
By: Aaron Bertrand | Updated: 2019-12-03 | Komentarze (1) | Powiązane: More > Performance Tuning
Problem
Kilka lat temu pisałem na blogu o tym, jak można zmniejszyć wpływ na transactionlog bybreaking delete operations up into chunks. Zamiast usuwać 100,000 wierszy w jednej dużej transakcji, możesz usunąć 100 lub 1000 lub dowolną liczbę wierszy na raz, w kilku mniejszych transakcjach, w pętli. Oprócz zmniejszenia wpływu na dziennik, można było zapewnić ulgę dla długo trwających blokad. W tamtym czasie dyski SSD dopiero zdobywały popularność, a nowsze technologie, takie jakClustered Columnstore Indexes, Delayed Durability iAccelerated Database Recovery, jeszcze nie istniały. Pomyślałem więc, że może nadszedł czas na odświeżenie, aby dać lepszy obraz tego, jak to wygląda w SQL Server2019.
Rozwiązanie
Usuwanie dużych fragmentów tabeli nie zawsze jest jedyną odpowiedzią. Jeśli usuwasz 95% tabeli i zachowujesz 5%, może być szybciej przenieść wiersze, które chcesz zachować, do nowej tabeli, usunąć starą tabelę i zmienić nazwę nowej lub skopiować zachowane wiersze, przyciąć tabelę, a następnie skopiować je z powrotem. Ale nawet jeśli oczyszczanie jest znacznie większe niż przechowywanie, nie zawsze jest to możliwe ze względu na inne ograniczenia tabeli, umowy SLA i inne czynniki.
Jeszcze raz, jeśli okaże się, że musisz usunąć wiersze, będziesz chciał zminimalizować wpływ na dziennik transakcji i sposób, w jaki operacje wpływają na resztę obciążenia.Podejście chunkingowe nie jest nowym lub nowatorskim pomysłem, ale może dobrze współpracować z niektórymi z tych nowszych technologii, więc poddajmy je testowi w różnych kombinacjach.
Aby ustawić, mamy wiele stałych, które będą prawdziwe dla każdego testu:
- SQL Server 2019 RC1, z czterema rdzeniami i 32 GB RAM (maksymalna pamięć serwera =28 GB)
- 10 milionów wierszy tabeli
- Restart SQL Server po każdym teście (aby zresetować pamięć, bufory, i plancache)
- Przywrócenie kopii zapasowej, która miała już zaktualizowane statystyki i wyłączone auto-staty (aby zapobiec zakłócaniu operacji usuwania przez jakiekolwiek wyzwalane aktualizacje statystyk)
Mamy również wiele zmiennych, które będą się zmieniać podczas każdego testu:
W ten sposób powstaną 864 unikalne testy i lepiej uwierz, że zamierzam zautomatyzować wszystkie te permutacje.
I metryki, które będziemy mierzyć:
- Overall duration
- Average/peak CPU usage
- Average/peak memory usage
- Transaction log usage/file growth
- Database file usage, rozmiar magazynu wersji (podczas korzystania z Accelerated DatabaseRecovery)
- Rozmiar grupy wierszy delta (podczas korzystania z Columnstore)
Tabela źródłowa
Początkowo przywróciłem kopię AdventureWorks (AdventureWorks2017.bak, w szczególności). Aby utworzyć tabelę z 10 milionami wierszy, wykonałem kopię Sales.SalesOrderDetail, z własną kolumną tożsamości, i dodałem kolumnę wypełniającą, aby nadać każdemu wierszowi nieco więcej mięsa i zmniejszyć gęstość strony:
CREATE TABLE dbo.SalesOrderDetailCopy
(
SalesOrderDetailID int IDENTITY,
SalesOrderID int,
CarrierTrackingNumber nvarchar(25),
OrderQty smallint,
ProductID int,
SpecialOfferID int,
UnitPrice money,
UnitPriceDiscount money,
LineTotal numeric(38,6),
rowguid uniqueidentifier,
ModifiedDate datetime,
filler char(50) NOT NULL DEFAULT ''
);
GO
Następnie, aby wygenerować 10 000 000 wierszy, wstawiłem 100 000 wierszy na raz, i przełączyłem wstawianie 100 razy:
INSERT dbo.SalesOrderDetailCopy
(
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
)
SELECT TOP(100000)
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
FROM Sales.SalesOrderDetail;GO 100
Nie utworzyłem żadnych indeksów na tabeli; w zależności od podejścia do przechowywania danych, utworzę nowy indeks klastrowany (w połowie przypadków indeks kolumnowy) po przywróceniu bazy danych w ramach każdego testu.
