
Perché: Aaron Bertrand | Aggiornato: 2019-12-03 | Commenti (1) | Correlati: More > Performance Tuning
Problema
Diversi anni fa, ho scritto sul blog di come è possibile ridurre l’impatto sul transactionlog spezzando le operazioni di cancellazione in pezzi. Invece di cancellare 100.000 righe in una grande transazione, si possono cancellare 100 o 1.000 o un numero arbitrario di righe alla volta, in diverse transazioni più piccole, in un ciclo. Oltre a ridurre l’impatto sul log, si potrebbe dare sollievo ai blocchi di lunga durata. A quel tempo, gli SSD stavano appena prendendo piede, e le nuove tecnologie come gli indici Columnstore clusterizzati, la durabilità ritardata e il recupero accelerato del database non esistevano ancora. Così, ho pensato che potrebbe essere il momento per un aggiornamento per dare un quadro migliore di come questo si rivela in SQL Server2019.
Soluzione
Eliminare grandi porzioni di una tabella non è sempre l’unica risposta. Se si elimina il 95% di una tabella e si mantiene il 5%, può essere più veloce spostare le righe che si desidera mantenere in una nuova tabella, eliminare la vecchia tabella e rinominare la nuova, oppure copiare le righe da mantenere, troncare la tabella e poi copiarle di nuovo. Ma anche quando l’epurazione è molto più grande del mantenimento, questo non è sempre possibile a causa di altri vincoli sulla tabella, SLA e altri fattori.
Ancora una volta, se si scopre di dover eliminare le righe, si vorrà minimizzare l’impatto sul log delle transazioni e come le operazioni influenzano il resto del carico di lavoro.L’approccio chunking non è un’idea nuova o innovativa, ma può funzionare bene con alcune di queste tecnologie più recenti, quindi mettiamole alla prova in una varietà di combinazioni.
Per impostare, abbiamo più costanti che saranno vere per ogni test:
- SQL Server 2019 RC1, con quattro core e 32 GB di RAM (memoria massima del server =28 GB)
- Tabella da 10 milioni di righe
- Riavviare SQL Server dopo ogni test (per resettare memoria, buffer, e plancache)
- Ripristinare un backup che aveva le statistiche già aggiornate e le statistiche automatiche disabilitate (per evitare che gli aggiornamenti delle statistiche attivati interferiscano con le operazioni di cancellazione)
Abbiamo anche molte variabili che cambieranno per ogni test:
Questo produrrà 864 test unici, ed è meglio credere che ho intenzione di automatizzare tutte queste permutazioni.
E le metriche che misureremo:
- Durata complessiva
- Uso medio/picco della CPU
- Uso medio/picco della memoria
- Uso del log delle transazioni/crescita del file
- Uso del file del database, dimensione del version store (quando si usa Accelerated DatabaseRecovery)
- Dimensione delta rowgroup (quando si usa Columnstore)
Tabella sorgente
Prima di tutto, ho ripristinato una copia di AdventureWorks (AdventureWorks2017.bak, per essere specifici). Per creare una tabella con 10 milioni di righe, ho fatto una copia di Sales.SalesOrderDetail, con la sua colonna di identità, e ho aggiunto una colonna di riempimento solo per dare ad ogni riga un po’ più di carne e ridurre la densità della pagina:
CREATE TABLE dbo.SalesOrderDetailCopy
(
SalesOrderDetailID int IDENTITY,
SalesOrderID int,
CarrierTrackingNumber nvarchar(25),
OrderQty smallint,
ProductID int,
SpecialOfferID int,
UnitPrice money,
UnitPriceDiscount money,
LineTotal numeric(38,6),
rowguid uniqueidentifier,
ModifiedDate datetime,
filler char(50) NOT NULL DEFAULT ''
);
GO
Poi, per generare i 10.000.000 di righe, ho inserito 100.000 righe alla volta, e ho eseguito l’inserimento 100 volte:
INSERT dbo.SalesOrderDetailCopy
(
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
)
SELECT TOP(100000)
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
FROM Sales.SalesOrderDetail;GO 100
Non ho creato alcun indice sulla tabella; a seconda dell’approccio di memorizzazione, creerò un nuovo indice clustered (columnstore la metà delle volte) dopo il ripristino del database come parte di ogni test.
Automazione dei test
Una volta che la tabella da 10 milioni di righe esisteva, ho impostato alcune opzioni, ho fatto il backup del database, ho fatto il backup del log due volte, e poi ho fatto di nuovo il backup del database (in modo che il log avesse il minor spazio possibile utilizzato quando veniva ripristinato):
Poi ho creato un database di controllo, dove avrei memorizzato le stored procedure che avrebbero eseguito i test, e le tabelle che avrebbero tenuto i risultati dei test (solo il tempo di inizio e fine di ogni test) e le metriche delle prestazioni catturate durante tutti i test.
Catturare le permutazioni di tutti gli 864 test che volevo eseguire ha richiesto alcuni tentativi, ma ho finito con questo:
Come previsto, questo ha inserito 864 righe con tutte quelle combinazioni.
In seguito, ho creato una stored procedure per catturare l’insieme delle metriche descritte prima.Sto anche monitorando l’istanza con SentryOne SQL Sentry, quindi ci saranno certamente altre informazioni interessanti disponibili, ma volevo anche catturare i dettagli importanti senza l’uso di strumenti di terze parti. Ecco la procedura, che si fa in quattro per produrre tutte le metriche per ogni dato timestamp in una singola riga:
Ho messo questa stored procedure in un job step e l’ho avviata. Potreste voler usare un ritardo diverso da tre secondi – c’è un compromesso tra il costo della raccolta e la completezza dei dati che potrebbe essere più in un modo che nell’altro per voi.
Infine, ho creato la procedura che avrebbe contenuto tutta la logica per determinare esattamente cosa fare con la combinazione di parametri per ogni singolo test.Anche questo ha richiesto diverse iterazioni, ma il prodotto finale è il seguente:
C’è molto da fare, ma la logica di base è questa:
- Prendere i dati specifici del test (TestID e tutti i parametri) dalla tabella dbo.Teststable
- Dare un calcio a SQL Server facendo una modifica sp_configure e cancellando buffer e plan cache
- Ripristinare una copia pulita di AdventureWorks, con tutte le 10 milioni di righe intatte,e nessun indice
- Cambia le opzioni del database a seconda dei parametri per il test corrente
- Crea un indice clustered columnstore o un indice clustered B-tree
- Aggiorna manualmente le statistiche sulla tabella, solo per essere sicuri
- Log che abbiamo iniziato il test
- Determinare quante iterazioni del ciclo abbiamo bisogno, e quante righe eliminare all’interno di ogni iterazione
- Interno del ciclo:
- Determinare se abbiamo bisogno di iniziare una transazione su questa iterazione
- Eseguire la cancellazione
- Determinare se abbiamo bisogno di commettere la transazione su questa iterazione
- Determinare se abbiamo bisogno di fare un checkpoint / backup del log su questa iterazione
- Dopo il ciclo, registriamo che questo test è finito, e impegniamo tutte le transazioni non impegnate
Per eseguire effettivamente il test, non voglio farlo in Management Studio (anche sulla stessa VM), a causa di tutto l’output, il traffico extra e l’utilizzo delle risorse.Ho creato una stored procedure e ho messo anche questo in un lavoro:
Ci è voluto molto più tempo di quanto non sia comodo ammettere. In parte perché avevo originariamente incluso un test dello 0,1% per rowperloop che, in alcuni casi, richiedeva diverse ore. Così li ho rimossi dalla tabella qualche giorno dopo, e posso facilmente dire: se state rimuovendo 1.000.000 di righe, cancellare 1.000 righe alla volta è altamente improbabile che sia una scelta ottimale, indipendentemente da qualsiasi altra variabile:

