
- Get Access to top ML Projects
- Koneoppimishankkeet aloittelijoille vuonna 2021
- Myynnin ennustaminen käyttäen Walmartin tietokokonaisuutta
- BigMartin myynnin ennustamisen ML-hanke
- Musiikin suosittelujärjestelmä Projekti
- Human Activity Recognition using Smartphone Dataset
- Stock Prices Predictor using TimeSeries
- Predicting Wine Quality using Wine Quality Dataset
- MNIST Käsinkirjoitettujen numeroiden luokittelu
- Learn to build Recommender Systems with Movielens Dataset
- Boston Housing Price Prediction ML Project
- Sosiaalisen median tunneanalyysi Twitterin avulla Dataset
- Iris Flowers Classification ML Project
- Retail Price Optimization using Machine Learning
- Customer Churn Prediction Analysis
- 1. Myynnin ennustaminen Walmart-tietokannan avulla
- 2. BigMart Sales Prediction ML Project – Opi valvomattomista koneoppimisen algoritmeista
- Musiikin suosittelujärjestelmäprojekti
- Human Activity Recognition using Smartphone Dataset
- Stock Prices Predictor using TimeSeries
- Viinin laadun ennustaminen viinin laatutietokannan avulla
- MNIST:n käsinkirjoitettujen numeroiden luokittelu
- Opi rakentamaan suosittelujärjestelmiä Movielens-tietokannan avulla
- Bostonin asuntojen hintojen ennustamisen ML-projekti
- Sosiaalisen median sentimenttianalyysi Twitterin datasetin avulla
- Iris Flowers Classification ML Project- Learn about Supervised Machine Learning Algorithms
- Koneoppimisprojektit aloittelijoille lähdekoodilla Pythonissa 2021
- 12) Vähittäiskaupan hintojen optimointi ML-projekti – dynaaminen hinnoittelun koneoppimismalli dynaamisille markkinoille
- 13) Customer Churn Prediction Analysis Using Ensemble Techniques in Machine Learning
- Miten aloitan koneoppimisprojektien aloittamisen?
- 1) Ensimmäinen vaihe: Koneoppimisprojektin skopiointi
- 2) Toinen vaihe: Data
- 3) Kolmas vaihe – Mallin rakentaminen
- 4) Neljäs vaihe – Mallin käyttöönotto tuotantoon
- Miten saat koneoppimisprojektit ansioluetteloosi?
- Mitä seuraavaksi?
Get Access to top ML Projects
×
Päivitetty viimeksi: 05 Mar 2021

Haluat oppia koneoppimista, mutta sinulla on vaikeuksia päästä sen kanssa alkuun. Kirjat ja kurssit eivät ehkä vain riitä, kun kyse on koneoppimisesta, vaikka niissä annetaan aina esimerkkejä koneoppimisen koodeista ja pätkistä, et saa tilaisuutta toteuttaa koneoppimista todellisiin ongelmiin ja nähdä, miten nämä koodinpätkät sopivat yhteen. Paras tapa päästä alkuun koneoppimisen oppimisessa on toteuttaa alkeis- tai edistyneen tason koneoppimisprojekteja. On aina hyödyllistä saada tietoa siitä, miten todelliset ihmiset aloittavat uransa koneoppimisen parissa toteuttamalla kokonaisvaltaisia ML-projekteja.
Tässä blogikirjoituksessa saat selville, miten kaltaisesi aloittelijat voivat edetä hienosti koneoppimisen soveltamisessa reaalimaailman ongelmiin näillä upeilla alan asiantuntijoiden suosittelemilla koneoppimisprojekteilla aloittelijoille. ProjectPron alan asiantuntijat ovat kuratoineet huolellisesti luettelon aloittelijoille suunnatuista parhaista koneoppimisprojekteista, jotka kattavat koneoppimisen keskeiset osa-alueet, kuten valvotun oppimisen, valvomattoman oppimisen, syväoppimisen ja neuroverkot. Kaikissa näissä koneoppimisprojekteissa käytät aluksi todellisia tietokokonaisuuksia, jotka ovat julkisesti saatavilla. Vakuutamme, että pidät tätä blogia ehdottoman mielenkiintoisena ja lukemisen arvoisena, koska voit oppia täältä kaikenlaista suosituimmista koneoppimisprojekteista.
”Mitä projekteja voin tehdä koneoppimisen avulla?” Meiltä kysytään tätä kysymystä usein paljon aloittelijoilta, jotka aloittavat koneoppimisen parissa. ProjectPro-alan asiantuntijat suosittelevat, että tutustut jännittäviin, siisteihin, hauskoihin ja helppoihin koneoppimisprojekti-ideoihin eri liiketoiminta-aloilla saadaksesi käytännön kokemusta oppimistasi koneoppimisen taidoista. Olemme kuratoineet luettelon innovatiivisista ja mielenkiintoisista koneoppimisprojekteista lähdekoodeineen koneoppimisen parissa uraansa aloittaville ammattilaisille. Nämä koneoppimisen aloittelevat projektit ovat täydellinen sekoitus erityyppisiä haasteita, joihin voi törmätä työskennellessään koneoppimisinsinöörinä tai datatieteilijänä.
