
Najlepsze biblioteki Pythona do uczenia maszynowego i głębokiego uczenia
Choć istnieje wiele języków do wyboru, Python jest jednym z najbardziej przyjaznych dla programistów języków programowania uczenia maszynowego i głębokiego uczenia, a ponadto jest wyposażony w szeroki zestaw bibliotek dostosowanych do każdego przypadku użycia i projektu.

● TensorFlow
Rewolucja nadeszła! Witamy w TensorFlow 2.0.
TensorFlow to szybka, elastyczna i skalowalna biblioteka uczenia maszynowego typu open-source do badań i produkcji.
TensorFlow jest jedną z najlepszych dostępnych bibliotek do pracy z uczeniem maszynowym w Pythonie. Oferowany przez Google, TensorFlow sprawia, że budowanie modeli ML jest łatwe zarówno dla początkujących, jak i profesjonalistów.
Używając TensorFlow, możesz tworzyć i trenować modele ML nie tylko na komputerach, ale także na urządzeniach mobilnych i serwerach, używając TensorFlow Lite i TensorFlow Serving, które oferują te same korzyści, ale dla platform mobilnych i wysokowydajnych serwerów.
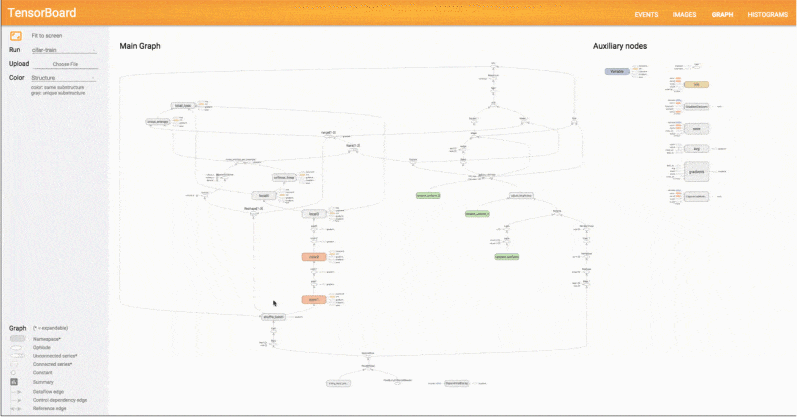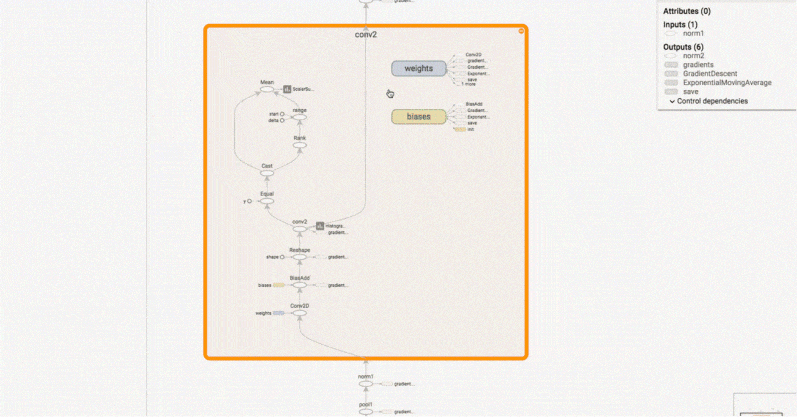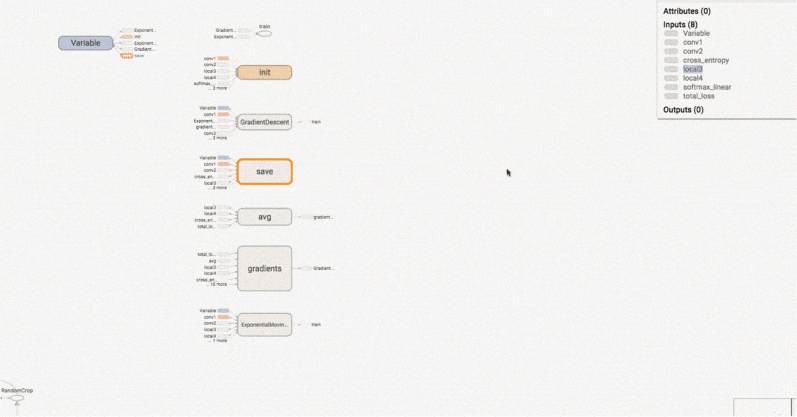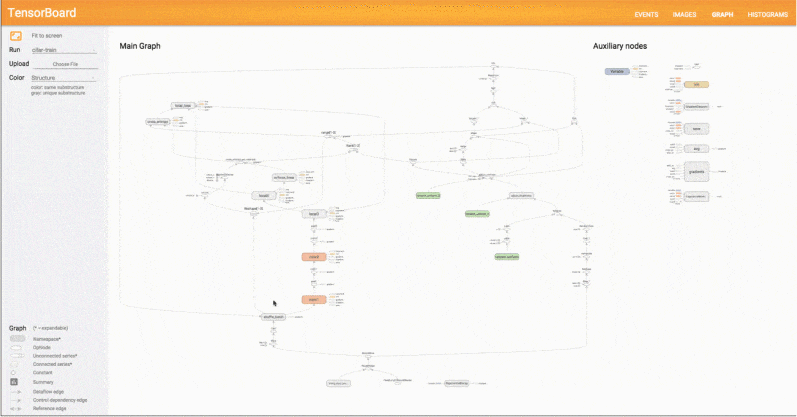
Kilka istotnych obszarów w ML i DL, w których TensorFlow błyszczy to:
● Obsługa głębokich sieci neuronowych
● Przetwarzanie języka naturalnego
● Równania różniczkowe cząstkowe
● Możliwości abstrakcji
● Rozpoznawanie obrazu, tekstu i mowy
● Bezproblemowa współpraca pomysłów i kodu
Zadanie główne: Zbuduj modele Deep Learning
Aby zrozumieć, jak wykonać konkretne zadanie w TensorFlow, możesz odwołać się do samouczków TensorFlow.
● Keras
Keras to jedna z najpopularniejszych i open-source’owych bibliotek sieci neuronowych dla Pythona. Początkowo zaprojektowany przez inżyniera Google dla ONEIROS, skrót od Open-Ended Neuro Electronic Intelligent Robot Operating System, Keras został wkrótce wsparty w bibliotece rdzeniowej TensorFlow, czyniąc go dostępnym na wierzchu TensorFlow. Keras posiada kilka bloków konstrukcyjnych i narzędzi niezbędnych do tworzenia sieci neuronowych, takich jak:
● Warstwy neuronowe
● Funkcje aktywacji i kosztu
● Cele
● Normalizacja partii
● Dropout
● Pooling
.