(Mentre questa sembra essere un’anomalia rispetto alla maggior parte degli altri test, scommetto che non sarebbe molto più veloce che cancellare una riga o 10 righe alla volta. E infatti era più lento che cancellare metà della tabella o la maggior parte della tabella in ogni altro scenario.)
Risultati di performance
Dopo aver scartato i risultati dei test dello 0,1%, ho messo il resto in una seconda tabella metrica con le durate caricate:
Ho dovuto usare un outer join sulla tabella metrica perché alcuni test venivano eseguiti così velocemente che non c’era abbastanza tempo per catturare alcun dato. Questo significa che, per alcuni dei test più veloci, non ci sarà alcuna correlazione con altri dettagli di performance oltre alla velocità di esecuzione.
Poi ho iniziato a cercare tendenze e anomalie. Per prima cosa, ho controllato la durata e la CPU in base all’attivazione di Delayed Durability (DD) e/o Accelerated Database Recovery (ADR):
Risultati (con le anomalie evidenziate):

Sembra che la durata complessiva migliori, in media, della stessa quantità, quando una delle due opzioni è attiva (o entrambe – e quando entrambe sono attive, il picco è più basso). Sembra esserci un outlier di durata per ADR da solo che non ha influenzato la media (questo test specifico ha coinvolto la cancellazione di 9.000.000 di righe, 90.000rows alla volta, in FULL recovery, su una tabella rowstore). Anche l’outlier della CPU per DD non ha influenzato la media – questo esempio specifico era la cancellazione di 1.000.000 di righe, tutte in una volta, su una tabella columnstore.
Che dire delle differenze complessive confrontando rowstore e columnstore?
Risultati:

Columnstore è il 20% più lento, in media, ma richiede meno memoria. Volevo anche vedere l’impatto sulla dimensione e l’utilizzo dei file di dati e di log:
Risultati:

Infine, sull’hardware di oggi, la cancellazione in blocchi non sembra avere gli stessi benefici di una volta, almeno in termini di durata. I 18 risultati più veloci qui, e 72 dei 100 più veloci, erano test in cui tutte le righe venivano cancellate in un colpo solo, rivelati da questa query:
Risultati:
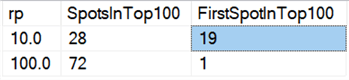
E se guardiamo le medie di tutti i dati, come in questa query:
Vediamo che l’eliminazione di tutte le righe in una volta sola, indipendentemente dal fatto che stiamo eliminando il 10%, il 50% o il 90%, è più veloce dell’eliminazione a pezzi in qualsiasi modo (di nuovo, in media):
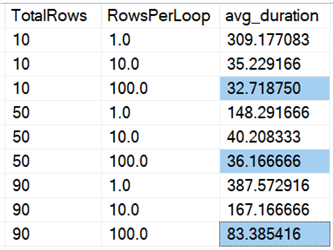
In forma di grafico:
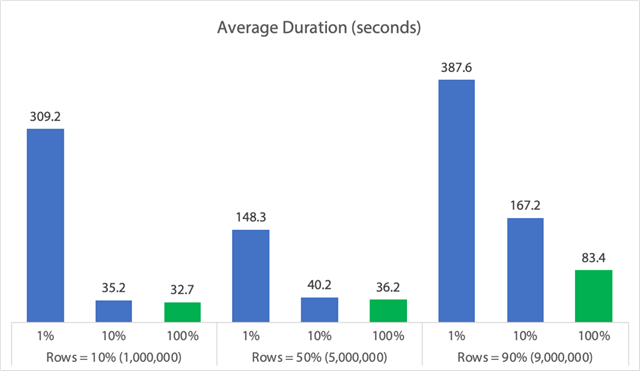
(Si noti che se togliamo il max_durationoutlier di 6.062 secondi identificato prima, la prima colonna scende da 309 secondi a 162 secondi.)
Ora, anche nel caso migliore, sono ancora 33, 36, o 83 secondi in cui adelete è in esecuzione e potenzialmente blocca tutti gli altri, e questo sta ignorando altri impatti misurati come la memoria, il file di log, la CPU e così via. La durata certamente non dovrebbe essere il vostro unico criterio; succede solo che di solito è la prima (e talvolta unica) cosa che la gente guarda. Questo test harness aveva lo scopo di mostrare che si possono e si dovrebbero catturare anche diverse altre metriche, e i risultati mostrano che gli outlier possono provenire da qualsiasi parte.
Utilizzando questo harness come modello, potete costruire i vostri test focalizzati più strettamente sui vincoli e le capacità del vostro ambiente. Non ho attaccato le metriche da tutte le angolazioni possibili, dato che ci sono un sacco di permutazioni, ma ho intenzione di tenere questo database in giro. Quindi, se ci sono altri modi in cui volete vedere i dati affettati, fatemelo sapere nei commenti qui sotto, e vedrò cosa posso fare. Solo non chiedetemi di eseguire di nuovo tutti i test.
Caveats
Tutto questo non considera un carico di lavoro concorrente, l’impatto dei vincoli di tabella come le chiavi esterne, la presenza di trigger, e una miriade di altri possibili scenari.Un’altra cosa da testare (potenzialmente in un futuro suggerimento) è avere più lavori che interagiscono con questa stessa tabella durante l’operazione, e misurare cose come la durata del blocco, i tipi e i tempi di attesa, e valutare in quali situazioni un set di attività ha un impatto più drammatico sull’altro set.
Passi successivi
Continua a leggere per suggerimenti correlati e altre risorse:
- Operazioni CRUD in SQL Server
- Differenze tra cancellare e troncare in SQL Server
- Eliminare i dati storici da una grande tabella di database SQL Server altamente concorrente
- Frammentare grandi operazioni di cancellazione in blocchi
- SQL Server Clustered e Nonclustered Columnstore Index Example
- Delayed Durability in SQL Server 2014
- Delayed Durability while Purging Data
- Accelerated Database Recovery in SQL Server 2019
.
Last Updated: 2019-12-03


Chi è l’autore
 Aaron Bertrand (@AaronBertrand) è un appassionato tecnologo con esperienza nel settore che risale al Classic ASP e SQL Server 6.5. È caporedattore del blog sulle prestazioni, SQLPerformance.com, e scrive anche su sqlblog.org.
Aaron Bertrand (@AaronBertrand) è un appassionato tecnologo con esperienza nel settore che risale al Classic ASP e SQL Server 6.5. È caporedattore del blog sulle prestazioni, SQLPerformance.com, e scrive anche su sqlblog.org.Vedi tutti i miei consigli
- Altri consigli per SQL Server DBA…