
- Poznaj struktury danych, których używasz na co dzień.
- 🔎 Deep Dive Into the Basic Structure of Arrays
- 📚 Klasyfikacja
- 👀 Odczytywanie wartości – Magia się zaczyna!
- 1️⃣ Indeksy
- 2️⃣ Pamięć
- 🔧 Operacje – Za kulisami!
- 1️⃣ Wstawianie – Witamy!
- ⚠️ Chwileczkę! What Happens if the Array is Full?
- 2️⃣ Deletion- Bye, Bye!
- 3️⃣ Znajdowanie elementu
- 👋 Podsumowując…
- 👋 Dziękuję!
Poznaj struktury danych, których używasz na co dzień.
👋 Witamy! Zacznijmy od ważnego kontekstu. Pozwól, że zapytam Cię o to:
✅ Czy słuchasz muzyki na swoim smartfonie?
✅ Czy trzymasz listę kontaktów w swoim telefonie?
✅ Czy kiedykolwiek widziałeś tablicę liderów podczas zawodów?
Jeśli Twoja odpowiedź brzmi „tak” na którekolwiek z tych pytań, to jest prawie pewne, że używałeś tablic i nawet o tym nie wiedziałeś! 😃 Tablice to bardzo potężne struktury danych, które przechowują listy elementów. Mają one nieskończenie wiele zastosowań. Są bardzo ważne w świecie informatyki.
W tym artykule poznasz wady i zalety tablic, ich strukturę, operacje i przypadki użycia.
Zacznijmy! 👍
🔎 Deep Dive Into the Basic Structure of Arrays
Aby zrozumieć, jak one działają, bardzo pomocne jest zwizualizowanie pamięci komputera jako siatki, tak jak na poniższym rysunku. Każda informacja jest przechowywana w jednym z tych małych elementów (kwadratów), które tworzą siatkę.

Tablice wykorzystują tę strukturę „siatki” do przechowywania list powiązanych informacji w sąsiednich miejscach pamięci, aby zagwarantować najwyższą wydajność wyszukiwania tych wartości. 🔳🔳🔳🔳 🔳
Można myśleć o tablicach w ten sposób:
Ich elementy znajdują się obok siebie w pamięci. Jeśli musisz uzyskać dostęp do więcej niż jednego z nich, proces ten jest niezwykle zoptymalizowany, ponieważ komputer już wie, gdzie znajduje się dana wartość.
Absolutnie, prawda? Dowiedzmy się, jak to działa za kulisami! 😃
📚 Klasyfikacja
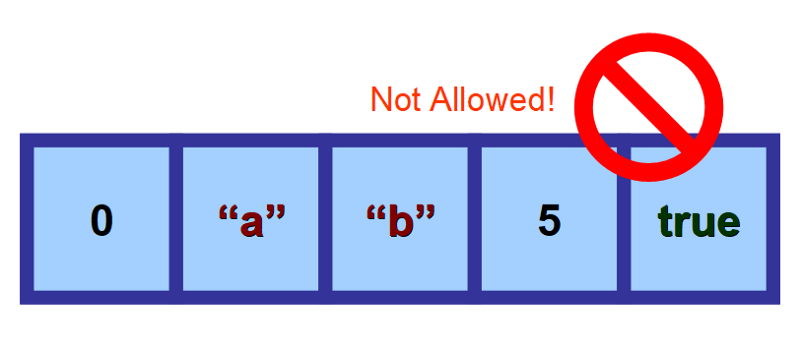
Tablice są klasyfikowane jako jednorodne struktury danych, ponieważ przechowują elementy tego samego typu.
Mogą przechowywać liczby, łańcuchy, wartości logiczne (true i false), znaki, obiekty i tak dalej. Ale kiedy już zdefiniujesz typ wartości, które będzie przechowywać twoja tablica, wszystkie jej elementy muszą być tego samego typu. Nie można „mieszać” różnych typów danych.
