
By: Aaron Bertrand | Frissítve: Aaron Bertrand | Frissítve: Aaron Bertrand Megjelent: 2019-12-03 | Hozzászólások (1) | Kapcsolódó: 2019-12-03 | Comments (1) | Related: > Teljesítményhangolás
probléma
Néhány évvel ezelőtt blogoltam arról, hogyan lehet csökkenteni a tranzakciós naplóra gyakorolt hatást a törlési műveletek darabokra bontásával. Ahelyett, hogy 100 000 sort törölnél egyetlen nagy tranzakcióban, törölhetsz 100 vagy 1000 vagy tetszőleges számú sort egyszerre több kisebb tranzakcióban, egy ciklusban. Amellett, hogy csökkentheti a naplóra gyakorolt hatást, megkönnyítheti a hosszú ideig tartó blokkolást. Akkoriban az SSD-k még csak most kezdtek teret nyerni, és az olyan újabb technológiák, mint aClustered Columnstore Indexes, Delayed Durability ésAccelerated Database Recovery még nem léteztek. Ezért úgy gondoltam, itt az ideje egy frissítésnek, hogy jobb képet adjak arról, hogyan alakul ez az SQL Server2019-ben.
megoldás
A tábla nagy részeinek törlése nem mindig az egyetlen megoldás. Ha egy táblázat 95%-át törli és 5%-át megtartja, valójában gyorsabb lehet, ha a megtartani kívánt sorokat egy új táblázatba helyezi át, a régi táblázatot elhagyja, és az újat átnevezi. vagy a megtartott sorokat kimásolja, a táblázatot lemetszi, majd visszamásolja őket. De még akkor is, ha a törlés sokkal nagyobb, mint a megtartás, ez nem mindig lehetséges a táblára vonatkozó egyéb korlátozások, SLA-k és egyéb tényezők miatt.
Mégis, ha kiderül, hogy sorokat kell törölni, akkor minimalizálni kell a tranzakciós naplóra gyakorolt hatást, és azt, hogy a műveletek hogyan befolyásolják a munkaterhelés többi részét.A darabolásos megközelítés nem új vagy újszerű ötlet, de jól működhet néhány ilyen újabb technológiával, ezért tegyük őket próbára különböző kombinációkban.
A beállításhoz több konstansunk van, amelyek minden tesztnél igazak lesznek:
- SQL Server 2019 RC1, négy maggal és 32 GB RAM-mal (maximális szervermemória =28 GB)
- 10 millió soros tábla
- Újraindítjuk az SQL Servert minden teszt után (a memória, pufferek visszaállításához, és plancache)
- Egy olyan biztonsági mentés visszaállítása, amelynél a statisztikák már frissítve voltak és az automatikus statisztikák ki voltak kapcsolva(hogy megakadályozzuk, hogy a kiváltott statisztikák frissítései zavarják a törlési műveleteket)
Még sok változónk van, amelyek tesztenként változnak:
Ez 864 egyedi tesztet fog eredményezni, és jobb, ha elhiszed, hogy mindezeket a permutációkat automatizálom.
És a mérőszámok, amiket mérni fogunk:
- A teljes időtartam
- átlagos/csúcs CPU-használat
- átlagos/csúcs memóriahasználat
- Tranzakciós naplóhasználat/fájlnövekedés
- adatbázis fájlhasználat, verziótároló mérete (gyorsított adatbázis-helyreállítás használata esetén)
- Delta rowgroup size (Columnstore használata esetén)
Source Table
Először is visszaállítottam az AdventureWorks egy példányát (AdventureWorks2017.bak,hogy pontos legyek). A 10 millió soros tábla létrehozásához készítettem egy másolatot a Sales.SalesOrderDetail,a saját azonosító oszlopával, és hozzáadtam egy töltelékoszlopot, csak hogy minden sornak egy kicsit több húst adjak, és csökkentsem az oldalsűrűséget:
CREATE TABLE dbo.SalesOrderDetailCopy
(
SalesOrderDetailID int IDENTITY,
SalesOrderID int,
CarrierTrackingNumber nvarchar(25),
OrderQty smallint,
ProductID int,
SpecialOfferID int,
UnitPrice money,
UnitPriceDiscount money,
LineTotal numeric(38,6),
rowguid uniqueidentifier,
ModifiedDate datetime,
filler char(50) NOT NULL DEFAULT ''
);
GO
Ezután a 10.000.000 sor létrehozásához egyszerre 100.000 sort szúrtam be, és 100-szor hajtottam végre a beszúrást:
INSERT dbo.SalesOrderDetailCopy
(
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
)
SELECT TOP(100000)
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
FROM Sales.SalesOrderDetail;GO 100
Nem hoztam létre indexeket a táblán; a tárolási megközelítéstől függően,minden teszt részeként új fürtözött indexet (oszloptároló fele) hozok létre az adatbázis visszaállítása után.