Automatyzacja testów
Gdy tabela z 10 milionami wierszy już istniała, ustawiłem kilka opcji, wykonałem kopię zapasową bazy danych, dwukrotnie wykonałem kopię zapasową dziennika, a następnie ponownie wykonałem kopię zapasową bazy danych (aby dziennik miał jak najmniej miejsca po przywróceniu):
Następnie utworzyłem bazę danych Control, w której przechowywałbym procedury składowane uruchamiające testy, oraz tabele przechowujące wyniki testów (czas rozpoczęcia i zakończenia każdego testu) i metryki wydajności przechwycone podczas wszystkich testów.
Przechwycenie permutacji wszystkich 864 testów, które chciałem wykonać, zajęło kilka prób, ale skończyło się tak:
Jak można się było spodziewać, wstawiło to 864 wiersze ze wszystkimi tymi kombinacjami.
Następnie utworzyłem procedurę składowaną do przechwytywania zestawu metryk opisanych wcześniej.Monitoruję również instancję za pomocą SentryOne SQL Sentry, więc z pewnością będzie tam dostępnych kilka innych interesujących informacji, ale chciałem również uchwycić ważne szczegóły bez użycia jakichkolwiek narzędzi firm trzecich. Oto procedura, która robi wszystko, aby uzyskać wszystkie metryki dla dowolnego znacznika czasu w jednym wierszu:
Umieściłem tę procedurę przechowywaną w kroku zadania i uruchomiłem ją. Możesz chcieć użyć opóźnienia innego niż trzy sekundy – istnieje kompromis między kosztem kolekcji a kompletnością danych, który może przechylać się bardziej w jedną stronę niż w drugą dla Ciebie.
W końcu stworzyłem procedurę, która zawierałaby całą logikę, aby określić dokładnie, co zrobić z kombinacją parametrów dla każdego indywidualnego testu.Ponownie zajęło to kilka iteracji, ale produkt końcowy wygląda następująco:
Wiele się tam dzieje, ale podstawowa logika jest następująca:
- Wyciągnij dane specyficzne dla testu (identyfikator testu i wszystkie parametry) z dbo.Teststable
- Daj SQL Server kopa poprzez zmianę sp_configure i wyczyszczenie buforów i pamięci podręcznej planu
- Przywróć czystą kopię AdventureWorks, z wszystkimi 10 milionami nienaruszonych wierszy,i bez indeksów
- Zmień opcje bazy danych w zależności od parametrów dla bieżącego testu
- Utwórz klastrowany indeks columnstore lub klastrowany indeks B-tree
- Uaktualnij statystyki tabeli ręcznie, tylko dla pewności
- Zapisz, że rozpoczęliśmy test
- Określ ile iteracji pętli potrzebujemy i ile wierszy usunąć w każdej iteracji
- Wewnątrz pętli:
- Determinujemy, czy musimy rozpocząć transakcję na tej iteracji
- Wykonujemy delete
- Determinujemy, czy musimy popełnić transakcję na tej iteracji
- Determinujemy, czy musimy sprawdzić punkt kontrolny / wykonać kopię zapasową dziennika na tej iteracji
- Po pętli, logujemy, że ten test jest zakończony, i zatwierdzamy wszelkie niezaksięgowane transakcje
Aby faktycznie uruchomić test, nie chcę tego robić w Management Studio (nawet na tej samej maszynie wirtualnej), z powodu wszystkich danych wyjściowych, dodatkowego ruchu i wykorzystania zasobów.Stworzyłem procedurę składowaną i umieściłem ją w zadaniu:
To zajęło znacznie więcej czasu niż mogę przyznać. Częściowo było to spowodowane tym, że pierwotnie włączyłem test 0,1% dla rowperloopwhich, w niektórych przypadkach, zajęło to kilka godzin. Więc usunąłem je z tabeli po kilku dniach i mogę łatwo powiedzieć: jeśli usuwasz 1,000,000 wierszy, usuwanie 1,000 wierszy na raz jest bardzo mało prawdopodobne, aby było optymalnym wyborem, niezależnie od innych zmiennych:

(Chociaż wydaje się to być anomalią w porównaniu do większości innych testów, założę się, że nie byłoby to dużo szybsze niż usuwanie jednego wiersza lub 10 wierszy na raz. I w rzeczywistości było to wolniejsze niż usunięcie połowy tabeli lub większości tabeli w każdym innym scenariuszu.)