👀 Odczytywanie wartości – Magia się zaczyna!
Niesamowita moc tablic pochodzi z ich wydajności w dostępie do wartości. Osiąga się to dzięki strukturze przypominającej siatkę. Przyjrzyjmy się temu bardziej szczegółowo.🔍
Gdy tworzysz tablicę, to:
– Przypisujesz ją do zmiennej. 👈
– Określasz typ elementów, które będzie przechowywać. 🎈
– Określasz jej rozmiar (maksymalną liczbę elementów). 📚
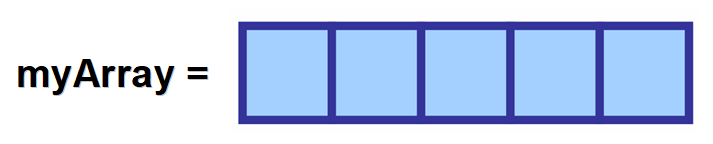
💡 Uwaga: Nazwa, którą nadasz tej zmiennej jest bardzo ważna, ponieważ będziesz jej używał w dalszej części kodu, aby uzyskać dostęp do wartości i modyfikować tablicę.
Ale jak powiedzieć komputerowi, do której konkretnie wartości chcesz uzyskać dostęp? To jest, gdzie indeksy podjąć istotną rolę!
1️⃣ Indeksy
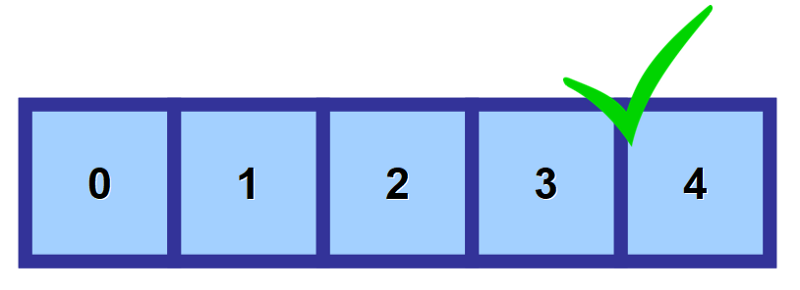
Używasz to, co nazywa się „indeks” („indeksy” w liczbie mnogiej), aby uzyskać dostęp do wartości w tablicy. Jest to liczba, która odnosi się do miejsca, w którym wartość jest przechowywana.
Jak widać na poniższym diagramie, pierwszy element w tablicy jest określany za pomocą indeksu 0. W miarę przesuwania się dalej w prawo, indeks zwiększa się o jeden dla każdego miejsca w pamięci.
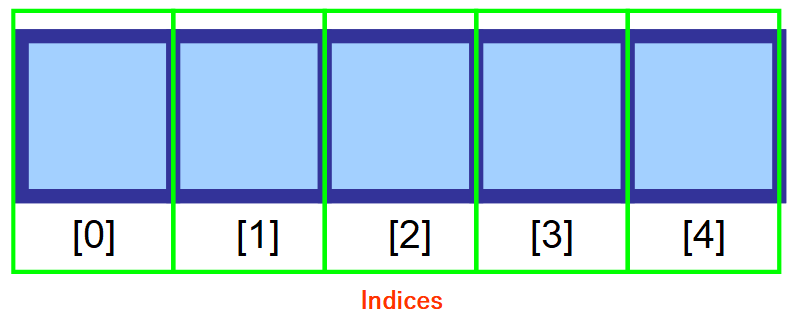
💡 Uwaga: Wiem, że na początku wydaje się to dziwne, aby zacząć liczyć od 0 zamiast 1, ale nazywa się to Zero-Based Numbering. Jest to bardzo powszechne w informatyce.