Tesztek automatizálása
Mihelyt a 10 millió soros tábla létezett, beállítottam néhány opciót, biztonsági mentést készítettem az adatbázisról,kétszer mentettem a naplót, majd ismét biztonsági mentést készítettem az adatbázisról (hogy a naplónak a lehető legkevesebb használt helye legyen a visszaállításkor):
A következő lépésben létrehoztam egy Control adatbázist, ahol tárolni fogom a tárolt eljárásokat, amelyek lefuttatják a teszteket, és a táblákat, amelyek a teszteredményeket (csak az egyes tesztek kezdő és befejező időpontját) és az összes teszt során rögzített teljesítménymutatókat tartalmazzák.
A végrehajtani kívánt 864 teszt permutációinak rögzítése néhány próbálkozásba került, de végül ezt kaptam:
A várakozásoknak megfelelően ez 864 sort illesztett be az összes kombinációval.
A következő lépésben létrehoztam egy tárolt eljárást a korábban leírt mérőszámok rögzítésére.A példányt aSentryOne SQL Sentry-vel is figyelemmel kísérem, így ott minden bizonnyal más érdekes információk is rendelkezésre állnak majd, de a fontos részleteket harmadik féltől származó eszközök használata nélkül is szerettem volna rögzíteni. Íme az eljárás, amely mindent megtesz azért, hogy egy adott időbélyegre vonatkozóan az összes mérőszámot egyetlen sorban állítsa elő:
Ezt a tárolt eljárást egy feladatlépésbe helyeztem és elindítottam. Lehet, hogy a három másodperctől eltérő késleltetést szeretne használni – a gyűjtés költsége és az adatok teljessége között kompromisszumot kell kötni, ami az Ön számára inkább az egyik, mint a másik irányba hajlik.
Végül létrehoztam az eljárást, amely tartalmazza az összes logikát, hogy pontosan meghatározza, mit kell tenni a paraméterek kombinációjával minden egyes teszt esetében.Ez megint több iterációt igényelt, de a végeredmény a következő:
Túl sok minden történik itt, de az alapvető logika a következő:
- A teszt-specifikus adatokat (TestID és az összes paraméter) a dbo.Teststable
- Adjunk az SQL Server-nek egy rúgást egy sp_configure módosítással és a pufferekés a terv gyorsítótár törlésével
- Töltsük vissza az AdventureWorks tiszta másolatát, mind a 10 millió sor érintetlenül,és indexek nélkül
- Változtassa meg az adatbázis beállításait az aktuális teszt paramétereitől függően
- Hozzon létre egy fürtözött oszloptároló indexet vagy egy fürtözött B-fa indexet
- Felfrissítse manuálisan a tábla statisztikáit, csak a biztonság kedvéért
- Naplózzuk, hogy elindítottuk a tesztet
- Meghatározzuk, hány ismétlésre van szükségünk a ciklusban, és hány sort kell törölnünk az egyes ismétléseken belül
- A cikluson belül:
- Meghatározzuk, hogy kell-e tranzakciót indítanunk ebben az iterációban
- Törlés végrehajtása
- Meghatározzuk, hogy kell-e tranzakciót végrehajtanunk ebben az iterációban
- Meghatározzuk, hogy kell-e ellenőrzőpontot / biztonsági mentést készítenünk a naplóban ebben az iterációban
- A ciklus után, naplózzuk, hogy ez a teszt befejeződött, és commitoljuk a még nem commitolt tranzakciókat
A teszt tényleges futtatásához nem szeretném ezt a Management Studio-ban csinálni(még ugyanazon a VM-en sem), az összes kimenet, extra forgalom és erőforrás használat miatt.Létrehoztam egy tárolt eljárást, és ezt is beletettem egy feladatba:
Ez sokkal tovább tartott, mint amit szívesen bevallok. Ennek egy része azért volt, mert eredetileg egy 0,1%-os tesztet építettem be a rowperloophoz, ami egyes esetekben több órát vett igénybe. Ezért ezeket néhány nap múlva eltávolítottam a táblázatból, és könnyen kijelenthetem: ha 1 000 000 sort távolít el, akkor az egyszerre 1 000 sor törlése nagy valószínűséggel nem optimális választás, függetlenül bármely más változótól:

(Bár ez a legtöbb más teszthez képest anomáliának tűnik, fogadok, hogy nem lenne sokkal gyorsabb, mint egyszerre egy sor vagy 10 sor törlése. És valójában lassabb volt, mint a táblázat felének vagy nagy részének törlése minden más forgatókönyvben.)
