
By: Aaron Bertrand | Päivitetty: Bertrand Barrond: 2019-12-03 | Comments (1) | Related: 2019-12-03 | Comments (1) | Related: > Suorituskyvyn virittäminen
Ongelma
Muutama vuosi sitten kirjoitin blogissa siitä, miten voit vähentää transaktiolokiin kohdistuvaa vaikutusta pilkkomalla poisto-operaatiot palasiksi. Sen sijaan, että poistat 100 000 riviä yhdessä suuressa transaktiossa, voit poistaa 100 tai 1 000 tai jonkin mielivaltaisen määrän rivejä kerrallaan useissa pienemmissä transaktioissa silmukassa. Sen lisäksi, että vähennät lokiin kohdistuvaa vaikutusta, voit helpottaa pitkäkestoista estämistä. Tuolloin SSD-levyt olivat vasta saamassa jalansijaa, eikä uudempia tekniikoita, kutenClustered Columnstore Indexes, Delayed Durability ja Accelerated Database Recovery, ollut vielä olemassa. Ajattelin siis, että voisi olla aika päivittää, jotta saataisiin parempi kuva siitä, miten tämä toimii SQL Server2019:ssä.
Ratkaisu
Taulukon suurten osien poistaminen ei aina ole ainoa ratkaisu. Jos poistat 95 % taulukosta ja pidät 5 %, voi itse asiassa olla nopeampaa siirtää säilytettävät rivit uuteen taulukkoon, poistaa vanha taulukko ja nimetä uusi taulukko uudelleen. tai kopioida säilytettävät rivit pois, typistää taulukko ja kopioida ne sitten takaisin. Mutta silloinkin, kun puhdistus on paljon suurempi kuin säilyttäminen, tämä ei ole aina mahdollista taulun muiden rajoitusten, SLA:iden ja muiden tekijöiden vuoksi.
Jos taas käy ilmi, että joudut poistamaan rivejä, haluat minimoida transaktiolokiin kohdistuvan vaikutuksen ja sen, miten operaatiot vaikuttavat muuhun työkuormitukseen.Pilkkominen (chunking) lähestymistapa ei ole uusi tai uudenlainen ajatus, mutta se voi toimia hyvin joidenkin uudempien tekniikoiden kanssa, joten testataan niitä erilaisissa yhdistelmissä.
Valmistelemme useita vakioita, jotka ovat totta jokaisessa testissä:
- SQL Server 2019 RC1, neljällä ytimellä ja 32 Gt RAM-muistia (palvelimen maksimimuisti =28 Gt)
- 10 miljoonan rivin taulukko
- Käynnistetään SQL Server uudelleen jokaisen testin jälkeen (muistin, puskurien nollaamiseksi, ja plancache)
- Palauta varmuuskopio, jossa tilastot oli jo päivitetty ja automaattiset tilastot poistettu käytöstä(jotta käynnistetyt tilastopäivitykset eivät häiritsisi poisto-operaatioita)
Meillä on myös monia muuttujia, jotka muuttuvat testiä kohden:
Tämä tuottaa 864 ainutlaatuista testiä, ja voitte uskoa, että aion automatisoida kaikki nämä permutaatiot.
Ja mittarit, joita mittaamme:
- Kokonaiskesto
- Keskimääräinen/huippu CPU-käyttö
- Keskimääräinen/huippu muistinkäyttö
- Transaktiolokin käyttö/tiedoston kasvu
- Tietokannan tiedostojen käyttö, versiovaraston koko (käytettäessä Accelerated DatabaseRecoverya)
- Delta rowgroup size (käytettäessä Columnstorea)
Lähdetaulukko
Aluksi palautin kopion AdventureWorksista (AdventureWorks2017.bak,tarkemmin sanottuna). Luodakseni taulukon, jossa on 10 miljoonaa riviä, tein kopion Sales.SalesOrderDetail,jolla oli oma identiteettisarake, ja lisäsin täytesarakkeen vain antaakseni jokaiselle riville hiukan enemmän lihaa ja vähentääkseni sivutiheyttä:
CREATE TABLE dbo.SalesOrderDetailCopy
(
SalesOrderDetailID int IDENTITY,
SalesOrderID int,
CarrierTrackingNumber nvarchar(25),
OrderQty smallint,
ProductID int,
SpecialOfferID int,
UnitPrice money,
UnitPriceDiscount money,
LineTotal numeric(38,6),
rowguid uniqueidentifier,
ModifiedDate datetime,
filler char(50) NOT NULL DEFAULT ''
);
GO
Sitten, luodakseni 10 000 000 riviä, lisäsin 100 000 riviä kerrallaan jarann lisäys 100 kertaa:
INSERT dbo.SalesOrderDetailCopy
(
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
)
SELECT TOP(100000)
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
FROM Sales.SalesOrderDetail;GO 100
En luonut tauluun mitään indeksejä; tallennusmenetelmästä riippuen,luon uuden klusteroidun indeksin (columnstore puolet ajasta) sen jälkeen, kun tietokantaon palautettu osana jokaista testiä.