Wyniki wydajności
Po odrzuceniu wyników z testów 0.1%, umieściłem resztę w drugiej tabeli metrycznej z załadowanymi czasami trwania:
Musiałem użyć zewnętrznego złączenia do tabeli metrycznej, ponieważ niektóre testy przebiegały tak szybko, że nie było wystarczająco dużo czasu, aby uchwycić jakiekolwiek dane. Oznacza to, że w przypadku niektórych szybszych testów, nie będzie żadnej korelacji z innymi szczegółami wydajności, poza tym jak szybko działały.
Potem zacząłem szukać trendów i anomalii. Po pierwsze, sprawdziłem czas trwania i CPU w zależności od tego, czy włączona była opcja Delayed Durability (DD) i/lub Accelerated Database Recovery (ADR):
Wyniki (z zaznaczonymi anomaliami):

Wygląda na to, że ogólny czas trwania jest poprawiony, średnio o tę samą wartość, gdy włączona jest jedna z opcji (lub obie – a gdy obie są włączone, szczyt jest niższy). Wydaje się, że istnieje wartość odstająca dla samego ADR, która nie miała wpływu na średnią (ten konkretny test obejmował usuwanie 9 000 000 wierszy, 90 000 wierszy na raz, w PEŁNYM odzyskiwaniu, na tabeli rowstore). Wartość odstająca CPU dla DD również nie wpłynęła na średnią – ten konkretny przykład to usunięcie 1 000 000 wierszy, wszystkie naraz, na tabeli columnstore.
A co z ogólnymi różnicami porównującymi rowstore i columnstore?
Wyniki:

Columnstore jest wolniejszy średnio o 20%, ale wymaga mniej pamięci. Chciałem również zobaczyć wpływ na rozmiar pliku danych i pliku dziennika oraz ich wykorzystanie:
Results:

Wreszcie, na dzisiejszym sprzęcie, usuwanie w kawałkach nie wydaje się mieć tych samych korzyści, które miało kiedyś, przynajmniej pod względem czasu trwania. 18 najszybszych wyników tutaj, i 72 z najszybszych 100, to testy, w których wszystkie wiersze zostały usunięte za jednym razem, ujawnione przez to zapytanie:
Wyniki:
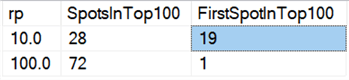
A jeśli spojrzymy na średnie dla wszystkich danych, jak w tym zapytaniu:
Widzimy, że usuwanie wszystkich wierszy naraz, niezależnie od tego, czy usuwamy10%, 50%, czy 90%, jest szybsze niż usuwanie z podziałem na części w jakikolwiek sposób (ponownie, średnio):
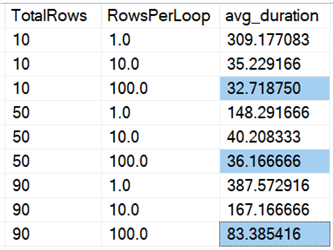
W formie wykresu:
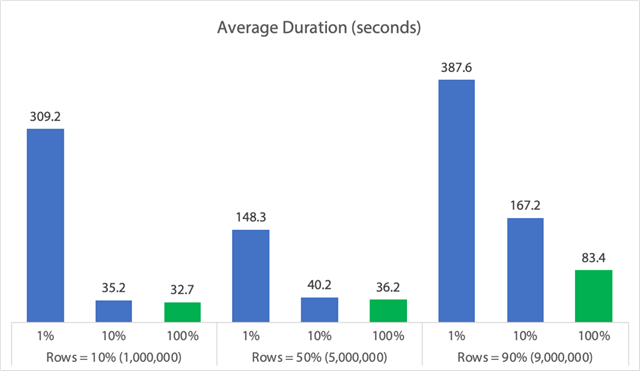
(Zauważ, że jeśli wyjmiemy zidentyfikowany wcześniej 6,062 sekundowy max_durationoutlier, ta pierwsza kolumna spada z 309 sekund do 162 sekund.)
