
Parhaat Python-kirjastot koneoppimiseen ja syväoppimiseen
Python on yksi kehittäjäystävällisimmistä koneoppimiseen ja syväoppimiseen tarkoitetuista ohjelmointikielistä, ja sitä tukee laaja valikoima kirjastoja, jotka sopivat jokaiseen käyttötapaukseesi ja projektiisi.

● TensorFlow
Vallankumous on täällä! Tervetuloa TensorFlow 2.0.
TensorFlow on nopea, joustava ja skaalautuva avoimen lähdekoodin koneoppimiskirjasto tutkimukseen ja tuotantoon.
TensorFlow on yksi parhaista saatavilla olevista kirjastoista koneoppimisen parissa työskentelyyn Pythonilla. Googlen tarjoama TensorFlow tekee ML-mallien rakentamisesta helppoa niin aloittelijoille kuin ammattilaisillekin.
TensorFlow’n avulla voit luoda ja kouluttaa ML-malleja tietokoneiden lisäksi myös mobiililaitteilla ja palvelimilla käyttämällä TensorFlow Lite- ja TensorFlow Serving -ohjelmia, jotka tarjoavat samat hyödyt, mutta mobiilialustoille ja korkean suorituskyvyn palvelimille.
Joitakin ML:n ja DL:n keskeisiä osa-alueita, joissa TensorFlow loistaa, ovat:
● Syvien neuroverkkojen käsittely
● Luonnollisen kielen käsittely
● Osittaisdifferentiaaliyhtälöt
● Abstraktio-ominaisuudet
● Kuvan-, tekstin ja puheentunnistus
● Ideoiden ja koodin vaivaton yhteistoiminta
Ydintehtävä: Deep Learning -mallien rakentaminen
Ymmärtääksesi, miten tietty tehtävä suoritetaan TensorFlow:ssa, voit tutustua TensorFlow-oppaaseen.
● Keras
Keras on yksi suosituimmista ja avoimen lähdekoodin hermoverkkokirjastoista Pythonille. Alun perin Googlen insinööri suunnitteli Kerasin ONEIROSille, joka on lyhenne sanoista Open-Ended Neuro Electronic Intelligent Robot Operating System (avoin neuroelektroninen älykäs robottikäyttöjärjestelmä), mutta pian Keras sai tuen TensorFlow’n ydinkirjastossa, jolloin se oli käytettävissä TensorFlow’n päällä. Keras sisältää useita neuroverkon luomiseen tarvittavia rakennuspalikoita ja työkaluja, kuten seuraavat:
● Neuraalikerrokset
● Aktivointi- ja kustannusfunktiot
● Tavoitteet
● Erän normalisointi
● Pudotus
● Pooling

Keras laajentaa TensorFlow’n käytettävyyttä näillä lisäominaisuuksilla ML- ja DL-ohjelmointiin. Avulias yhteisö ja oma Slack-kanava tekevät tuen saamisen helpoksi. Tukea on myös konvoluutio- ja rekursiivisille neuroverkoille sekä tavallisille neuroverkoille. Voit myös tutustua muihin esimerkkimalleihin Keras ja Computer Vision -luokassa Stanfordissa.
Keras Cheat Sheet : https://s3.amazonaws.com/assets.datacamp.com/blog_assets/Keras_Cheat_Sheet_Python.pdf
Ydintehtävä: Build Deep Learning models
Getting Started with Keras –
● PyTorch
Facebookin kehittämä PyTorch on yksi harvoista koneoppimiskirjastoista Pythonille. Pythonin lisäksi PyTorch tukee myös C++:a sen C++-rajapinnan avulla, jos olet kiinnostunut siitä. PyTorchia pidetään kärkiehdokkaiden joukossa kilpailussa parhaasta koneoppimis- ja syväoppimiskehyksestä, ja se kohtaa kosketuskilpailun TensorFlow’n kanssa. Voit tutustua PyTorchin opetusohjelmiin muiden yksityiskohtien osalta.
Joitakin elintärkeitä ominaisuuksia, jotka erottavat PyTorchin erilaisuudeksi TensorFlow’sta, ovat:
● Tensorilaskenta, jossa on mahdollisuus nopeutettuun prosessointiin grafiikkaprosessoriyksiköiden avulla
● Helppo oppia, käyttää ja integroida muuhun Python-ekosysteemiin
● Tuki neuraaliverkoille, jotka on rakennettu nauhapohjaiseen automaattiseen diff-järjestelmään
PyTorchin mukana tulevat erilaiset moduulit, jotka auttavat neuraaliverkkojen luomisessa ja harjoittelemisessa:
● TENSORIT – TORCH.Tensor