Koneoppimishankkeet aloittelijoille vuonna 2021
-
Myynnin ennustaminen käyttäen Walmartin tietokokonaisuutta
-
BigMartin myynnin ennustamisen ML-hanke
-
Musiikin suosittelujärjestelmä Projekti
-
Human Activity Recognition using Smartphone Dataset
-
Stock Prices Predictor using TimeSeries
-
Predicting Wine Quality using Wine Quality Dataset
-
MNIST Käsinkirjoitettujen numeroiden luokittelu
-
Learn to build Recommender Systems with Movielens Dataset
-
Boston Housing Price Prediction ML Project
-
Sosiaalisen median tunneanalyysi Twitterin avulla Dataset
-
Iris Flowers Classification ML Project
-
Retail Price Optimization using Machine Learning
-
Customer Churn Prediction Analysis
Let’s dive in!

1. Myynnin ennustaminen Walmart-tietokannan avulla
Myynnin ennustaminen on yksi yleisimmistä koneoppimisen käyttötapauksista tuotteen myyntiin vaikuttavien tekijöiden tunnistamiseksi ja tulevien myyntimäärien arvioimiseksi. Tässä koneoppimisprojektissa hyödynnetään Walmartin tietokokonaisuutta, jossa on myyntitietoja 98 tuotteesta 45 myyntipisteestä. Tietokanta sisältää myyntiä myymäläkohtaisesti ja osastoittain viikoittain. Tämän koneoppimishankkeen tavoitteena on ennustaa myyntiä kunkin osaston osalta kussakin myyntipisteessä, jotta voidaan tehdä parempia tietoon perustuvia päätöksiä kanavien optimointia ja varaston suunnittelua varten. Haasteellista Walmart-tietokannan kanssa työskentelyssä on se, että se sisältää valikoituja markdown-tapahtumia, jotka vaikuttavat myyntiin ja jotka olisi otettava huomioon.
Tämä on yksi yksinkertaisimmista ja hienoimmista koneoppimishankkeista, jossa rakennat ennustavan mallin käyttäen Walmartin tietokokonaisuutta arvioidaksesi, kuinka paljon myyntiä he aikovat tehdä tulevaisuudessa, ja näin se tapahtuu –
- Tuo datan ja tutki sitä ymmärtääksesi datan sisällä olevan rakenteen ja arvot – Aloita tuomalla CSV-tiedosto ja suorittamalla perustason tutkimusdata-analyysi (EDA).
- Valmista tiedot mallintamista varten – Yhdistä useita tietokokonaisuuksia ja sovella ryhmittelytoimintoa tietojen analysoimiseksi.
- Plottaa aikasarjakuvaaja ja analysoi se.
- Sovita kehitetyt myynnin ennustemallit harjoitusaineistoon- Luo ARIMA-malli aikasarjan ennustamista varten
- Vertaile kehitettyjä malleja testiaineistoon.
- Optimoi myynnin ennustemallit valitsemalla tärkeät piirteet tarkkuuspistemäärän parantamiseksi.
- Hyödynnä parasta koneoppimismallia seuraavan vuoden myynnin ennustamiseen.
Työskenneltyäsi tämän Kaggle-koneoppimisprojektin parissa ymmärrät, miten tehokkaat koneoppimismallit voivat tehdä myynnin ennustamisen kokonaisprosessista yksinkertaisen. Käytä näitä kokonaisvaltaisia myynnin ennustamisen koneoppimismalleja uudelleen tuotannossa minkä tahansa tavaratalon tai vähittäiskaupan myynnin ennustamiseen.
Tahdotko työskennellä Walmart Dataset -tietokannan kanssa? Pääset käsiksi tämän mahtavan koneoppimisprojektin täydelliseen ratkaisuun täältä – Walmart Store Sales Forecasting Machine Learning Project
2. BigMart Sales Prediction ML Project – Opi valvomattomista koneoppimisen algoritmeista
BigMart-myyntitietokanta koostuu vuoden 2013 myyntitiedoista, jotka koskevat 1559:ää tuotetta 10:ssä eri kaupungissa sijaitsevassa myyntipisteessä. BigMart-myynnin ennustaminen ML-projektin tavoitteena on rakentaa regressiomalli, jolla ennustetaan kunkin 1559 tuotteen myyntiä seuraavana vuonna jokaisessa 10 eri BigMart-myymälässä. BigMartin myyntitietokanta koostuu myös tietyistä attribuuteista kunkin tuotteen ja myymälän osalta. Tämä malli auttaa BigMartia ymmärtämään tuotteiden ja myymälöiden ominaisuuksia, jotka ovat tärkeässä roolissa kokonaismyynnin kasvattamisessa.