Ogólna składnia dostępu do elementu to: <ArrayVariable>
Na przykład:
Jeśli twoja tablica jest przechowywana w zmiennej myArray i chcesz uzyskać dostęp do pierwszego elementu (na indeksie 0), użyłbyś myArray
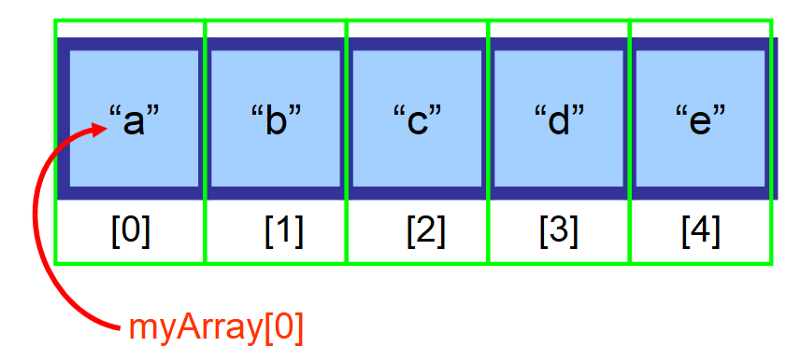
2️⃣ Pamięć
Teraz, gdy wiesz, jak uzyskać dostęp do wartości, zobaczmy, jak tablice są przechowywane w pamięci komputera. Kiedy definiujesz rozmiar tablicy, cała ta przestrzeń w pamięci jest „zarezerwowana” od tego momentu dla przyszłych wartości, które możesz chcieć wstawić.
💡 Uwaga: Jeśli nie wypełnisz tablicy wartościami, ta przestrzeń będzie zarezerwowana i pusta, dopóki tego nie zrobisz.
Dla przykładu:
Powiedzmy, że definiujesz tablicę o rozmiarze 5, ale wstawiasz tylko jedną wartość. Cała ta pozostała przestrzeń będzie pusta i „zarezerwowana” w pamięci, czekając na przyszłe przypisania.
Jest to kluczowe, ponieważ tablice są niezwykle wydajne w dostępie do wartości, ponieważ wszystkie elementy są przechowywane w sąsiadujących przestrzeniach w pamięci. W ten sposób komputer wie dokładnie, gdzie szukać informacji, o które prosiłeś.
Ale… jest minus tego 😞 ponieważ nie jest to wydajne pod względem pamięci. Rezerwujesz pamięć dla przyszłych operacji, które mogą nie wystąpić. Dlatego tablice są zalecane w sytuacjach, gdy z góry wiadomo ile elementów zamierzamy przechowywać.
🔧 Operacje – Za kulisami!
Gdy już wiesz czym są tablice, kiedy są używane i jak przechowują elementy, zagłębimy się w ich operacje, takie jak wstawianie i usuwanie.
1️⃣ Wstawianie – Witamy!
Powiedzmy, że mamy tablicę o rozmiarze 6 i wciąż jest w niej puste miejsce. Chcemy wstawić element „e” na początku tablicy (indeks 0), ale to miejsce jest już zajęte przez element „a”. Co powinniśmy zrobić?