Testien automatisointi
Kun 10 miljoonan rivin taulukko oli olemassa, asetin muutamia asetuksia, varmuuskopioin tietokannan, varmuuskopioin lokin kahdesti ja sitten varmuuskopioin tietokannan uudelleen (jotta lokissa olisi mahdollisimman vähän käytettyä tilaa palautettaessa):
Seuraavaksi loin Control-tietokannan, johon tallentaisin tallennetut proseduurit, jotka suorittaisivat testit, ja taulukot, joihin tallennettaisiin testitulokset (vain kunkin testin alku- ja loppuaika) ja kaikkien testien aikana kerätyt suorituskykymittarit.
Kaikkien niiden 864 testin permutaatioiden kaappaaminen, jotka halusin suorittaa, vei muutaman kokeilun, mutta päädyin seuraavaan tulokseen:
Odotetusti tämä lisäsi 864 riviä, jotka sisälsivät kaikki nämä yhdistelmät.
Loin seuraavaksi tallennetun proseduurin, jolla kaappasin aiemmin kuvatun joukon mittareita.Seuraan instanssia myösSentryOne SQL Sentryn avulla, joten sieltä on varmasti saatavissa muitakin mielenkiintoisia tietoja, mutta halusin myös kaapata tärkeät yksityiskohdat ilman kolmannen osapuolen työkalujen käyttöä. Tässä on proseduuri, joka tekee kaikkensa tuottaakseen kaikki metriikat mille tahansa tietylle aikaleimalle yhdelle riville:
Laitoin tuon tallennetun proseduurin job stepiin ja käynnistin sen. Saatat haluta käyttää muutakin viivettä kuin kolme sekuntia – keruukustannusten ja tietojen täydellisyyden välillä on kompromissi, joka voi kallistua sinulle enemmän yhteen suuntaan kuin toiseen.
Loin lopuksi proseduurin, joka sisältäisi kaiken logiikan, jolla määritettäisiin tarkalleen, mitä kunkin yksittäisen testin parametriyhdistelmälle tehdään.Tämäkin vaati useita iteraatioita, mutta lopputulos on seuraava:
Tässä tapahtuu paljon, mutta peruslogiikka on tämä:
- Hae testikohtaiset tiedot (TestID ja kaikki parametrit) dbo.Teststable
- Anna SQL Serverille potkua tekemällä sp_configure-muutos ja tyhjentämällä puskuritja suunnitelmavälimuisti
- Palauta puhdas kopio AdventureWorksista, jossa kaikki 10 miljoonaa riviä ovat ehjiä,ja ilman indeksejä
- Muuta tietokannan asetuksia nykyisen testin parametrien mukaan
- Luo joko klusteroitu columnstore-indeksi tai klusteroitu B-puuindeksi
- Päivitä taulun tilastotiedot manuaalisesti, varmuuden vuoksi
- Loggaa, että olemme aloittaneet testin
- Määritä, kuinka monta silmukan iteraatiota tarvitsemme ja kuinka monta riviä poistamme jokaisen iteraation sisällä
- Silmukan sisällä:
- Määritä, pitääkö meidän aloittaa transaktio tällä iteraatiolla
- Toteuta poisto
- Määritä, pitääkö meidän sitouttaa transaktio tällä iteraatiolla
- Määritä, pitääkö meidän tarkistaa piste / varmuuskopioida loki tällä iteraatiolla
- Silmukan jälkeen, kirjaamme, että tämä testi on päättynyt, ja sitoutamme kaikki sitoutumattomat transaktiot
Testin varsinaista suorittamista en halua tehdä Management Studiossa (edes samassa VM:ssä) kaiken tuotoksen, ylimääräisen liikenteen ja resurssien käytön vuoksi.Loin tallennetun proseduurin ja laitoin tämän myös tehtäväksi:
Tämä kesti paljon kauemmin kuin olen valmis myöntämään. Osittain se johtui siitä, että olin alunperin sisällyttänyt 0,1 prosentin testin rowperloopille, joka joissakin tapauksissa kesti useita tunteja. Joten poistin ne taulukosta muutaman päivän kuluttua, ja voin helposti sanoa: jos olet poistamassa 1 000 000 riviä, 1 000 rivin poistaminen kerrallaan on erittäin epätodennäköistä, että se olisi optimaalinen valinta riippumatta muista muuttujista:

(Vaikka tuo vaikuttaa poikkeavalta verrattuna useimpiin muihin testeihin, lyön vetoa, että se ei olisi paljonkaan nopeampi kuin yhden rivin tai 10 rivin poistaminen kerrallaan. Ja itse asiassa se oli hitaampaa kuin puolen taulukon tai suurimman osan taulukon poistaminen jokaisessa muussa skenaariossa.)