Täältä pääset tämän ML-projektin täydelliseen ratkaisuun – BigMartin myynnin ennustaminen koneoppimisprojektin ratkaisu
Musiikin suosittelujärjestelmäprojekti
Tämä on yksi suosituimmista koneoppimisprojektien projekteista, ja sitä voidaan käyttää eri aloilla. Suosittelujärjestelmä saattaa olla sinulle hyvin tuttu, jos olet käyttänyt jotakin E-commerce-sivustoa tai elokuva-/musiikkisivustoa. Useimmissa sähköisen kaupankäynnin sivustoissa, kuten Amazonissa, järjestelmä suosittelee kassalla tuotteita, jotka voidaan lisätä ostoskoriin. Vastaavasti Netflixissä tai Spotifyssa järjestelmä näyttää pitämiesi elokuvien perusteella samankaltaisia elokuvia tai kappaleita, joista saatat pitää. Miten järjestelmä tekee tämän? Tämä on klassinen esimerkki, jossa koneoppimista voidaan soveltaa.
Tässä projektissa käytämme Aasian johtavan musiikin suoratoistopalvelun tietokokonaisuutta rakentaaksemme paremman musiikkisuosittelujärjestelmän. Yritämme määrittää, mistä uudesta kappaleesta tai uudesta artistista kuulija voisi pitää hänen aiempien valintojensa perusteella. Ensisijaisena tehtävänä on ennustaa, kuinka todennäköistä on, että käyttäjä kuuntelee kappaletta toistuvasti tietyn ajan kuluessa. Tietoaineistossa ennuste merkitään 1:ksi, jos käyttäjä on kuunnellut samaa kappaletta kuukauden sisällä. Dataset koostuu siitä, minkä kappaleen mikäkin käyttäjä on kuunnellut ja mihin aikaan.
Tahdotko rakentaa suosittelujärjestelmän – tutustu tähän ratkaistuun ML-projektiin täällä – Music Recommendation Machine Learning Project
Human Activity Recognition using Smartphone Dataset
Älypuhelintietoaineisto koostuu 30:n ihmisen kuntoilutoimintatallenteista, jotka on otettu älypuhelimella, jossa on inertia-anturit. Tämän koneoppimisprojektin tavoitteena on rakentaa luokittelumalli, jolla voidaan tarkasti tunnistaa ihmisen kuntoilutoiminnot. Tämän koneoppimisprojektin työstäminen auttaa sinua ymmärtämään, miten moniluokitusongelmia ratkaistaan.
Saa pääsy tähän ML-projektien lähdekoodiin täältä Human Activity Recognition using Smartphone Dataset Project
Klikkaa tästä nähdäksesi luettelon 50+ ratkaistusta, end-to-end Big Data- ja koneoppimisprojektiratkaisuja (uudelleenkäytettävää koodia + videoita)
Stock Prices Predictor using TimeSeries
Tämä on toinen mielenkiintoinen koneoppimisprojekti-idea datatieteilijöille/koneoppimisinsinööreille, jotka työskentelevät tai suunnittelevat työskentelyä finanssialan kanssa. Osakekurssien ennustaja on järjestelmä, joka oppii yrityksen suorituskyvystä ja ennustaa tulevia osakekursseja. Osakekurssidatan kanssa työskentelyyn liittyvät haasteet liittyvät siihen, että se on hyvin yksityiskohtaista, ja lisäksi on olemassa erityyppisiä tietoja, kuten volatiliteetti-indeksejä, hintoja, maailmanlaajuisia makrotaloudellisia indikaattoreita, perusindikaattoreita ja paljon muuta. Yksi hyvä puoli pörssidatan parissa työskentelyssä on se, että rahoitusmarkkinoiden palautesyklit ovat lyhyempiä, joten data-asiantuntijoiden on helpompi validoida ennusteensa uusien tietojen perusteella. Aloittaaksesi työskentelyn pörssidatan parissa voit tarttua yksinkertaiseen koneoppimisongelmaan, kuten 6 kuukauden kurssimuutosten ennustamiseen perustuen perusindikaattoreihin organisaatioiden neljännesvuosiraportista. Voit ladata osakemarkkinatietoaineistoja Quandl.comista tai Quantopian.comista. On olemassa erilaisia aikasarjan ennustemenetelmiä osakekurssin, kysynnän jne. ennustamiseen.
Katso tämä koneoppimisprojekti, jossa opit määrittelemään, mitä ennustemenetelmää kannattaa käyttää milloin ja miten sitä sovelletaan aikasarjan ennustamisen esimerkin avulla. Osakekurssien ennustaminen aikasarjaprojektin avulla
Viinin laadun ennustaminen viinin laatutietokannan avulla
On tunnettu tosiasia, että mitä vanhempi viini on, sitä paremman makuinen se on. Viinin laadun sertifiointiin vaikuttavat kuitenkin useat muutkin tekijät kuin ikä, joita ovat muun muassa fysiokemialliset testit, kuten alkoholin määrä, kiinteä happamuus, haihtuva happamuus, tiheyden määritys ja pH. Tämän koneoppimisprojektin päätavoitteena on rakentaa koneoppimismalli, jolla voidaan ennustaa viinien laatua tutkimalla niiden erilaisia kemiallisia ominaisuuksia. Viinin laatua koskeva tietokokonaisuus koostuu 4898 havainnosta, joissa on 11 riippumatonta ja 1 riippuvainen muuttuja.