● Optimizers – torch.optim-moduuli
● Neuraaliverkot – nn-moduuli
● Autograd
Pros: hyvin muokattavissa, laajalti käytetty syväoppimisen tutkimuksessa
Miinukset: vähemmän NLP-abstraktioita, ei ole optimoitu nopeuden suhteen
Ydintehtävä: Syväoppimismallien kehittäminen ja harjoittelu
Keras vs Tensorflow vs PyTorch | Deep Learning Frameworks Comparison
● Scikit-learn
Scikit-learn on toinen aktiivisesti käytetty koneoppimiskirjasto Pythonille. Se sisältää helpon integroinnin erilaisiin ML-ohjelmointikirjastoihin, kuten NumPy ja Pandas. Scikit-learnin mukana tulee tuki erilaisille algoritmeille, kuten esim:
● Luokittelu
● Regressio
● Klusterointi
● Dimensioiden pienentäminen
● Mallin valinta
● Esikäsittely
Rakennettu ajatuksen ympärille, että se on helppokäyttöinen mutta silti joustava, Scikit-learn keskittyy datan mallintamiseen eikä muihin tehtäviin, kuten datan lataamiseen, käsittelyyn, manipulointiin ja visualisointiin. Sitä pidetään riittävän riittävänä käytettäväksi kokonaisvaltaisena ML:nä tutkimusvaiheesta käyttöönottoon asti. Jos haluat syvällisemmän ymmärryksen scikit-learnista, voit tutustua Scikit-learnin opetusohjelmiin.
Core Task: Mallintaminen
Learn Scikit-Learn-
● Pandas
Pandas on Python-data-analyysikirjasto, ja sitä käytetään ensisijaisesti datan manipulointiin ja analysointiin. Se tulee käyttöön ennen kuin datajoukko valmistellaan harjoittelua varten. Pandas tekee aikasarjojen ja strukturoitujen moniulotteisten aineistojen kanssa työskentelystä vaivatonta koneoppimisen ohjelmoijille. Joitakin Pandasin hienoja ominaisuuksia datan käsittelyssä ovat:
● Datasetin uudelleenmuotoilu ja pivoting
● Datasettien yhdistäminen ja liittäminen
● Puuttuvan datan käsittely ja datan kohdistaminen
● Erilaiset indeksointivaihtoehdot, kuten hierarkkinen akseli-indeksointi, Fancy indexing
● Tietojen suodatusvaihtoehdot

Pandas-tietolomakkeen katkelma(lähde)
Panda-tietolomakkeen yhteydessä on mahdollista käyttää hyväksi DataFrames-ohjelmia, mikä on vain tekninen termi datan kaksiulotteiselle esittämiselle tarjoamalla ohjelmoijille DataFrame-objekteja.
Ydintehtävä: Datan käsittely ja analysointi
Google Trends – Pandojen kiinnostus ajan kuluessa

● NLTK
NLTK on lyhenne sanoista Natural Language Toolkit ja se on Python-kirjasto luonnollisen kielen käsittelyyn. Sitä pidetään yhtenä suosituimmista kirjastoista ihmiskielisen datan käsittelyyn. NLTK tarjoaa ohjelmoijille yksinkertaiset käyttöliittymät sekä laajan valikoiman leksikaalisia resursseja, kuten FrameNet, WordNet, Word2Vec ja useita muita. Joitakin NLTK:n kohokohtia ovat:
● Hakusanojen etsiminen asiakirjoista
● Tekstien tokenisointi ja luokittelu
● Äänen ja käsialan tunnistaminen
● Lemmatisointi ja Stemming of words

