
- Get Access to top ML Projects
- Projekty uczenia maszynowego dla początkujących w 2021 roku
- Sales Forecasting using Walmart Dataset
- BigMart Sales Prediction ML Project
- Music Recommendation System Project
- Human Activity Recognition using Smartphone Dataset
- Stock Prices Predictor using TimeSeries
- Predicting Wine Quality using Wine Quality Dataset
- MNIST Handwritten Digit Classification
- Learn to build Recommender Systems with Movielens Dataset
- Boston Housing Price Prediction ML Project
- Social Media Sentiment Analysis using Twitter Dataset
- Iris Flowers Classification ML Project
- Retail Price Optimization using Machine Learning
- Customer Churn Prediction Analysis
- 1. Prognozowanie sprzedaży z wykorzystaniem zbioru danych Walmart
- 2. BigMart Sales Prediction ML Project – Learn about Unsupervised Machine Learning Algorithms
- Projekt systemu rekomendacji muzyki
- Human Activity Recognition using Smartphone Dataset
- Stock Prices Predictor using TimeSeries
- Predicting Wine Quality using Wine Quality Dataset
- MNIST Handwritten Digit Classification
- Learn to build Recommender Systems with Movielens Dataset
- Boston Housing Price Prediction ML Project
- Social Media Sentiment Analysis using Twitter Dataset
- Iris Flowers Classification ML Project- Learn about Supervised Machine Learning Algorithms
- Projekty uczenia maszynowego dla początkujących z kodem źródłowym w Pythonie na rok 2021
- 12) Retail Price Optimization ML Project – Dynamic Pricing Machine Learning Model for a Dynamic Market
- 13) Customer Churn Prediction Analysis Using Ensemble Techniques in Machine Learning
- How do I start a machine learning project?
- 1) Pierwszy krok: Machine Learning Project Scoping
- 2) Drugi krok: Dane
- 3) Trzeci krok – Budowanie modelu
- 4) Czwarty krok – Wdrożenie modelu do produkcji
- Jak umieścić projekty uczenia maszynowego w swoim CV?
- What Next?
Get Access to top ML Projects
×
Last Updated: 05 Mar 2021

Chcesz nauczyć się uczenia maszynowego, ale masz problem z rozpoczęciem z nim pracy. Książki i kursy mogą nie być wystarczające, jeśli chodzi o uczenie maszynowe, chociaż zawsze dają przykładowe kody uczenia maszynowego i snippety, nie masz okazji, aby wdrożyć uczenie maszynowe do rzeczywistych problemów i zobaczyć, jak te snippety kodu pasują do siebie. Najlepszym sposobem na rozpoczęcie nauki uczenia maszynowego jest wdrożenie projektów uczenia maszynowego na poziomie od początkującego do zaawansowanego. Zawsze pomocne jest uzyskanie wglądu w to, jak prawdziwi ludzie rozpoczynają swoją karierę w uczeniu maszynowym, wdrażając projekty ML end-to-end.
W tym wpisie na blogu dowiesz się, jak początkujący, tacy jak ty, mogą poczynić wielkie postępy w stosowaniu uczenia maszynowego do rzeczywistych problemów dzięki tym fantastycznym projektom uczenia maszynowego dla początkujących polecanym przez ekspertów branżowych. Eksperci branżowi ProjectPro starannie stworzyli listę najlepszych projektów uczenia maszynowego dla początkujących, które obejmują podstawowe aspekty uczenia maszynowego, takie jak uczenie nadzorowane, uczenie bez nadzoru, głębokie uczenie i sieci neuronowe. We wszystkich tych projektach uczenia maszynowego będziesz zaczynał od rzeczywistych zestawów danych, które są publicznie dostępne. Zapewniamy, że znajdziesz ten blog absolutnie interesujące i warte czytania ze względu na wszystkie rzeczy można dowiedzieć się stąd o najbardziej popularnych projektów uczenia maszynowego.
„Jakie projekty mogę zrobić z uczenia maszynowego ?” Często dostajemy to pytanie od początkujących zaczynających swoją przygodę z uczeniem maszynowym. Eksperci z branży ProjectPro zalecają, abyś poznał kilka ekscytujących, fajnych, zabawnych i łatwych pomysłów na projekty związane z uczeniem maszynowym w różnych dziedzinach biznesu, aby zdobyć praktyczne doświadczenie w zakresie umiejętności uczenia maszynowego, których się nauczyłeś. Przygotowaliśmy listę innowacyjnych i interesujących projektów uczenia maszynowego z kodem źródłowym dla profesjonalistów rozpoczynających swoją karierę w uczeniu maszynowym. Te początkujące projekty dotyczące uczenia maszynowego są doskonałą mieszanką różnych typów wyzwań, z którymi można się zetknąć, pracując jako inżynier uczenia maszynowego lub badacz danych.