Saa pääsy tämän koneoppimisprojektin täydelliseen ratkaisuun täältä – Viinin laadun ennustaminen R:llä
MNIST:n käsinkirjoitettujen numeroiden luokittelu
Syvällä oppimisella ja neuroverkoilla on elintärkeä rooli kuvantunnistuksessa, automaattisessa tekstinmuodostuksessa ja jopa itsestään ajavissa autoissa. Jos haluat aloittaa työskentelyn näillä aloilla, sinun on aloitettava yksinkertaisesta ja hallittavasta tietokokonaisuudesta, kuten MNIST-tietokokonaisuudesta. On vaikeaa työskennellä kuvadatan kanssa tasaisen relaatiodatan sijaan, ja aloittelijana ehdotamme, että voit poimia ja ratkaista MNIST Handwritten Digit Classification Challenge -haasteen. MNIST-tietokanta on liian pieni mahtuakseen tietokoneen muistiin ja aloittelijaystävällinen. Käsinkirjoitettujen numeroiden tunnistaminen tulee kuitenkin haastamaan sinut.
Tehdäksesi klassisen sisääntulon kuvantunnistusongelmien ratkaisemiseen pääset käsiksi täydelliseen ratkaisuun täältä – MNIST Handwritten Digit Classification Project
Opi rakentamaan suosittelujärjestelmiä Movielens-tietokannan avulla
Nettflixistä Huluun tarve rakentaa tehokas elokuvasuosittelujärjestelmä on kasvanut yhä tärkeämmäksi ajan mittaan, kun nykyaikaiset kuluttajat haluavat yhä enemmän räätälöityä sisältöä. Yksi suosituimmista verkossa saatavilla olevista dataseteistä, joiden avulla aloittelijat voivat opetella suosittelujärjestelmien rakentamista, on Movielens Dataset, joka sisältää noin 1 000 209 Movielens-käyttäjän tekemää elokuva-arviota 3900 elokuvasta. Voit aloittaa työskentelyn tämän datasetin kanssa rakentamalla elokuvanimikkeiden maailmanpilven visualisoinnin elokuvasuositusjärjestelmän rakentamiseksi.
Vapaa pääsy ratkaistuihin koodiesimerkkeihin löytyy täältä (nämä ovat valmiita käytettäväksi ML-projekteissasi)
Bostonin asuntojen hintojen ennustamisen ML-projekti
Bostonin asuntojen hintojen datasetti koostuu asuntojen hinnoista Bostonin eri puolilla. Tietokokonaisuus koostuu myös tiedoista, jotka koskevat muun kuin vähittäiskaupan alueita (INDUS), rikollisuutta (CRIM), talon omistavien henkilöiden ikää (AGE) ja useita muita attribuutteja (tietokokonaisuudessa on yhteensä 14 attribuuttia). Boston Housing -tietokannan voi ladata UCI Machine Learning Repository -palvelusta. Tämän koneoppimishankkeen tavoitteena on ennustaa uuden asunnon myyntihinta soveltamalla koneoppimisen peruskäsitteitä asuntojen hintatietoihin. Tämä tietokokonaisuus on liian pieni, sillä siinä on 506 havaintoa, ja sitä pidetään hyvänä lähtökohtana koneoppimisen aloittelijoille, jotta he voivat aloittaa käytännön harjoittelun regressiokäsitteisiin.
Suositeltava lukeminen – 15+ Data Science -projektia aloittelijoille
Sosiaalisen median sentimenttianalyysi Twitterin datasetin avulla
Sosiaalisen median alustat, kuten Twitter, Facebook, YouTube ja Reddit, tuottavat valtavia määriä isoa dataa, jota voidaan louhia monin eri tavoin, jotta voidaan ymmärtää trendejä, julkisia tunteita ja mielipiteitä. Sosiaalisen median datasta on nykyään tullut merkityksellistä brändäyksen, markkinoinnin ja koko liiketoiminnan kannalta. Sentimenttianalysaattori oppii koneoppimisen avulla erilaisia tunteita ”sisältöpalasen” (joka voi olla pikaviesti, sähköposti, twiitti tai mikä tahansa muu sosiaalisen median viesti) takana ja ennustaa niitä tekoälyn avulla.Twitter-dataa pidetään lopullisena lähtökohtana aloittelijoille, jotka haluavat harjoitella sentimenttianalyysin koneoppimisongelmia. Twitter-tietokannan avulla voidaan saada kiehtova sekoitus twiitin sisältöä ja muita siihen liittyviä metatietoja, kuten hashtageja, uudelleentwiittauksia, sijaintia, käyttäjiä ja muita tietoja, jotka tasoittavat tietä oivaltavalle analyysille. Twitter-tietokanta koostuu 31 962 twiitistä, ja sen koko on 3 Mt. Twitter-datan avulla saat selville, mitä maailma sanoo jostakin aiheesta, olipa kyse sitten elokuvista, Yhdysvaltain vaaleja koskevista mielipiteistä tai mistä tahansa muusta trenditietoaiheesta, kuten FIFA:n vuoden 2018 MM-kisojen voittajan ennustamisesta. Työskentely Twitter-tietokannan kanssa auttaa sinua ymmärtämään sosiaalisen median tiedonlouhintaan liittyviä haasteita ja oppimaan perusteellisesti myös luokittelijoista. Tärkein ongelma, jonka parissa voit aloittaa työskentelyn aloittelijana, on mallin rakentaminen twiittien luokittelemiseksi positiivisiksi tai negatiivisiksi.