NLTK:ta ja sen pakettikokonaisuutta pidetään luotettavana valintana opiskelijoille, insinööreille, tutkijoille, kielentutkijoille ja kielten parissa työskenteleville teollisuudenaloille.
Core Task: Tekstinkäsittely
● Spark MLlib
MLlib on Apache Sparkin skaalautuva koneoppimiskirjasto
Apachen kehittämä Spark MLlib on koneoppimiskirjasto, joka mahdollistaa laskutoimitusten helpon skaalaamisen. Se on helppokäyttöinen, nopea, helppo ottaa käyttöön ja tarjoaa sujuvan integraation muiden työkalujen kanssa. Spark MLlibistä tuli heti kätevä työkalu koneoppimisalgoritmien ja -sovellusten kehittämiseen.
Työkalut, joita Spark MLlib tuo mukanaan, ovat:
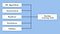
Spark Mllibin koneenoppimisen työkalut
Joitakin suosittuja algoritmeja ja API-rajapintoja, joita koneenoppimissuunnittelun parissa työskentelevät ohjelmoijat, jotka työskentelevät Spark MLlibin avulla, voivat hyödyntää, ovat:
● Regressio
● Klusterointi
● Optimointi
● Dimensioiden pelkistäminen
● Luokittelu
● Perustilastot
● Ominaisuuksien poiminta
● Theano
Theano on tehokas Python-kirjasto, jonka avulla on helppo määritellä, tehokkaiden matemaattisten lausekkeiden optimointia ja evaluointia. Joitakin ominaisuuksia, jotka tekevät Theanosta vankan kirjaston tieteellisten laskutoimitusten suorittamiseen laajassa mittakaavassa, ovat:
● Tuki grafiikkasuorittimille, jotka suoriutuvat raskaista laskutoimituksista paremmin kuin suorittimet
● Vahva integrointituki NumPy:n kanssa
● Nopeammat ja vakaat evaluoinnit hankalimmillekin muuttujille
● Mahdollisuus luoda mukautettua C-koodia matemaattisille operaatioillesi
Theanolla, voit saavuttaa joidenkin tehokkaimpien koneoppimisalgoritmien nopean kehittämisen. Theanon päälle on rakennettu joitakin tunnettuja syväoppimiskirjastoja, kuten Keras, Blocks ja Lasagne. Theanon edistyneempiä käsitteitä varten voit tutustua Theanon opetusohjelmaan.
● MXNet
Joustava ja tehokas kirjasto syväoppimiseen

MXnet – Joustava ja tehokas kirjasto syväoppimiseen
Jos osaamisalueesi on syväluennonopiskelua, löydät MXNetin sopivan täydellisesti. Syvien neuroverkkojen kouluttamiseen ja käyttöönottoon käytettävä MXNet on erittäin skaalautuva ja tukee nopeaa mallien kouluttamista. Apachen MXNet ei toimi ainoastaan Pythonin kanssa, vaan myös monien muiden kielten, kuten C++:n, Perlin, Julian, R:n, Scalan ja Gon kanssa.
MXNetin siirrettävyyden ja skaalautuvuuden ansiosta voit ottaa sen alustalta toiselle ja skaalata sen projektisi vaativien tarpeiden mukaan. Jotkut teknologian ja koulutuksen suurimmista nimistä, kuten Intel, Microsoft, MIT ja monet muut, tukevat tällä hetkellä MXNetiä. Amazonin AWS suosii MXNetiä ensisijaisena syväoppimiskehyksenä.
● Numpy

Numpy-kirjasto
Pythonin NumPy-kirjasto keskittyy laajojen moniulotteisten aineistojen ja aineistoon operoivien monimutkaisten matemaattisten funktioiden käsittelyyn. NumPy tarjoaa nopeaa laskentaa ja monimutkaisten matriiseilla toimivien funktioiden suorittamista. Muutamia NumPy:n puolesta puhuvia seikkoja ovat:
● Tuki matemaattisille ja loogisille operaatioille
● Muodonkäsittely
● Lajittelu- ja valintaominaisuudet
● Diskreetit Fourier-muunnokset
● Perus lineaarialgebra- ja tilastolliset operaatiot
● Satunnaissimuloinnit
● Tuki n-n-ulotteisille matriiseille
NumPy toimii oliosuuntautuneella lähestymistavalla ja sillä on työkaluja C:n integrointiin, C++- ja Fortran-koodia, mikä tekee NumPystä erittäin suositun tiedeyhteisön keskuudessa.
Ydintehtävä: Datan puhdistus ja käsittely
Google Trends – Numpy-kiinnostus ajan kuluessa

Johtopäätökset
Python on todella ihmeellinen kehitystyökalu, joka ei ainoastaan toimi yleisenä-tarkoituksen ohjelmointikielenä, vaan palvelee myös projektisi tai työnkulkujesi tiettyjä kapeikkoja. Runsaasti kirjastoja ja paketteja, jotka laajentavat Pythonin ominaisuuksia ja tekevät siitä monipuolisen ja täydellisen kaikille, jotka haluavat päästä kehittämään ohjelmia ja algoritmeja. Kun joitakin nykyaikaisia koneoppimisen ja syväoppimisen kirjastoja Pythonille on käsitelty lyhyesti edellä, voit saada käsityksen siitä, mitä kullakin näistä kirjastoista on tarjottavanaan ja tehdä valintasi.