Keras rozszerza użyteczność TensorFlow o te dodatkowe funkcje do programowania ML i DL. Dzięki pomocnej społeczności i dedykowanemu kanałowi Slack, uzyskanie wsparcia jest łatwe. Wsparcie dla sieci neuronowej konwolucyjnej i rekurencyjnej istnieje również wraz ze standardowymi sieciami neuronowymi. Możesz również odnieść się do innych przykładowych modeli w klasie Keras i Computer Vision ze Stanford.
Keras Cheat Sheet : https://s3.amazonaws.com/assets.datacamp.com/blog_assets/Keras_Cheat_Sheet_Python.pdf
Zadania podstawowe: Build Deep Learning models
Getting Started with Keras –
● PyTorch
Opracowany przez Facebook, PyTorch jest jedną z niewielu bibliotek uczenia maszynowego dla Pythona. Oprócz Pythona, PyTorch ma również wsparcie dla C++ z interfejsem C++, jeśli jesteś w tym dobry. Uważany za jednego z głównych pretendentów w wyścigu o bycie najlepszym frameworkiem do uczenia maszynowego i głębokiego uczenia, PyTorch musi stawić czoła konkurencji ze strony TensorFlow. Możesz odnieść się do tutoriali PyTorch po inne szczegóły.
Kilka istotnych cech, które odróżniają PyTorch od TensorFlow to:
● Obliczenia tensorowe z możliwością przyspieszonego przetwarzania przez jednostki przetwarzania graficznego
● Łatwość nauki, użycia i integracji z resztą ekosystemu Pythona
● Wsparcie dla sieci neuronowych zbudowanych na taśmowym systemie auto diff
Różne moduły, z którymi dostarczany jest PyTorch, które pomagają tworzyć i trenować sieci neuronowe:
● Tensory – torch.Tensor