Suorituskykytulokset
Hylkättyäni 0,1 %:n testeistä saadut tulokset laitoin loput toiseen metriikkataulukkoon, johon oli ladattu kestot:
Minun täytyi käyttää ulompaa liitosta (outer join) metriikkataulukkoon, koska jotkin testit sujuivat niin nopeasti, ettei aika riittänyt minkään datan keräämiseen. Tämä tarkoittaa sitä, että joidenkin nopeampien testien osalta ei ole mitään korrelaatiota muiden suoritustietojen kanssa kuin se, kuinka nopeasti ne juoksivat.
Sitten aloin etsiä trendejä ja poikkeamia. Ensin tarkistin keston ja suorittimen sen perusteella, oliko käytössä Delayed Durability (DD) ja/tai Accelerated Database Recovery (ADR):
Tulokset (poikkeavuudet korostettuina):

Näyttää siltä, että kokonaiskesto paranee keskimäärin suunnilleen saman verran, kun kumpikaan vaihtoehto on käytössä (tai molemmat – ja kun molemmat ovat käytössä, huippu on pienempi). Näyttää siltä, että pelkällä ADR:llä on keston poikkeama, joka ei vaikuttanut keskiarvoon (tässä testissä poistettiin 9 000 000 riviä, 90 000 riviä kerrallaan, FULL recovery -toiminnolla rowstore-taulusta). Myöskään DD:n CPU-poikkeama ei vaikuttanut keskiarvoon – tässä nimenomaisessa esimerkissä poistettiin 1 000 000 riviä kerralla columnstore-taulusta.
Miten on yleisten erojen laita, kun verrataan rowstore- ja columnstore-tauluja?
Tulokset:

Columnstore-taulu on keskimäärin 20 %:n verran hitaampi, mutta se vaati vähemmän muistia. Halusin myös nähdä vaikutuksen datatiedoston ja lokitiedoston kokoon ja käyttöön:
Tulokset:

Loppujen lopuksi, nykylaitteistolla kappaleittain poistamisella ei näytä olevan samanlaisia hyötyjä kuin ennen, ainakaan keston suhteen. Tässä 18 nopeinta tulosta ja 72 nopeinta 100:sta olivat testejä, joissa kaikki rivit poistettiin yhdellä kertaa, mikä käy ilmi tästä kyselystä:
Tulokset:
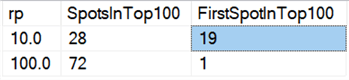
Ja jos tarkastelemme keskiarvoja koko aineistosta, kuten tässä kyselyssä:
Havaitsemme, että kaikkien rivien poistaminen kerralla riippumatta siitä, poistammeko10 %, 50 % vai 90 %, on nopeampaa kuin poistojen pilkkominen millään tavalla (jälleen kerran keskimäärin):
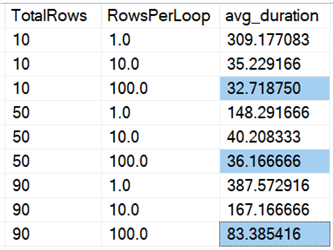
Taulukkomuodossa:
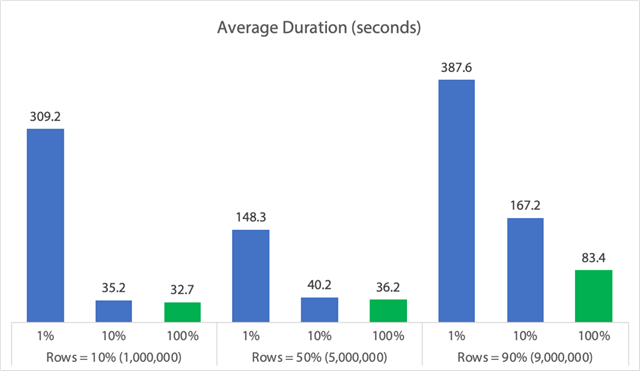
(Huomaa, että jos otamme pois aiemmin havaitun 6062 sekunnin pituisen maksimikestävyydeltään suurimman poikkeaman (maksimikestävyydeltään suurimman poikkeaman (max_durationoutlier)), ensimmäinen sarake putoaa 309:stä 162:een sekuntiin.)