Projekty uczenia maszynowego dla początkujących w 2021 roku
-
Sales Forecasting using Walmart Dataset
-
BigMart Sales Prediction ML Project
-
Music Recommendation System Project
-
Human Activity Recognition using Smartphone Dataset
-
Stock Prices Predictor using TimeSeries
-
Predicting Wine Quality using Wine Quality Dataset
-
MNIST Handwritten Digit Classification
-
Learn to build Recommender Systems with Movielens Dataset
-
Boston Housing Price Prediction ML Project
-
Social Media Sentiment Analysis using Twitter Dataset
-
Iris Flowers Classification ML Project
-
Retail Price Optimization using Machine Learning
-
Customer Churn Prediction Analysis
Zanurzmy się!

1. Prognozowanie sprzedaży z wykorzystaniem zbioru danych Walmart
Prognozowanie sprzedaży jest jednym z najczęstszych przypadków użycia uczenia maszynowego do identyfikacji czynników wpływających na sprzedaż produktu i szacowania wielkości przyszłej sprzedaży. Ten projekt uczenia maszynowego wykorzystuje zbiór danych Walmart, który zawiera dane dotyczące sprzedaży 98 produktów w 45 punktach sprzedaży. Zbiór danych zawiera dane dotyczące sprzedaży w każdym sklepie, w każdym dziale w ujęciu tygodniowym. Celem tego projektu uczenia maszynowego jest prognozowanie sprzedaży dla każdego działu w każdym punkcie sprzedaży, aby pomóc im w podejmowaniu lepszych decyzji opartych na danych w celu optymalizacji kanałów i planowania zapasów. Trudnym aspektem pracy z zestawem danych Walmart jest to, że zawiera on wybrane zdarzenia obniżki cen, które wpływają na sprzedaż i powinny być brane pod uwagę.
Jest to jeden z najprostszych i najfajniejszych projektów uczenia maszynowego, w którym zbudujesz model predykcyjny przy użyciu zbioru danych Walmart, aby oszacować liczbę sprzedaży, którą będą realizować w przyszłości, a oto jak –
- Import danych i ich eksploracja w celu zrozumienia struktury i wartości w danych – Rozpocznij od importu pliku CSV i wykonania podstawowej Eksploracyjnej Analizy Danych (EDA).
- Przygotuj dane do modelowania – Połącz wiele zbiorów danych i zastosuj funkcję grupowania do analizy danych.
- Określ wykres szeregu czasowego i przeanalizuj go.
- Dopasuj opracowane modele prognozowania sprzedaży do danych treningowych- Utwórz model ARIMA do prognozowania szeregów czasowych
- Porównaj opracowane modele na danych testowych.
- Optymalizuj modele prognozowania sprzedaży, wybierając ważne cechy w celu poprawy wyniku dokładności.
- Wykorzystaj najlepszy model uczenia maszynowego, aby przewidzieć przyszłoroczną sprzedaż.
Po pracy nad tym projektem uczenia maszynowego Kaggle zrozumiesz, jak potężne modele uczenia maszynowego mogą uprościć ogólny proces prognozowania sprzedaży. Wykorzystaj ponownie te kompleksowe modele uczenia maszynowego do prognozowania sprzedaży w produkcji, aby prognozować sprzedaż dla dowolnego działu lub sklepu detalicznego.
Chcesz pracować z Walmart Dataset? Uzyskaj dostęp do kompletnego rozwiązania dla tego niesamowitego projektu uczenia maszynowego tutaj – Walmart Store Sales Forecasting Machine Learning Project
2. BigMart Sales Prediction ML Project – Learn about Unsupervised Machine Learning Algorithms
Zbiór danych sprzedaży BigMart składa się z danych sprzedaży 2013 dla 1559 produktów w 10 różnych punktach sprzedaży w różnych miastach. Celem projektu BigMart sales prediction ML jest zbudowanie modelu regresji, aby przewidzieć sprzedaż każdego z 1559 produktów na następny rok w każdym z 10 różnych punktów sprzedaży BigMart. Zbiór danych o sprzedaży BigMart składa się również z określonych atrybutów dla każdego produktu i sklepu. Model ten pomaga BigMart zrozumieć właściwości produktów i sklepów, które odgrywają ważną rolę w zwiększaniu ich ogólnej sprzedaży.