Teraz, nawet w najlepszym przypadku, to wciąż 33, 36 lub 83 sekundy, w których adelete działa i potencjalnie blokuje wszystkich innych, a to ignoruje inne zmierzone wpływy, takie jak pamięć, plik dziennika, CPU i tak dalej. Czas trwania z pewnością nie powinien być jedynym kryterium; po prostu tak się składa, że jest to zwykle pierwsza (a czasem jedyna) rzecz, na którą ludzie patrzą. Ten zestaw testów miał na celu pokazanie, że możesz i powinieneś przechwytywać również kilka innych metryk, a wyniki pokazują, że wartości odstające mogą pochodzić z dowolnego miejsca.
Korzystając z tego zestawu jako modelu, możesz skonstruować własne testy skupiające się bardziej na ograniczeniach i możliwościach w twoim środowisku. Nie atakowałem metryk pod wszystkimi możliwymi kątami, ponieważ jest to wiele permutacji, ale zamierzam zachować tę bazę danych. Więc, jeśli są inne sposoby, które chcesz zobaczyć dane pokrojone w plasterki, daj mi znać w komentarzach poniżej, a ja zobaczę, co mogę zrobić. Tylko nie proś mnie o ponowne uruchomienie wszystkich testów.
Caveats
To wszystko nie uwzględnia jednoczesnego obciążenia, wpływu ograniczeń tabel takich jak klucze obce, obecności wyzwalaczy i wielu innych możliwych scenariuszy.Inną rzeczą do przetestowania (potencjalnie w przyszłym wydaniu) jest posiadanie wielu zadań, które współdziałają z tą samą tabelą podczas całej operacji, i mierzenie takich rzeczy jak czas trwania blokady, typy i czasy oczekiwania, oraz ocena, w jakich sytuacjach jeden zestaw aktywności ma bardziej dramatyczny wpływ na drugi zestaw.
Następne kroki
Czytaj dalej, aby uzyskać powiązane wskazówki i inne zasoby:
- OperacjeCRUD w SQL Server
- Różnice między Delete i Truncate w SQL Server
- Usuwanie danych historycznych z dużej, wysoce współbieżnej tabeli bazy danych SQL Server
- Podziel duże operacje usuwania na fragmenty
- Przykład indeksu Columnstore w SQL Server Clustered and Nonclustered
- Opóźniona trwałość w SQL Server 2014
- Opóźniona trwałość podczas oczyszczania danych
- Przyspieszone odzyskiwanie bazy danych w SQL Server 2019
.
Ostatnia aktualizacja: 2019-12-03


O autorze
 Aaron Bertrand (@AaronBertrand) jest pasjonatem technologii z doświadczeniem branżowym sięgającym klasycznego ASP i SQL Server 6.5. Jest redaktorem naczelnym bloga poświęconego wydajności, SQLPerformance.com, a także bloguje pod adresem sqlblog.org.
Aaron Bertrand (@AaronBertrand) jest pasjonatem technologii z doświadczeniem branżowym sięgającym klasycznego ASP i SQL Server 6.5. Jest redaktorem naczelnym bloga poświęconego wydajności, SQLPerformance.com, a także bloguje pod adresem sqlblog.org.Zobacz wszystkie moje wskazówki
- Więcej wskazówek SQL Server DBA Tips…
.