tra i valutatori. Dà un punteggio di quanta omogeneità, o consenso, c’è nelle valutazioni date dai giudici.
I Kappas trattati qui sono più appropriati per i dati “nominali”. L’ordinamento naturale nei dati (se esiste) è ignorato da questi metodi. Se hai intenzione di usare queste metriche assicurati di essere consapevole delle limitazioni.
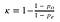
Ci sono due parti:
- Calcolare l’accordo osservato
- Calcolare l’accordo per caso
Diciamo che abbiamo a che fare con risposte “sì” e “no” e 2 classificatori. Ecco le valutazioni:
rater1 =
rater2 =
Trasformando queste valutazioni in una matrice di confusione:

Observed agreement = (6 + 1) / 10 = 0.7
Chance agreement = probability of randomly saying yes (P_yes) + probability of randomly saying no (P_no)
P_yes = (6 + 1) / 10 * (6 + 1) / 10 = 0.49
P_no = (1 + 1) / 10 * (1 + 1) / 10 = 0.04
Chance agreement = 0.49 + 0.04 = 0.53
Siccome l’accordo osservato è maggiore dell’accordo casuale, otterremo un Kappa positivo.
kappa = 1 - (1 - 0.7) / (1 - 0.53) = 0.36
Oppure basta usare l’implementazione di sklearn
from sklearn.metrics import cohen_kappa_scorecohen_kappa_score(rater1, rater2)
che restituisce 0,35714.
Interpretazione di Kappa

Casi particolari
Accordo inferiore al caso
rater1 =
rater2 =
cohen_kappa_score(rater1, rater2)
-0.2121
Se tutte le valutazioni sono uguali e opposte
Questo caso produce in modo affidabile un kappa di 0
rater1 = * 10
rater2 = * 10
cohen_kappa_score(rater1, rater2)
0.0
Valutazione casuale
Per le valutazioni casuali Kappa segue una distribuzione normale con una media di circa zero.
Come il numero di valutazioni aumenta c’è meno variabilità nel valore di Kappa nella distribuzione.
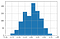
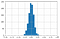
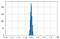
Puoi trovare maggiori dettagli qui
Nota che il Kappa di Cohen si applica solo a 2 valutatori che valutano esattamente gli stessi articoli.