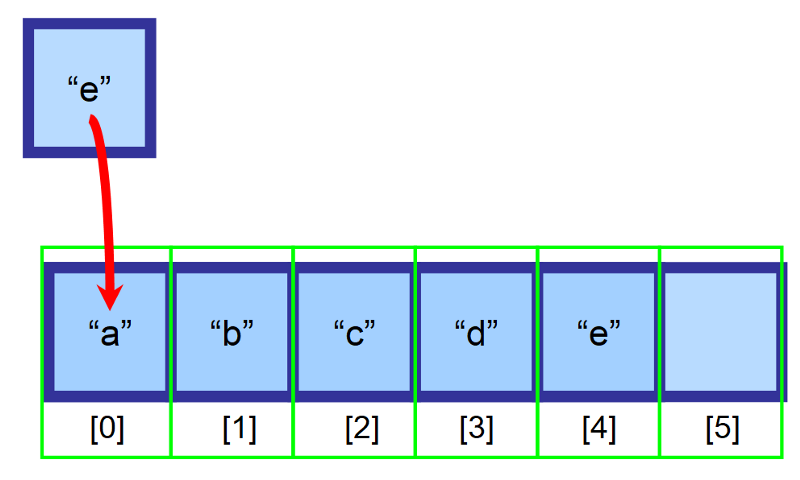
Aby wstawić do tablic, przesuwamy wszystkie elementy znajdujące się na prawo od miejsca wstawienia, o jeden indeks w prawo. Element „a” będzie teraz na indeksie 1, element „b” będzie na indeksie 2 i tak dalej…
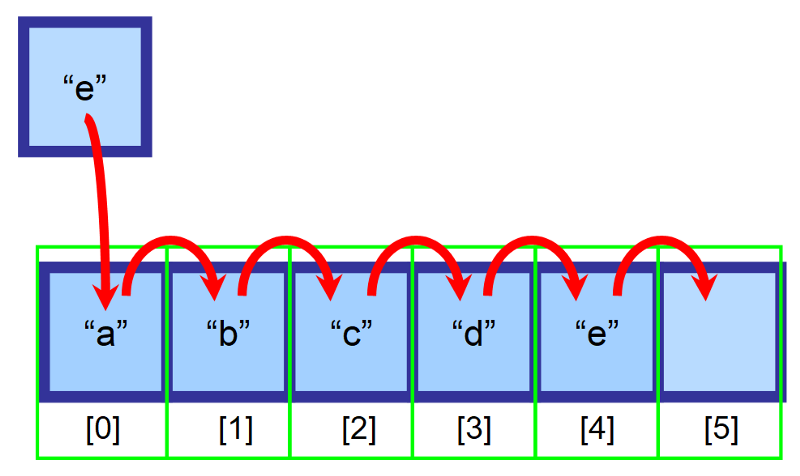
💡 Uwaga: Będziesz musiał utworzyć zmienną, aby śledzić ostatni indeks, który zawiera elementy. W powyższym diagramie tablica jest wypełniona do indeksu 4 przed wstawieniem. W ten sposób można określić, czy tablica jest pełna i jakiego indeksu należy użyć, aby wstawić element na końcu.
Po wykonaniu tych czynności, nasz element został pomyślnie wstawiony. 👏
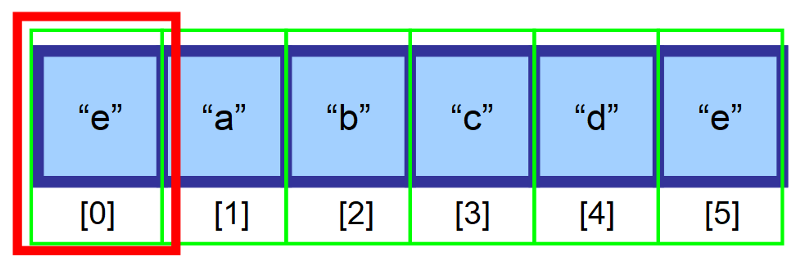
⚠️ Chwileczkę! What Happens if the Array is Full?