Dostęp do kompletnego rozwiązania tego projektu ML tutaj – BigMart Sales Prediction Machine Learning Project Solution
Projekt systemu rekomendacji muzyki
Jest to jeden z najbardziej popularnych projektów uczenia maszynowego i może być stosowany w różnych dziedzinach. Możesz być bardzo zaznajomiony z systemem rekomendacji, jeśli używałeś jakiejkolwiek strony E-commerce lub Movie/Music website. W większości witryn e-commerce, takich jak Amazon, w momencie zakupu, system poleca produkty, które mogą być dodane do koszyka. Podobnie na Netflix lub Spotify, na podstawie filmów, które Ci się spodobały, system pokaże podobne filmy lub piosenki, które mogą Ci się spodobać. Jak system to robi? Jest to klasyczny przykład, w którym można zastosować uczenie maszynowe.
W tym projekcie wykorzystujemy zbiór danych z wiodącego w Azji serwisu streamingu muzyki, aby zbudować lepszy system rekomendacji muzycznych. Postaramy się określić, która nowa piosenka lub który nowy artysta może spodobać się słuchaczowi na podstawie jego wcześniejszych wyborów. Podstawowym zadaniem jest przewidzenie szansy na to, że użytkownik będzie słuchał danej piosenki wielokrotnie w określonym czasie. W zbiorze danych, przewidywanie jest oznaczone jako 1, jeśli użytkownik słuchał tego samego utworu w ciągu miesiąca. Zbiór danych składa się z informacji o tym, która piosenka została wysłuchana przez którego użytkownika i w jakim czasie.
Chcesz zbudować system rekomendacji – sprawdź ten rozwiązany projekt ML tutaj – Music Recommendation Machine Learning Project
Human Activity Recognition using Smartphone Dataset
Zbiór danych smartfonów składa się z nagrań aktywności fitness 30 osób przechwyconych przez smartfony wyposażone w czujniki inercyjne. Celem tego projektu uczenia maszynowego jest zbudowanie modelu klasyfikacyjnego, który może precyzyjnie zidentyfikować aktywność fizyczną człowieka. Praca nad tym projektem uczenia maszynowego pomoże Ci zrozumieć, jak rozwiązywać problemy wieloklasowości.
Uzyskaj dostęp do kodu źródłowego tego projektu ML tutaj Human Activity Recognition using Smartphone Dataset Project
Kliknij tutaj, aby zobaczyć listę 50+ rozwiązanych, end-to-end Big Data and Machine Learning Project Solutions (reusable code + videos)
Stock Prices Predictor using TimeSeries
Jest to kolejny ciekawy pomysł na projekt związany z uczeniem maszynowym dla naukowców/inżynierów uczenia maszynowego pracujących lub planujących pracę w dziedzinie finansów. Predyktor cen akcji jest systemem, który uczy się o wynikach firmy i przewiduje przyszłe ceny akcji. Wyzwania związane z pracą z danymi dotyczącymi cen akcji polegają na tym, że są one bardzo ziarniste, a ponadto istnieją różne rodzaje danych, takie jak indeksy zmienności, ceny, globalne wskaźniki makroekonomiczne, wskaźniki fundamentalne i inne. Jedną dobrą rzeczą w pracy z danymi giełdowymi jest to, że rynki finansowe mają krótsze cykle sprzężenia zwrotnego, co ułatwia ekspertom danych, aby potwierdzić swoje prognozy na nowych danych. Aby rozpocząć pracę z danymi giełdowymi, możesz wybrać prosty problem uczenia maszynowego, taki jak przewidywanie 6-miesięcznych ruchów cenowych na podstawie wskaźników fundamentalnych z raportu kwartalnego organizacji. Możesz pobrać zestawy danych giełdowych z Quandl.com lub Quantopian.com. Istnieją różne metody prognozowania szeregów czasowych do prognozowania cen akcji, popytu, itp.
Sprawdź ten projekt uczenia maszynowego, w którym nauczysz się określać, która metoda prognozowania ma być używana, kiedy i jak ją zastosować na przykładzie prognozowania szeregów czasowych. Stock Prices Predictor using TimeSeries Project
Predicting Wine Quality using Wine Quality Dataset
Wiadomo, że im starsze wino, tym lepszy smak. Jednakże, istnieje kilka czynników innych niż wiek, które idą do certyfikacji jakości wina, które obejmują badania fizjochemiczne, takie jak ilość alkoholu, kwasowość stała, kwasowość lotna, określenie gęstości, pH, i więcej. Głównym celem tego projektu uczenia maszynowego jest zbudowanie modelu uczenia maszynowego do przewidywania jakości win poprzez zbadanie ich różnych właściwości chemicznych. Zbiór danych dotyczących jakości wina składa się z 4898 obserwacji z 11 zmiennymi niezależnymi i 1 zmienną zależną.