Teljesítményeredmények
A 0,1%-os tesztek eredményeinek elvetése után a többit egy második metrikai táblázatba tettem a betöltött időtartamokkal:
A metrikai táblázaton külső csatlakozást kellett használnom, mert néhány teszt olyan gyorsan futott, hogy nem volt elég idő az adatok rögzítésére. Ez azt jelenti, hogy néhány gyorsabb teszt esetében nem lesz semmilyen korreláció más teljesítményadatokkal azon kívül, hogy milyen gyorsan futottak.
Aztán elkezdtem trendeket és anomáliákat keresni. Először az időtartamot és a CPU-t ellenőriztem aszerint, hogy a késleltetett tartósság (DD) és/vagy a gyorsított adatbázis-helyreállítás (ADR) engedélyezve volt-e:
Eredmények (az anomáliák kiemelésével):

Úgy tűnik, hogy az általános időtartam átlagosan körülbelül ugyanannyit javul, ha bármelyik opció be van kapcsolva (vagy mindkettő – és ha mindkettő engedélyezve van, a csúcsérték alacsonyabb). Úgy tűnik, hogy csak az ADR esetében van egy kiugró időtartam, amely nem befolyásolja az átlagot (ez a konkrét teszt 9 000 000 sor törlését jelentette, egyszerre 90 000 sorral, FULL recovery-ben, egy rowstore táblán). A DD CPU kiugró értéke szintén nem befolyásolta az átlagot – ez a konkrét példa 1 000 000 sor egyszerre történő törlése volt egy columnstore táblán.
Mi a helyzet az általános különbségekkel a rowstore és a columnstore összehasonlításában?
Eredmények:

A columnstore átlagosan 20%-kal lassabb, de kevesebb memóriát igényelt. Azt is látni akartam, hogy milyen hatással van az adatfájl és a naplófájl méretére és használatára:
Eredmények:

Végezetül, a mai hardvereken a darabokban való törlés nem tűnik olyan előnyösnek, mint régen, legalábbis az időtartamot tekintve. A 18 leggyorsabb eredmény itt, és a 100 leggyorsabbból 72 olyan teszt volt, ahol az összes sort egyszerre töröltük, ez derül ki ebből a lekérdezésből:
Eredmények:
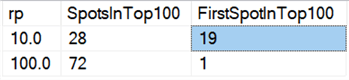
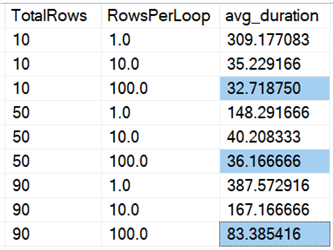
És ha az összes adatra vonatkozó átlagokat nézzük, mint ebben a lekérdezésben:
Azt látjuk, hogy az összes sor egyszerre történő törlése, függetlenül attól, hogy 10%, 50% vagy 90% törlést hajtunk végre, gyorsabb, mint a törlések bármilyen módon történő tagolása (ismét csak átlagosan):
Grafikon formájában:
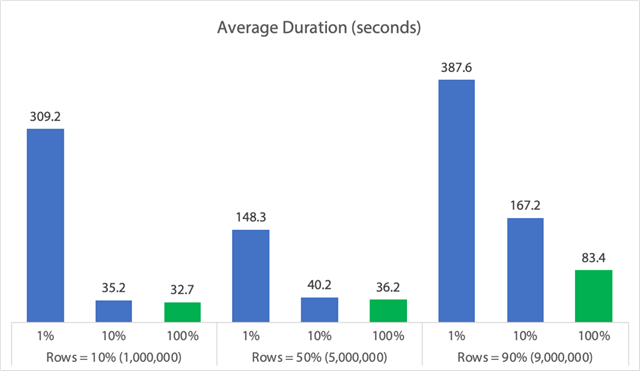
(Vegyük észre, hogy ha kivesszük a korábban azonosított 6,062 másodperces max_durationoutlier-t, az első oszlop 309 másodpercről 162 másodpercre csökken.)