Jak myślisz, co się stanie, jeśli tablica jest pełna i spróbujesz wstawić element? 😱
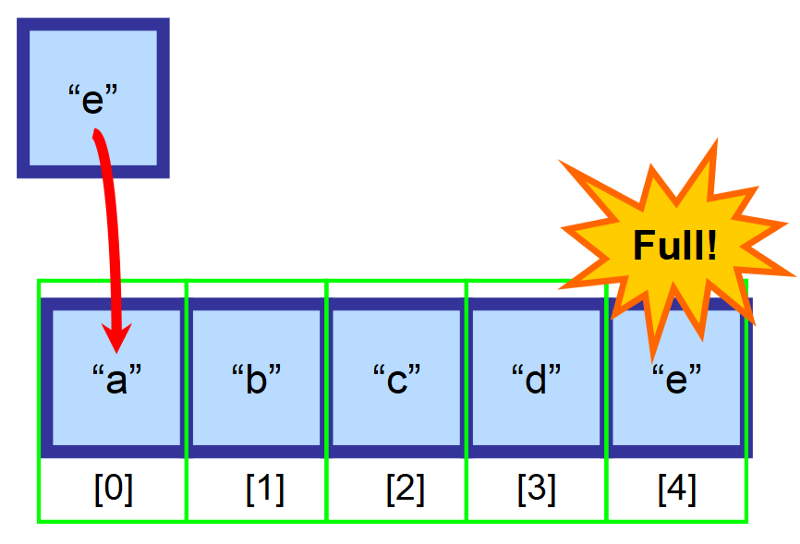
W tym przypadku trzeba utworzyć nową, większą tablicę i ręcznie skopiować wszystkie elementy do tej nowej tablicy. Ta operacja jest bardzo kosztowna, z punktu widzenia czasu. Wyobraź sobie, co by się stało, gdybyś miał tablicę z milionami elementów! To mogłoby zająć bardzo dużo czasu. ⏳
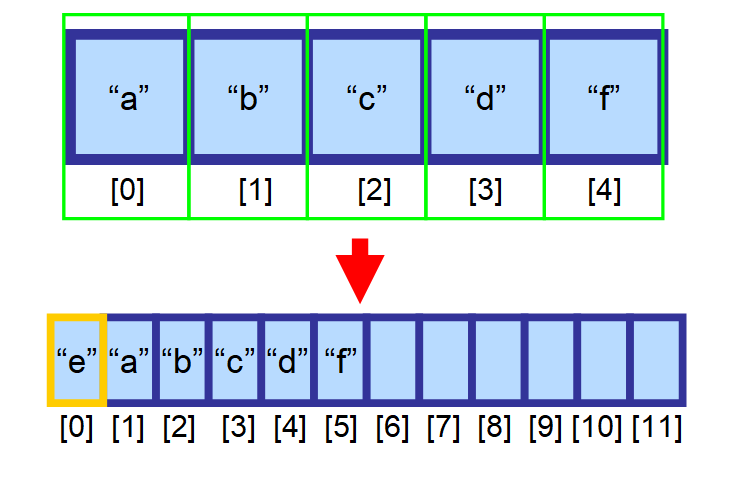
💡 Uwaga: Jedynym wyjątkiem od tej reguły, gdy wstawianie jest bardzo szybkie, jest sytuacja, gdy wstawiamy element na końcu tablicy (przy indeksie znajdującym się na prawo od ostatniego elementu) i jest jeszcze wolne miejsce. Odbywa się to w stałym czasie O(1).
2️⃣ Deletion- Bye, Bye!
Teraz powiedzmy, że chcesz usunąć element z tablicy.
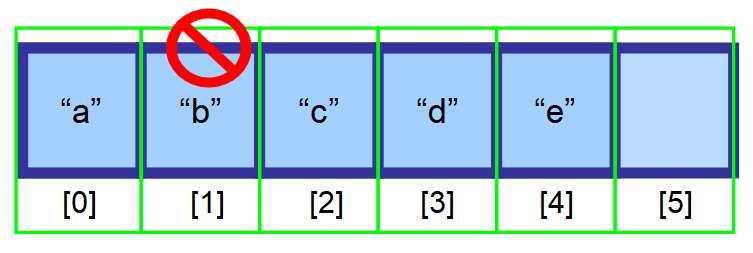
Aby zachować efektywność dostępu losowego (możliwość niezwykle szybkiego dostępu do tablicy poprzez indeks) elementy muszą być przechowywane w przyległych przestrzeniach pamięci. Nie możesz po prostu usunąć elementu i zostawić pustej przestrzeni.