Uzyskaj dostęp do kompletnego rozwiązania tego projektu uczenia maszynowego tutaj – Wine Quality Prediction in R
MNIST Handwritten Digit Classification
Głębokie uczenie i sieci neuronowe odgrywają istotną rolę w rozpoznawaniu obrazów, automatycznym generowaniu tekstu, a nawet samojeżdżących samochodach. Aby rozpocząć pracę w tych dziedzinach, należy zacząć od prostego i łatwego w zarządzaniu zbioru danych, takiego jak MNIST. Praca z danymi obrazowymi jest trudniejsza niż z płaskimi danymi relacyjnymi, dlatego jako początkujący sugerujemy wybranie i rozwiązanie zadania MNIST Handwritten Digit Classification Challenge. Zbiór danych MNIST jest zbyt mały, aby zmieścić się w pamięci komputera, i przyjazny dla początkujących. Jednakże, rozpoznawanie pisma odręcznego będzie dla Ciebie wyzwaniem.
Zrób klasyczne wejście w rozwiązywanie problemów z rozpoznawaniem obrazów, uzyskując dostęp do kompletnego rozwiązania tutaj – MNIST Handwritten Digit Classification Project
Learn to build Recommender Systems with Movielens Dataset
Od Netflix do Hulu, potrzeba zbudowania efektywnego systemu rekomendacji filmów zyskała na znaczeniu wraz z rosnącym zapotrzebowaniem współczesnych konsumentów na treści dostosowane do ich potrzeb. Jednym z najpopularniejszych zbiorów danych dostępnych w sieci dla początkujących użytkowników systemów rekomendacyjnych jest Movielens Dataset, który zawiera około 1,000,209 ocen 3,900 filmów wystawionych przez 6,040 użytkowników Movielens. Możesz rozpocząć pracę z tym zbiorem danych budując wizualizację world-cloud tytułów filmów, aby zbudować system rekomendacji filmów.
Darmowy dostęp do rozwiązanych przykładów kodu można znaleźć tutaj (są one gotowe do użycia w Twoich projektach ML)
Boston Housing Price Prediction ML Project
Boston House Prices Dataset składa się z cen domów w różnych miejscach w Bostonie. Zbiór danych zawiera również informacje o obszarach działalności niedetalicznej (INDUS), wskaźniku przestępczości (CRIM), wieku osób posiadających dom (AGE) i kilku innych atrybutach (zbiór danych ma w sumie 14 atrybutów). Zbiór danych Boston Housing można pobrać z Repozytorium UCI Machine Learning. Celem tego projektu jest przewidzenie ceny sprzedaży nowego domu poprzez zastosowanie podstawowych pojęć uczenia maszynowego do danych o cenach mieszkań. Ten zbiór danych jest zbyt mały i zawiera 506 obserwacji i jest uważany za dobry początek dla początkujących w uczeniu maszynowym, aby rozpocząć swoją praktyczną praktykę w zakresie koncepcji regresji.
Recommended Reading – 15+ Data Science Projects for Beginners
Social Media Sentiment Analysis using Twitter Dataset
Platformy mediów społecznościowych takie jak Twitter, Facebook, YouTube, Reddit generują ogromne ilości dużych danych, które mogą być wydobywane na różne sposoby w celu zrozumienia trendów, nastrojów społecznych i opinii. Dane z mediów społecznościowych stały się dziś istotne dla brandingu, marketingu i biznesu jako całości. Analizator sentymentu uczy się o różnych sentymentów za „kawałek treści” (może być IM, e-mail, tweet, lub inny post social media) poprzez uczenie maszynowe i przewiduje to samo przy użyciu AI.Dane Twitter jest uważany za ostateczny punkt wejścia dla początkujących praktykować analizę sentymentu problemy uczenia maszynowego. Korzystanie z Twitter dataset, można uzyskać urzekającą mieszankę treści tweetów i innych powiązanych metadanych, takich jak hashtagi, retweets, lokalizacja, użytkowników i więcej, które torują drogę do wnikliwej analizy. Zbiór danych Twitter składa się z 31,962 tweety i jest 3MB w rozmiarze. Korzystanie z danych Twitter można dowiedzieć się, co świat mówi o temacie, czy to filmy, nastroje na temat wyborów w USA, lub inny temat trendów, jak przewidywanie, kto wygra Puchar Świata FIFA 2018. Praca z zestawem danych z Twittera pomoże Ci zrozumieć wyzwania związane z eksploracją danych z mediów społecznościowych, a także dogłębnie poznać klasyfikatory. Najważniejszym problemem, nad którym możesz zacząć pracować jako początkujący, jest zbudowanie modelu klasyfikującego tweety jako pozytywne lub negatywne.