Most ez még a legjobb esetben is 33, 36 vagy 83 másodpercet jelent, amikor az adelete fut, és potenciálisan mindenki mást blokkol, és ez figyelmen kívül hagyja a többi mért hatást, mint például a memória, a naplófájl, a CPU és így tovább. Az időtartamnak semmiképpen sem szabadna az egyetlen kritériumnak lennie; csak történetesen általában ez az első (és néha az egyetlen) dolog, amit az emberek megnéznek. Ennek a tesztkészletnek az volt a célja, hogy megmutassa, hogy számos más mérőszámot is meg lehet és meg kell ragadnia, és az eredmények azt mutatják, hogy a kiugró értékek bárhonnan származhatnak.
Ezt a tesztkészletet modellként használva megalkothatja saját tesztjeit, amelyek szűkebben a környezetében lévő korlátokra és képességekre összpontosítanak. Nem támadtam meg a metrikákat minden lehetséges szögből, mivel ez sok permutáció, de ezt az adatbázist megtartom. Szóval, ha van más módja is annak, hogy az adatokat felszeletelve lásd, csak szólj nekem az alábbi megjegyzésekben, és meglátom, mit tehetek. Csak ne kérd, hogy futtassam le újra az összes tesztet.
Caveats
Ez mind nem veszi figyelembe az egyidejű munkaterhelést, a táblázatkorlátozások hatását, mint például az idegen kulcsok, a triggerek jelenlétét és egy csomó más lehetséges forgatókönyvet.Egy másik dolog, amit tesztelhetünk (esetleg egy jövőbeli tippben), az az, hogy több munkánk is van, amelyek a művelet során ugyanazzal a táblával lépnek kapcsolatba, és olyan dolgokat mérünk, mint a blokkolási időtartamok, várakozási típusok és idők, és felmérjük, hogy mely helyzetekben van az egyik tevékenységkészletnek drámaibb hatása a másikra.
Következő lépések
Lapozzon tovább a kapcsolódó tippekért és egyéb forrásokért:
- CRUD műveletek az SQL Serverben
- A törlés és a törlés közötti különbségek az SQL Serverben
- Történeti adatok törlése egy nagy, nagymértékben párhuzamos SQL Server adatbázis-táblából
- A nagy törlési műveletek darabokra bontása
- SQL Server klaszterezett és nem klaszterezett oszloptároló index példája
- Késleltetett tartósság az SQL Server 2014-ben
- Késleltetett tartósság az adatok törlése során
- Begyorsított adatbázis-helyreállítás az SQL Server 2019-ben
.
Mutolsó frissítés:


A szerzőről
 Aaron Bertrand (@AaronBertrand) szenvedélyes technológus, aki a Classic ASP és az SQL Server 6.5 óta rendelkezik ipari tapasztalattal. Ő a teljesítményhez kapcsolódó SQLPerformance.com blog főszerkesztője, és blogol az sqlblog.org oldalon is.
Aaron Bertrand (@AaronBertrand) szenvedélyes technológus, aki a Classic ASP és az SQL Server 6.5 óta rendelkezik ipari tapasztalattal. Ő a teljesítményhez kapcsolódó SQLPerformance.com blog főszerkesztője, és blogol az sqlblog.org oldalon is.Minden tippem megtekintése
- Még több SQL Server DBA tipp…