Jopa parhaimmassa tapauksessa se on edelleen 33, 36 tai 83 sekuntia, jolloin adelete on käynnissä ja mahdollisesti estää kaikkia muita, ja tässä ei oteta huomioon muita mitattuja vaikutuksia, kuten muistia, lokitiedostoa, suorittimen käyttöä ja niin edelleen. Keston ei todellakaan pitäisi olla ainoa kriteeri; se on vain sattumoisin ensimmäinen (ja joskus ainoa) asia, jota ihmiset tarkastelevat. Tämän testivalikoiman tarkoituksena oli osoittaa, että myös useita muita mittareita voidaan ja pitäisikin mitata, ja tulokset osoittavat, että poikkeamat voivat tulla mistä tahansa.
Käyttämällä tätä valjastusta mallina voit rakentaa omia testejäsi, joissa keskitytään kapea-alaisemmin ympäristössäsi oleviin rajoitteisiin ja mahdollisuuksiin. En tarkastellut mittareita kaikista mahdollisista näkökulmista, koska siinä on paljon permutaatioita, mutta aion säilyttää tämän tietokannan. Jos siis haluatte nähdä datan viipaloituna muilla tavoin, kertokaa minulle alla olevissa kommenteissa, niin katson, mitä voin tehdä. Älä vain pyydä minua ajamaan kaikkia testejä uudestaan.
Caveats
Tässä kaikessa ei oteta huomioon samanaikaista työmäärää, taulukkojen rajoitusten vaikutusta, kuten vierasavaimia, triggereiden läsnäoloa ja monia muita mahdollisia skenaarioita.Toinen testattava asia (mahdollisesti tulevassa vinkissä) on ottaa käyttöön useita töitä, jotka ovat vuorovaikutuksessa saman taulukon kanssa koko operaation ajan, ja mitata asioita, kuten eston kestoaikoja, odotustyyppejä ja -aikoja, ja mitata, missä tilanteissa yhden ryhmän toiminnalla on dramaattisempi vaikutus toiseen ryhmään.
Seuraavat vaiheet
Lue lisää aiheeseen liittyviä vinkkejä ja muita resursseja:
- CRUD-operaatiot SQL Serverissä
- Poisto- ja katkaisutoimintojen erot SQL Serverissä
- Historiallisten tietojen poistaminen suuresta, erittäin samanaikaisesta SQL Server -tietokantataulukosta
- Jakauta suuret poisto-operaatiot palasiksi
- SQL Serverin klusteroidun ja klusteroimattoman Columnstore-indeksin esimerkki
- Hidastettu kestävyys SQL Server 2014:ssä
- Hidastettu kestävyys tietoja tyhjennettäessä
- Tietokannan nopeutettu palautus SQL Server 2019:ssä
Viimeisin päivitetty:

Tekijästä
 Aaron Bertrand (@AaronBertrand) on intohimoinen teknologiantuntija, jolla on kokemusta alalta Classic ASP:stä ja SQL Server 6.5:stä. Hän on suorituskykyyn liittyvän SQLPerformance.com-blogin päätoimittaja ja bloggaa myös osoitteessa sqlblog.org.
Aaron Bertrand (@AaronBertrand) on intohimoinen teknologiantuntija, jolla on kokemusta alalta Classic ASP:stä ja SQL Server 6.5:stä. Hän on suorituskykyyn liittyvän SQLPerformance.com-blogin päätoimittaja ja bloggaa myös osoitteessa sqlblog.org.Katso kaikki vinkkini
- Lisää SQL Server DBA -vinkkejä…