Darmowy dostęp do rozwiązanego kodu Przykłady w języku Python i R można znaleźć tutaj (są one gotowe do użycia w Twoich projektach Data Science i ML)
Iris Flowers Classification ML Project- Learn about Supervised Machine Learning Algorithms
Jest to jeden z najprostszych projektów uczenia maszynowego z Iris Flowers będącym najprostszym zestawem danych uczenia maszynowego w literaturze dotyczącej klasyfikacji. Ten problem uczenia maszynowego jest często określany jako „Hello World” uczenia maszynowego. Zbiór danych ma atrybuty numeryczne i początkujący ML muszą dowiedzieć się, jak załadować i obsługiwać dane. Zbiór danych irysów jest niewielki, dzięki czemu łatwo mieści się w pamięci i nie wymaga żadnych specjalnych przekształceń ani skalowania, aby rozpocząć pracę.
Zbiór danych irysów można pobrać z UCI ML Repository – Download Iris Flowers Dataset
Celem tego projektu uczenia maszynowego jest sklasyfikowanie kwiatów do jednego z trzech gatunków – virginica, setosa lub versicolor na podstawie długości i szerokości płatków i działek.
Darmowy dostęp do rozwiązanych przykładów kodu uczenia maszynowego Python i R można znaleźć tutaj (są one gotowe do użycia dla twoich projektów)
Projekty uczenia maszynowego dla początkujących z kodem źródłowym w Pythonie na rok 2021
12) Retail Price Optimization ML Project – Dynamic Pricing Machine Learning Model for a Dynamic Market
Pricing races are growing non-stop across every industry vertical and optimizing the prices is the key to manage profits efficiently for any business. Identyfikacja rozsądnego przedziału cenowego i dostosowanie cen produktów w celu zwiększenia sprzedaży przy jednoczesnym zachowaniu optymalnej marży zysku zawsze było dużym wyzwaniem w branży detalicznej. Najszybszym sposobem, w jaki sprzedawcy detaliczni mogą dziś zapewnić najwyższy ROI przy jednoczesnej optymalizacji cen, jest wykorzystanie mocy uczenia maszynowego do tworzenia skutecznych rozwiązań cenowych. Gigant handlu elektronicznego Amazon był jednym z najwcześniejszych adaptatorów uczenia maszynowego w optymalizacji cen detalicznych, które przyczyniły się do jego gwiezdnego wzrostu z 30 miliardów w 2008 r. do około 1 biliona w 2019 r.

Image Credit: spd. group
100+ Datasets for Machine Learning Projects Curated Specially For You
Rozwiązanie problemu uczenia maszynowego optymalizacji cen detalicznych wymaga szkolenia modelu uczenia maszynowego zdolnego do automatycznego ustalania cen produktów w sposób, w jaki byłyby one wyceniane przez ludzi. Modele uczenia maszynowego optymalizacji cen detalicznych uwzględniają historyczne dane dotyczące sprzedaży, różne cechy produktów oraz inne niestrukturalne dane, takie jak obrazy i informacje tekstowe, aby nauczyć się zasad ustalania cen bez interwencji człowieka, pomagając sprzedawcom detalicznym dostosować się do dynamicznego środowiska cenowego w celu maksymalizacji przychodów bez utraty marży zysku. Optymalizacja cen detalicznych algorytm uczenia maszynowego przetwarza nieskończoną liczbę scenariuszy cenowych, aby wybrać optymalną cenę dla produktu w czasie rzeczywistym, biorąc pod uwagę tysiące ukrytych relacji w produkcie.
Sprawdź ten fajny projekt uczenia maszynowego na temat optymalizacji cen detalicznych, aby głęboko zanurzyć się w rzeczywistej analizie danych sprzedażowych dla kawiarni, w której zbudujesz kompleksowe rozwiązanie uczenia maszynowego, które automatycznie sugeruje właściwe ceny produktów.
13) Customer Churn Prediction Analysis Using Ensemble Techniques in Machine Learning
Klienci są największym atutem firmy, a utrzymanie klientów jest ważne dla każdej firmy, aby zwiększyć przychody i zbudować długotrwałe, znaczące relacje z klientami. Co więcej, koszt pozyskania nowego klienta jest pięciokrotnie wyższy niż koszt utrzymania istniejącego klienta. Customer Churn/Attrition jest jednym z najbardziej uznanych problemów w biznesie, gdzie klienci lub subskrybenci przestają robić interesy z usługą lub firmą. W idealnym przypadku, przestają być płatnymi klientami. Klient mówi się, że jest churned jeśli określona ilość czasu minęła od ostatniej interakcji klienta z firmą.