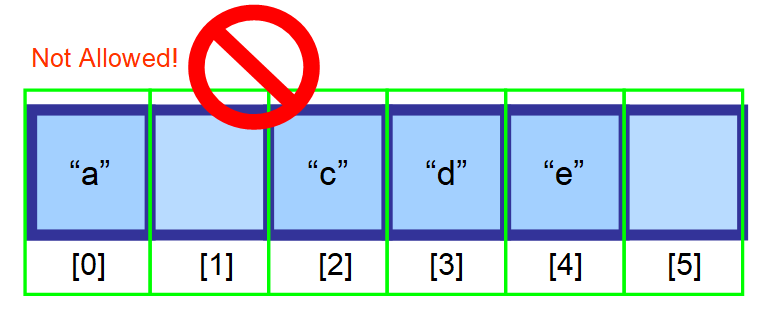
Powinieneś przesunąć elementy, które następują po elemencie, który chcesz usunąć, o jeden indeks w lewo.
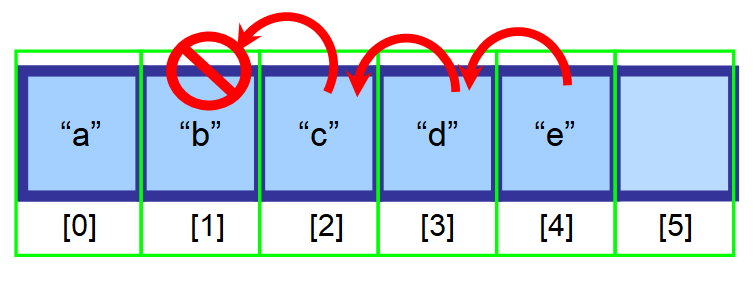
I w końcu masz tę wynikową tablicę 👇. Jak widać, „b” został pomyślnie usunięty.
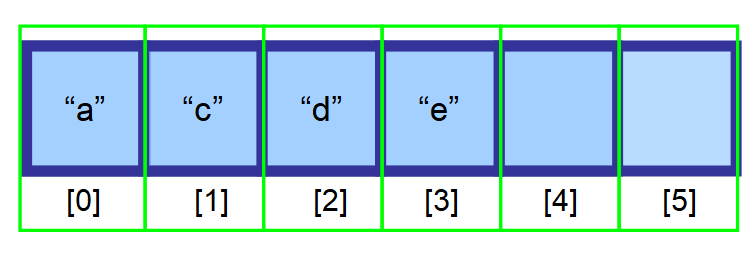
💡 Uwaga: Usuwanie jest bardzo wydajne, gdy usuwasz ostatni element. Ponieważ musisz utworzyć zmienną, aby śledzić ostatni indeks, który zawiera elementy (w powyższym diagramie, indeks 3), możesz bezpośrednio usunąć ten element używając indeksu.
3️⃣ Znajdowanie elementu
Masz trzy opcje, aby znaleźć element w tablicy:
- Jeśli wiesz, gdzie się znajduje, użyj indeksu.
- Jeśli nie wiesz, gdzie się znajduje, a twoje dane są posortowane, możesz użyć algorytmów do optymalizacji wyszukiwania, takich jak Binary Search.
- Jeśli nie wiesz, gdzie się znajduje, a twoje dane nie są posortowane, będziesz musiał przeszukać każdy element w tablicy i sprawdzić, czy bieżący element jest elementem, którego szukasz (proszę zobaczyć sekwencję diagramów poniżej).