Vapaa pääsy ratkaistuun koodiin Python- ja R-esimerkit löytyvät täältä (nämä ovat valmiita Data Science- ja ML-projekteihisi)
Iris Flowers Classification ML Project- Learn about Supervised Machine Learning Algorithms
Tämä on yksi yksinkertaisimmista koneoppimishankkeista Iris Flowersin ollessa luokittelukirjallisuuden yksinkertaisin koneoppimisen datasetti. Tätä koneoppimisen ongelmaa kutsutaan usein koneoppimisen ”Hello Worldiksi”. Aineistossa on numeerisia attribuutteja, ja ML-aloittelijoiden on selvitettävä, miten tietoja ladataan ja käsitellään. Iirisdataset on pieni, joka mahtuu helposti muistiin eikä vaadi aluksi mitään erityisiä muunnoksia tai skaalausta.
Irisdataset on ladattavissa UCI ML Repository – Download Iris Flowers Dataset
Tämän koneoppimisprojektin tavoitteena on luokitella kukat kolmeen lajiin – virginica, setosa tai versicolor – terälehtien ja verholehtien pituuden ja leveyden perusteella.
Vapaa pääsy ratkaistuihin koneoppimisen Python- ja R-koodiesimerkkeihin löytyy täältä (nämä ovat käyttövalmiita projekteihisi)
Koneoppimisprojektit aloittelijoille lähdekoodilla Pythonissa 2021
12) Vähittäiskaupan hintojen optimointi ML-projekti – dynaaminen hinnoittelun koneoppimismalli dynaamisille markkinoille
Hinnoittelukilpailut kasvavat keskeytyksettä jokaisella toimialan vertikaalisella osa-alueella, ja hinnoittelun optimoiminen on avain voittojen tehokkaaseen hallitsemiseen jokaiselle yritykselle. Kohtuullisen hinta-alueen tunnistaminen ja tuotteiden hinnoittelun mukauttaminen myynnin lisäämiseksi ja samalla voittomarginaalien pitäminen optimaalisena on aina ollut suuri haaste vähittäiskaupan alalla. Nopein tapa, jolla vähittäiskauppiaat voivat nykyään varmistaa korkeimman ROI:n ja samalla optimoida hinnoittelua, on hyödyntää koneoppimisen voimaa tehokkaiden hinnoitteluratkaisujen rakentamisessa. Verkkokaupan jättiläinen Amazon oli yksi varhaisimmista koneoppimisen hyödyntäjistä vähittäishintojen optimoinnissa, mikä osaltaan vaikutti sen huikeaan kasvuun 30 miljardista vuonna 2008 noin 1 biljoonaan vuonna 2019.

Image Credit: spd. group
100+ Datasets for Machine Learning Projects Curated Specially For You
Vähittäiskaupan hinnoittelun optimointiongelman ratkaiseminen koneellisella oppimismenetelmällä edellyttää, että koulutetaan koneellinen oppimismalli, joka kykenee hinnoittelemaan tuotteet automaattisesti siten, kuin ihmiset hinnoittelisivat ne. Vähittäismyyntihintojen optimoinnin koneoppimismallit ottavat huomioon historialliset myyntitiedot, tuotteiden erilaiset ominaisuudet ja muut strukturoimattomat tiedot, kuten kuvat ja tekstimuotoiset tiedot, oppiakseen hinnoittelusäännöt ilman ihmisen väliintuloa auttaen vähittäiskauppiaita sopeutumaan dynaamiseen hinnoitteluympäristöön maksimoidakseen liikevaihdon menettämättä voittomarginaaleja. Vähittäismyyntihintojen optimoinnin koneoppimisalgoritmi käsittelee äärettömän määrän hinnoitteluskenaarioita valitakseen tuotteelle optimaalisen hinnan reaaliajassa ottamalla huomioon tuhansia tuotteen sisällä olevia latentteja suhteita.
Katso tämä hieno koneoppimisprojekti vähittäismyyntihintojen optimoinnista, jossa pääset syvälle tosielämän myyntidatan analyysiin kahvilassa, jossa rakennat kokonaisvaltaisen koneoppimisratkaisun, joka ehdottaa automaattisesti oikeita tuotehintoja.