Identyfikacja, czy i kiedy klient będzie churn i szybkie dostarczanie informacji actionable mające na celu utrzymanie klienta jest krytyczna dla zmniejszenia churn. Nasze mózgi nie są w stanie przewidzieć rezygnacji klientów w przypadku milionów klientów, w czym może pomóc uczenie maszynowe. Uczenie maszynowe dostarcza skutecznych metod identyfikacji czynników leżących u podstaw rezygnacji oraz narzędzi proskrypcyjnych do jej rozwiązania. Algorytmy uczenia maszynowego odgrywają istotną rolę w proaktywnym zarządzaniu rezygnacją, ponieważ ujawniają wzorce zachowań klientów, którzy już przestali korzystać z usług lub kupować produkty. Następnie modele uczenia maszynowego sprawdzają zachowanie istniejących klientów względem takich wzorców, aby zidentyfikować potencjalnych klientów rezygnujących z usług.

Image Credit. :gallery.azure.ai
Ale jak zacząć od rozwiązania problemu uczenia maszynowego przewidywania wskaźnika rezygnacji klienta? Podobnie jak w przypadku każdego innego problemu związanego z uczeniem maszynowym, naukowcy zajmujący się danymi lub inżynierowie uczenia maszynowego muszą zebrać i przygotować dane do przetwarzania. Aby każde podejście do uczenia maszynowego było skuteczne, sensowne jest zaprojektowanie danych w odpowiednim formacie. Inżynieria funkcji to najbardziej kreatywna część modelu uczenia maszynowego przewidywania rezygnacji, w której specjaliści ds. danych wykorzystują swoje doświadczenie, kontekst biznesowy, znajomość domeny danych i kreatywność, aby stworzyć cechy i dostosować model uczenia maszynowego, aby zrozumieć, dlaczego rezygnacja klienta ma miejsce w konkretnym biznesie.
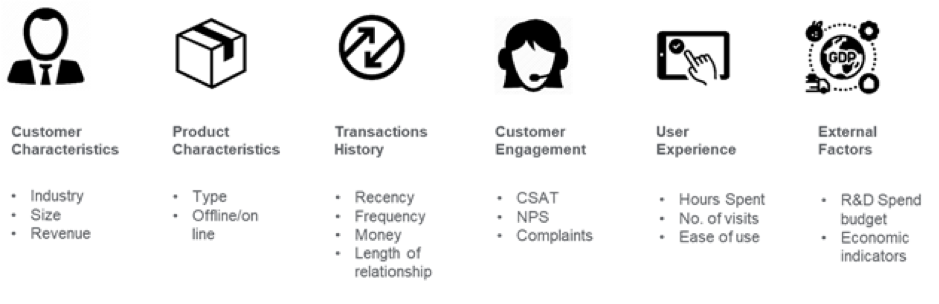
Image Credit: medium.com
Na przykład w branży bankowej dwa konta, które mają takie samo miesięczne saldo końcowe, mogą być trudne do rozróżnienia w celu przewidywania rezygnacji. Jednak inżynieria cech może dodać wymiar czasowy do tych danych, tak aby algorytmy ML mogły rozróżnić, czy miesięczne saldo końcowe odbiegało od tego, czego zwykle oczekuje się od klienta. Wskaźniki takie jak uśpione konta, rosnące wypłaty, trendy użytkowania, odpływ salda netto w ciągu ostatnich kilku dni mogą być wczesnymi sygnałami ostrzegawczymi przed rezygnacją. Te wewnętrzne dane w połączeniu z danymi zewnętrznymi, takimi jak oferty konkurencji, mogą pomóc w przewidywaniu rezygnacji klientów. Po zidentyfikowaniu cech, następnym krokiem jest zrozumienie, dlaczego rezygnacje występują w kontekście biznesowym i usunięcie cech, które nie są silnymi predyktorami w celu zmniejszenia wymiarowości.
Check out this end-to-end machine learning project with source code in Python on Customer Churn Prediction Analysis using Ensemble Learning to combat churn.
How do I start a machine learning project?