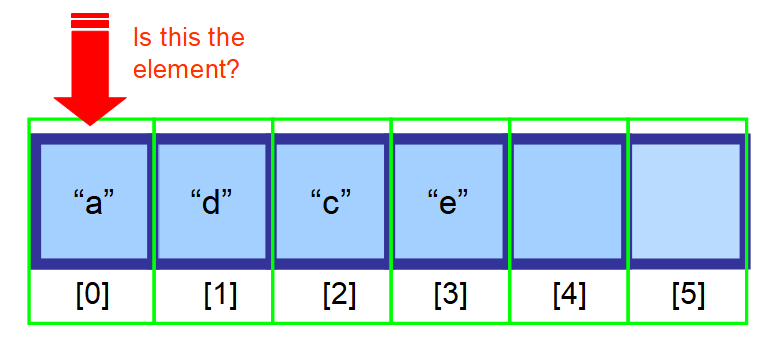

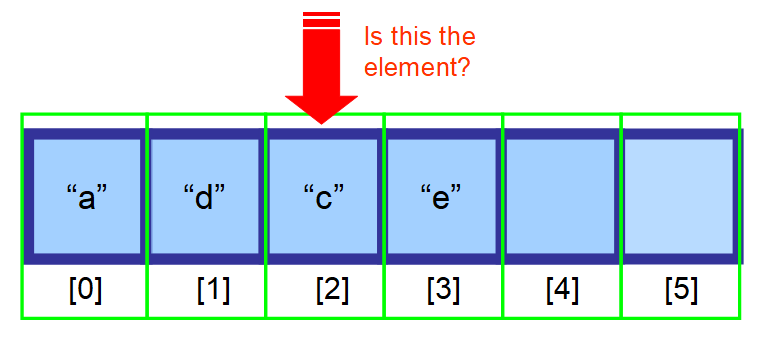
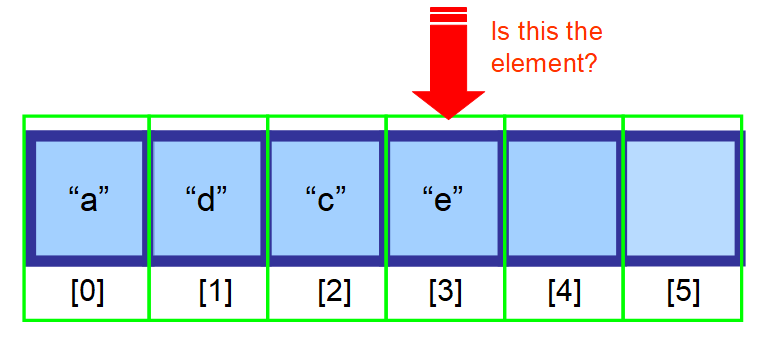
👋 Podsumowując…
- Tablice są niezwykle potężnymi strukturami danych, które przechowują elementy tego samego typu. Typ elementów i rozmiar tablicy są stałe i zdefiniowane podczas jej tworzenia.
- Pamięć jest alokowana natychmiast po utworzeniu tablicy i jest pusta, dopóki nie przypiszesz jej wartości.
- Ich elementy znajdują się w przyległych miejscach w pamięci, więc można uzyskać do nich bardzo wydajny dostęp (dostęp losowy, O(1) = stały czas) za pomocą indeksów.
- Indeksy zaczynają się od 0, a nie od 1, jak jesteśmy przyzwyczajeni.
- Wstawianie elementów na początku lub w środku tablicy wiąże się z przesuwaniem elementów w prawo. Jeśli tablica jest pełna, to tworzy nową, większą tablicę (co nie jest zbyt wydajne). Wstawianie na końcu tablicy jest bardzo wydajne, stały czas O(1).
- Usuwanie elementów z początku lub ze środka tablicy polega na przesunięciu wszystkich elementów w lewo, aby uniknąć pozostawienia pustego miejsca w pamięci. Gwarantuje to, że elementy są przechowywane w przyległych przestrzeniach w pamięci. Usuwanie na końcu tablicy jest bardzo wydajne, ponieważ usuwasz tylko ostatni element.
- Aby znaleźć element, musisz sprawdzić całą tablicę, aż go znajdziesz. Jeśli dane są posortowane, możesz użyć algorytmów takich jak Binary Search, aby zoptymalizować ten proces.
„Ucz się od wczoraj, żyj na dziś, miej nadzieję na jutro. Najważniejsze to nie przestawać kwestionować.”
– Albert Einstein
👋 Dziękuję!
Naprawdę mam nadzieję, że spodobał Ci się mój artykuł. ❤️
Follow me on Twitter to find more articles like this one. 😃