13) Customer Churn Prediction Analysis Using Ensemble Techniques in Machine Learning
Asiakkaat ovat yrityksen suurin voimavara, ja asiakkaiden säilyttäminen on tärkeää mille tahansa yritykselle tulojen kasvattamiseksi ja pitkäaikaisen merkityksellisen asiakassuhteen rakentamiseksi. Lisäksi uuden asiakkaan hankkiminen maksaa viisi kertaa enemmän kuin olemassa olevan asiakkaan säilyttäminen. Asiakkaiden vaihtuvuus on yksi liiketoiminnan tunnetuimmista ongelmista, kun asiakkaat tai tilaajat lakkaavat asioimasta palvelun tai yrityksen kanssa. Ihannetapauksessa he lakkaavat olemasta maksava asiakas. Asiakkaan sanotaan poistuneen, jos tietty aika on kulunut siitä, kun asiakas oli viimeksi vuorovaikutuksessa yrityksen kanssa.
Kriittinen tekijä poistuman vähentämisessä on sen tunnistaminen, jos ja kun asiakas poistuu, ja asiakkaan säilyttämiseen tähtäävän toimintakelpoisen tiedon nopea toimittaminen. Aivojemme ei ole mahdollista ennakoida miljoonien asiakkaiden irtisanoutumista, ja tässä koneoppiminen voi auttaa. Koneellinen oppiminen tarjoaa tehokkaita menetelmiä, joilla voidaan tunnistaa poistuman taustalla olevat tekijät, ja ennakoivia työkaluja, joilla siihen voidaan puuttua. Koneoppimisen algoritmeilla on tärkeä rooli ennakoivassa poistuman hallinnassa, sillä ne paljastavat sellaisten asiakkaiden käyttäytymismalleja, jotka ovat jo lopettaneet palvelujen käytön tai tuotteiden ostamisen. Tämän jälkeen koneoppimismallit tarkistavat nykyisten asiakkaiden käyttäytymistä tällaisia malleja vasten, jotta voidaan tunnistaa potentiaaliset irtisanoutujat.

Image Credit. :gallery.azure.ai
Mutta miten lähteä liikkeelle asiakkaiden irtisanoutumisasteen ennustamiseen liittyvän koneoppimisongelman ratkaisemisesta? Kuten minkä tahansa muun koneoppimisongelman kohdalla, datatieteilijöiden tai koneoppimisinsinöörien on kerättävä ja valmisteltava tiedot käsittelyä varten. Jotta mikä tahansa koneoppimisen lähestymistapa olisi tehokas, datan suunnittelu oikeassa muodossa on järkevää. Feature Engineering on luovin osa churn-ennusteen koneoppimismallia, jossa data-asiantuntijat käyttävät kokemustaan, liiketoimintakontekstiaan, datan toimialatuntemustaan ja luovuuttaan luodakseen piirteitä ja räätälöidäkseen koneoppimismallin ymmärtämään, miksi asiakkaan vaihtuvuus tapahtuu tietyssä liiketoiminnassa.
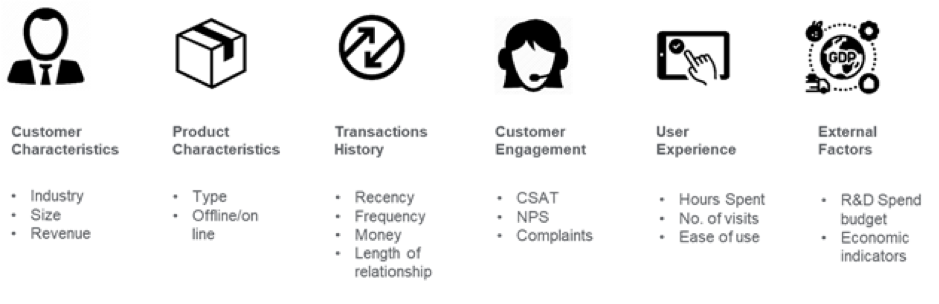
Kuvan luotto: medium.com
Pankkialalla esimerkiksi kahta asiakastiliä, joilla on sama kuukausittainen saldoluvun loppusaldon suuruusluokitus, voi olla vaikea erottaa toisistaan churn-ennusteen kannalta. Ominaisuustekniikka voi kuitenkin lisätä aikaulottuvuuden tähän dataan, jotta ML-algoritmit voivat erottaa, jos kuukausittainen loppusaldo on poikennut siitä, mitä asiakkaalta yleensä odotetaan. Indikaattorit, kuten käyttämättömät tilit, lisääntyvät nostot, käyttösuuntaukset ja saldon nettovirtaukset viimeisten päivien aikana, voivat olla varhaisia varoitusmerkkejä irtisanoutumisesta. Nämä sisäiset tiedot yhdistettynä ulkoisiin tietoihin, kuten kilpailijoiden tarjouksiin, voivat auttaa ennustamaan asiakkaiden poistuman. Kun piirteet on tunnistettu, seuraava vaihe on ymmärtää, miksi asiakaspoistumisia tapahtuu liiketoimintakontekstissa, ja poistaa piirteet, jotka eivät ole vahvoja ennusteita, ulottuvuuden vähentämiseksi.
Katso tämä Python-kielinen kokonaisvaltainen koneoppimisprojekti lähdekoodin kera, jonka aiheena on Asiakkaiden asiakaspoistumisten ennusteanalyysi Ensemble-oppimisen avulla asiakaspoistumisten torjumiseksi.
Miten aloitan koneoppimisprojektien aloittamisen?