Nie ma projektu, który by się powiódł bez solidnego planowania, a uczenie maszynowe nie jest wyjątkiem. Zbudowanie pierwszego projektu uczenia maszynowego nie jest tak trudne, jak się wydaje, pod warunkiem, że ma się solidną strategię planowania. Aby rozpocząć jakikolwiek projekt ML, należy postępować zgodnie z kompleksowym podejściem end-to-end – począwszy od określenia zakresu projektu do wdrożenia modelu i zarządzania w produkcji Oto nasze podejście do podstawowych kroków planu projektu uczenia maszynowego, aby zapewnić, że w pełni wykorzystasz każdy unikalny projekt –
1) Pierwszy krok: Machine Learning Project Scoping
Przed wszystkim zrozum, jakie są wymagania biznesowe projektu ML. Przy rozpoczynaniu projektu ML podstawowym krokiem jest wybranie odpowiedniego przypadku biznesowego, dla którego model uczenia maszynowego zostanie zbudowany. Wybór odpowiedniego przypadku użycia uczenia maszynowego i oszacowanie jego ROI jest ważne dla sukcesu każdego projektu uczenia maszynowego.
2) Drugi krok: Dane
Dane są siłą napędową każdego modelu uczenia maszynowego i nie da się wytrenować modelu uczenia maszynowego bez danych. Etap danych w cyklu życia projektu uczenia maszynowego składa się z czterech kroków –
-
Wymagania dotyczące danych – Ważne jest zrozumienie, jakiego rodzaju dane będą potrzebne, format danych, źródła danych i wymagania dotyczące zgodności źródeł danych.
-
Gromadzenie danych – Z pomocą administratorów baz danych, architektów danych lub deweloperów należy skonfigurować strategię gromadzenia danych, aby wydobyć dane z miejsc, w których żyją w organizacji lub od innych dostawców zewnętrznych.
-
Eksploracyjna analiza danych – Ten krok zasadniczo obejmuje walidację wymagań dotyczących danych, aby upewnić się, że masz właściwe dane, dane są w dobrym stanie i wolne od błędów.
-
Przygotowanie danych – Ten krok obejmuje przygotowanie danych do użycia przez algorytmy uczenia maszynowego. Korekta błędów, inżynieria cech, kodowanie do formatów danych zrozumiałych dla maszyn oraz korekta anomalii to zadania związane z przygotowaniem danych.
3) Trzeci krok – Budowanie modelu
W zależności od charakteru projektu, ten krok może zająć kilka dni lub miesięcy. Na etapie modelowania, podejmujesz decyzję o tym, który algorytm uczenia maszynowego zastosować i rozpoczynasz trening modelu na danych. Zrozumienie miary dokładności, błędu i poprawności, której powinien przestrzegać model uczenia maszynowego, jest ważne przy wyborze modelu. Po wytrenowaniu modelu, oceniamy go na danych walidacyjnych, aby przeanalizować jego wydajność i zapobiec przepasowaniu. Ocena modelu jest krytycznym krokiem, ponieważ jeśli model działa idealnie z danymi historycznymi i zwraca słabą wydajność z przyszłymi danymi, jest bezużyteczny.
4) Czwarty krok – Wdrożenie modelu do produkcji
Ten krok obejmuje wdrożenie oprogramowania lub aplikacji do użytkowników końcowych, więc nowe dane mogą wpływać do modelu uczenia maszynowego do dalszego uczenia się. Wdrożenie modelu uczenia maszynowego nie jest wystarczające, musisz również upewnić się, że model uczenia maszynowego działa zgodnie z oczekiwaniami. Należy ponownie wytrenować model na nowych danych produkcyjnych, aby zapewnić jego dokładność lub wydajność – to jest właśnie strojenie modelu. Dostrajanie modelu wymaga również sprawdzenia poprawności modelu, aby upewnić się, że nie dryfuje on lub nie staje się stronniczy.
Jak umieścić projekty uczenia maszynowego w swoim CV?
Doświadczenie w prawdziwym świecie przygotowuje Cię do ostatecznego sukcesu jak nic innego. Jako początkujący uczenia maszynowego, im więcej możesz zdobyć doświadczenia w czasie rzeczywistym, pracując nad projektami uczenia maszynowego, tym lepiej będziesz przygotowany do chwytania najgorętszych miejsc pracy dekady. Zdobycie pracy związanej z uczeniem maszynowym po ukończeniu szkolenia z zakresu nauki o danych lub odniesienie sukcesu jako naukowiec zajmujący się danymi będzie zależało od Twojej umiejętności sprzedania siebie. Po odbyciu kompleksowego szkolenia z zakresu nauki o danych, następnym krokiem do zdobycia pracy jako inżynier uczenia maszynowego lub naukowiec danych jest zbudowanie doskonałego portfolio, które zaprezentuje potencjalnym pracodawcom Twoje umiejętności stosowania technik uczenia maszynowego. Praca nad ciekawymi projektami ML to świetny sposób na rozpoczęcie kariery inżyniera uczenia maszynowego lub naukowca danych. Pracodawcy chcą zobaczyć, nad jakimi projektami związanymi z nauką o danych i uczeniem maszynowym pracowałeś, aby ocenić zakres Twoich umiejętności w zakresie nauki o danych i uczenia maszynowego. Podkreślenie kilku zabawnych, fajnych i interesujących przykładów projektów z zakresu nauki o danych i uczenia maszynowego w Twoim CV będzie miało większą wagę niż mówienie im, jak dużo wiesz. Oto, jak możesz dodać niesamowite projekty do swojego CV uczenia maszynowego –
- Możesz wspomnieć o projektach uczenia maszynowego zaraz po sekcji doświadczenia zawodowego w CV uczenia maszynowego.