Kään hanke ei suju menestyksekkäästi ilman vankkaa suunnitelmaa, eikä koneoppiminen ole tässä mielessä poikkeus. Ensimmäisen koneoppimisprojektin rakentaminen ei itse asiassa ole niin vaikeaa kuin miltä se näyttää, kunhan sinulla on vankka suunnittelustrategia. Minkä tahansa ML-projektin aloittamiseksi on noudatettava kattavaa päästä päähän -lähestymistapaa alkaen projektin rajauksesta mallin käyttöönottoon ja hallintaan tuotannossa Tässä on näkemyksemme koneoppimisprojektin suunnitelman perusvaiheista, jotta voit varmistaa, että otat kaiken irti jokaisesta ainutlaatuisesta projektista –
1) Ensimmäinen vaihe: Koneoppimisprojektin skopiointi
Ennen kaikkea muuta, ymmärrä, mitkä ovat ML-projektin liiketoimintavaatimukset. ML-projektia aloitettaessa perustavanlaatuinen vaihe on relevantin liiketoiminnallisen käyttötapauksen valitseminen, jota varten koneoppimismalli rakennetaan. Oikean koneoppimisen käyttötapauksen valitseminen ja sen ROI:n arviointi on tärkeää minkä tahansa koneoppimisprojektin onnistumisen kannalta.
2) Toinen vaihe: Data
Data on minkä tahansa koneoppimismallin elinehto, ja koneoppimismallia on mahdotonta kouluttaa ilman dataa. Data-vaihe koneoppimisprojektin elinkaaressa on nelivaiheinen prosessi –
-
Datavaatimukset – Ymmärrys siitä, millaista dataa tarvitaan, datan muoto, tietolähteet ja tietolähteiden vaatimustenmukaisuusvaatimukset ovat tärkeitä.
-
Datan kerääminen – Tietokantahallinnoijien, data-arkkitehtien tai -kehittäjien avulla on määritettävä datan keräysstrategiasi, jotta voit poimia dataa paikoista, joissa se sijaitsee organisaatiossa, tai muilta ulkopuolisilta toimittajilta.
-
Exploratiivinen data-analyysi – Tässä vaiheessa on pohjimmiltaan kyse datavaatimusten validoinnista sen varmistamiseksi, että sinulla on oikeat tiedot, tiedot ovat hyvässä kunnossa ja niissä ei ole virheitä.
-
Datan valmistelu – Tässä vaiheessa on kyse datan valmistelemisesta koneoppimisalgoritmien käyttöön. Virheiden korjaaminen, ominaisuuksien suunnittelu, koodaus koneiden ymmärtämiin dataformaatteihin ja poikkeavuuksien korjaaminen ovat datan valmisteluun liittyviä tehtäviä.
3) Kolmas vaihe – Mallin rakentaminen
Projektin luonteesta riippuen tämä vaihe voi kestää muutaman päivän tai kuukauden. Mallintamisvaiheessa tehdään päätös siitä, mitä koneoppimisalgoritmia käytetään, ja aloitetaan mallin harjoittelu datalla. Mallin valinnassa on tärkeää ymmärtää, mitä tarkkuuden, virheen ja oikeellisuuden mittoja koneoppimismallin tulisi noudattaa. Kun olet kouluttanut mallin, arvioit sitä validointidatalla, jotta voit analysoida sen suorituskykyä ja estää ylisovittamisen. Mallin arviointi on kriittinen vaihe, sillä jos malli toimii täydellisesti aiemmilla tiedoilla ja palauttaa huonon suorituskyvyn tulevilla tiedoilla, siitä ei ole mitään hyötyä.
4) Neljäs vaihe – Mallin käyttöönotto tuotantoon
Tässä vaiheessa ohjelmisto tai sovellus otetaan käyttöön loppukäyttäjille, jotta uutta dataa voi virrata koneoppimismalliin lisäoppimista varten. Koneoppimismallin käyttöönotto ei riitä, vaan on myös varmistettava, että koneoppimismalli toimii odotetulla tavalla. Malli kannattaa kouluttaa uudestaan uusilla tuotantodatalla, jotta sen tarkkuus tai suorituskyky voidaan varmistaa – tämä on mallin virittämistä. Mallin virittäminen edellyttää myös mallin validointia sen varmistamiseksi, että se ei ajaudu tai muutu puolueelliseksi.
Miten saat koneoppimisprojektit ansioluetteloosi?