- Podążaj za kolejnością numeracji wraz z tytułem projektów, nad którymi pracowałeś.
- Po tytule projektu powinna następować krótka informacja na temat zbioru danych i stwierdzenia problemu.
- Wspomnij o narzędziach uczenia maszynowego i technologiach, których użyłeś do ukończenia projektu.
- Ostatni, ale nie najmniej ważny, w swoim portfolio / CV połącz każdy projekt uczenia maszynowego z GitHubem, osobistą stroną internetową lub blogiem, aby uzyskać dogłębne zrozumienie swoich osiągnięć.
Czy chcesz zbudować silne portfolio uczenia maszynowego, czy chcesz ćwiczyć umiejętności analityczne, których nauczyłeś się w swoim kursie szkoleniowym w zakresie nauki o danych, mamy cię pod opieką. Wielu początkujących w dziedzinie uczenia maszynowego nie jest pewnych, od czego zacząć, jakie projekty uczenia maszynowego wykonać, jakich narzędzi, technik i frameworków uczenia maszynowego użyć. Zrobiliśmy to bezproblemowe zadanie dla nauki o danych i uczenia maszynowego początkujących poprzez kuratorowanie listę ciekawych pomysłów na projekty uczenia maszynowego wraz z ich rozwiązaniami. Te pomysły na projekty uczenia maszynowego pochodzą z popularnych wyzwań nauki o danych Kaggle i są świetnym sposobem na naukę uczenia maszynowego. Ta lista projektów jest doskonałym sposobem, aby umieścić projekty uczenia maszynowego w swoim CV. Odpowiedni sposób myślenia, chęć do nauki i dużo eksploracji danych są wymagane, aby zrozumieć rozwiązanie projektów z zakresu nauki o danych i uczenia maszynowego. Możesz odkryć 50+ projektów z zakresu nauki o danych i ML opartych na zestawie umiejętności, narzędzi i technik, których musisz się nauczyć.
Zanim zaczniesz pracę nad swoim projektem, warto mieć dostęp do biblioteki przykładów kodu projektu uczenia maszynowego. Więc w każdej chwili, gdy utkniesz w projekcie, możesz użyć tych rozwiązanych przykładów, aby się uwolnić.
Access Data Science and Machine Learning Project Code Examples
What Next?
One może stać się mistrzem uczenia maszynowego tylko z dużą ilością praktyki i eksperymentów. Posiadanie wiedzy teoretycznej na pewno pomaga, ale to właśnie jej zastosowanie pomaga w postępach najbardziej. Żadna ilość wiedzy teoretycznej nie zastąpi praktyki. Jednakże, będzie to pomocne, jeśli zapoznasz się z wyżej wymienionych innowacyjnych projektów uczenia maszynowego pierwszy.
Jeśli jesteś początkujący i nowy do uczenia maszynowego następnie pracy na projekty uczenia maszynowego zaprojektowane przez ekspertów branżowych w ProjectPro będzie niektóre z najlepszych inwestycji swojego czasu. Projekty te zostały stworzone z myślą o początkujących, aby pomóc im szybko zwiększyć swoje umiejętności w zakresie uczenia maszynowego, jednocześnie dając im szansę na poznanie ciekawych przypadków biznesowych w różnych domenach – handel detaliczny, finanse, ubezpieczenia, produkcja i wiele innych. Tak więc, jeśli chcesz czerpać przyjemność z nauki uczenia maszynowego, pozostać zmotywowanym i robić szybkie postępy, to ciekawe projekty ML ProjectPro są dla Ciebie. Dodaj te projekty uczenia maszynowego do swojego portfolio i wyląduj na najlepszej posadzie z wyższą pensją i satysfakcjonującymi dodatkami.

Kliknij tutaj, aby wyświetlić listę ponad 50 rozwiązanych, kompleksowych rozwiązań projektowych w zakresie uczenia maszynowego i Big Data
|
PREVIOUS |
NEXT |
.