Reaalimaailman kokemus valmistaa sinua lopulliseen menestykseen paremmin kuin mikään muu. Mitä enemmän saat koneoppimisen aloittelijana reaaliaikaista kokemusta koneoppimisprojekteissa työskentelystä, sitä valmiimpi olet tarttumaan vuosikymmenen kuumimpiin työpaikkoihin. Koneoppimistyön saaminen datatieteen koulutuksen jälkeen tai menestyminen datatieteilijänä riippuu kyvystäsi myydä itseäsi. Kun olet käynyt kattavan tietojenkäsittelytieteen koulutuksen, seuraava askel huipputyöpaikan saamiseksi koneoppimisinsinöörinä tai tietojenkäsittelytieteilijänä on rakentaa erinomainen portfolio, jolla voit esitellä mahdollisille työnantajillesi kykysi soveltaa koneoppimistekniikoita. Työskentely mielenkiintoisissa ML-projekteissa on loistava tapa käynnistää urasi yrityksen koneoppimisinsinöörinä tai datatieteilijänä. Työnantajat haluavat nähdä, millaisten datatieteeseen ja koneoppimiseen liittyvien projektien parissa olet työskennellyt arvioidakseen kykyjesi laajuutta datatieteen ja koneoppimisen tekemisessä. Joidenkin hauskojen, siistien ja mielenkiintoisten datatieteen ja koneoppimisen hanke-esimerkkien korostamisella ansioluettelossasi on enemmän painoarvoa kuin sillä, että kerrot, kuinka paljon tiedät. Näin voit lisätä mahtavia projekteja koneoppimisen ansioluetteloosi –
- Koneoppimisen ansioluettelossa voit mainita koneoppimisen projektit heti työkokemusta käsittelevän osion jälkeen.
- Seuraa juoksevaa numerointijärjestystä yhdessä niiden projektien otsikoiden kanssa, joiden parissa olet työskennellyt.
- Projektin otsikon jälkeen on hyvä kertoa lyhyesti tietokokonaisuudesta ja ongelmanratkaisusta.
- mainitse koneoppimisen työkalut ja teknologiat, joita käytit projektin loppuunsaattamiseen.
- Viimeiseksi, mutta ei vähäisimpänä, linkitä portfoliossasi/ansioluettelossasi kukin koneoppimisprojekti GitHubiin, henkilökohtaiseen verkkosivustoosi tai blogiisi, jotta saat syvällisen käsityksen saavutuksistasi.
Halusitpa sitten rakentaa vahvan koneoppimisen portfolion tai harjoitella analyyttisiä taitoja, joita opit datatieteiden kurssillasi – meiltä saat sen. Monet koneoppimisen aloittelijat eivät ole varmoja siitä, mistä aloittaa, mitä koneoppimisprojekteja tehdä, mitä koneoppimisen työkaluja, tekniikoita ja kehyksiä käyttää. Olemme tehneet datatieteen ja koneoppimisen aloittelijoille vaivattomasta tehtävästä kuratoimalla luettelon mielenkiintoisista ideoista koneoppimishankkeiksi sekä niiden ratkaisuista. Nämä koneoppimisprojektien ideat on poimittu suosituista Kagglen datatieteen haasteista, ja ne ovat erinomainen tapa oppia koneoppimista. Tämä projektiluettelo on täydellinen tapa laittaa koneoppimisprojektit ansioluetteloosi. Oikea ajattelutapa, oppimishalukkuus ja paljon datan tutkimista tarvitaan, jotta ymmärrät datatieteen ja koneoppimisen projektien ratkaisun. Voit tutustua yli 50:een datatieteen ja ML-projektiin niiden taitojen, työkalujen ja tekniikoiden perusteella, jotka sinun on opittava.
Ennen kuin aloitat projektisi, on hyödyllistä, että sinulla on pääsy kirjastoon, jossa on koneoppimisprojektin koodiesimerkkejä. Niinpä aina kun olet jumissa projektissa, voit käyttää näitä ratkaistuja esimerkkejä päästäksesi irti.
Pääset käsiksi datatieteen ja koneoppimisen projektikoodiesimerkkeihin
Mitä seuraavaksi?
Koneoppimisen mestariksi voi tulla vain runsaalla harjoittelulla ja kokeilulla. Teoriatiedon hankkimisesta on varmasti apua, mutta juuri soveltaminen auttaa eniten edistymään. Mikään määrä teoreettista tietoa ei voi korvata käytännön harjoittelua. Auttaa kuitenkin, jos tutustut ensin edellä lueteltuihin innovatiivisiin koneoppimisprojekteihin.
Jos olet aloittelija ja uusi koneoppimisen parissa, työskentely ProjectPron alan asiantuntijoiden suunnittelemien koneoppimisprojektien parissa on parhaita sijoituksia ajastasi. Nämä projektit on suunniteltu aloittelijoille auttamaan heitä parantamaan nopeasti sovelletun koneoppimisen taitojaan samalla kun he saavat mahdollisuuden tutkia mielenkiintoisia liiketoiminnallisia käyttötapauksia eri aloilla – vähittäiskaupassa, rahoituksessa, vakuutusalalla, teollisuudessa ja monilla muilla aloilla. Jos siis haluat nauttia koneoppimisen oppimisesta, pysyä motivoituneena ja edetä nopeasti, ProjectPron mielenkiintoiset ML-projektit ovat sinua varten. Lisäksi voit lisätä näitä koneoppimisprojekteja salkkuusi ja saada huippukeikan korkeammalla palkalla ja palkitsevilla eduilla.

Klikkaa tästä nähdäksesi luettelon yli 50 ratkaistusta, kokonaisvaltaisesta projektiratkaisusta koneoppimisen ja Big Datan alalla
|
PREVIOUS |
NEXT |