● Optymalizatory – torch.moduł optim
● Sieci neuronowe – moduł nn
● Autograd
Pros: bardzo konfigurowalny, szeroko stosowany w badaniach nad głębokim uczeniem
Cons: mniej abstrakcji NLP, nie zoptymalizowany pod kątem szybkości
Zadania podstawowe: Rozwijanie i szkolenie modeli głębokiego uczenia
Keras vs Tensorflow vs PyTorch | Deep Learning Frameworks Comparison
● Scikit-learn
Scikit-learn to kolejna aktywnie używana biblioteka uczenia maszynowego dla Pythona. Zawiera łatwą integrację z różnymi bibliotekami programowania ML, takimi jak NumPy i Pandas. Scikit-learn pochodzi z obsługą różnych algorytmów, takich jak:
● Klasyfikacja
● Regresja
● Klasteryzacja
● Redukcja wymiarowości
● Wybór modelu
● Preprocessing
Zbudowany wokół idei bycia łatwym w użyciu, ale wciąż elastycznym, Scikit-learn koncentruje się na modelowaniu danych, a nie na innych zadaniach, takich jak ładowanie, obsługa, manipulacja i wizualizacja danych. Jest uważany za wystarczający, aby być używany jako end-to-end ML, od fazy badawczej do wdrożenia. Aby uzyskać głębsze zrozumienie scikit-learn, możesz sprawdzić tutoriale Scikit-learn.
Zadania podstawowe: Modelowanie
Learn Scikit-Learn-
● Pandas
Pandas to biblioteka analizy danych Pythona i jest używana głównie do manipulacji i analizy danych. Wchodzi do gry zanim zbiór danych zostanie przygotowany do treningu. Pandas sprawia, że praca z szeregami czasowymi i wielowymiarowymi danymi strukturalnymi jest bezproblemowa dla programistów uczenia maszynowego. Niektóre z doskonałych cech Pandas, jeśli chodzi o obsługę danych, to:
● Przekształcanie i przestawianie zbiorów danych
● Łączenie i scalanie zbiorów danych
● Obsługa brakujących danych i wyrównywanie danych
● Różne opcje indeksowania, takie jak Hierarchiczne indeksowanie osi, Fancy indexing
● Opcje filtrowania danych

Pandas korzysta z DataFrames, co jest tylko technicznym terminem dla dwuwymiarowej reprezentacji danych, oferując programistom obiekty DataFrame.
Główne zadanie: Manipulacja i analiza danych
Google Trends – zainteresowanie pand w czasie

.
● NLTK
NLTK to skrót od Natural Language Toolkit i jest biblioteką Pythona służącą do pracy z przetwarzaniem języka naturalnego. Jest ona uważana za jedną z najpopularniejszych bibliotek do pracy z danymi języka ludzkiego. NLTK oferuje proste interfejsy wraz z szerokim wachlarzem zasobów leksykalnych, takich jak FrameNet, WordNet, Word2Vec i kilka innych dla programistów. Niektóre z najważniejszych cech NLTK to:
● Wyszukiwanie słów kluczowych w dokumentach
● Tokenizacja i klasyfikacja tekstów
● Rozpoznawanie głosu i pisma ręcznego
● Lematyzacja i stemming słów słów

NLTK i jego pakiety są uważane za niezawodny wybór dla studentów, inżynierów, badaczy, lingwistów i przemysłu, który pracuje z językiem.
Core Task: Przetwarzanie tekstu
● Spark MLlib
MLlib to skalowalna biblioteka uczenia maszynowego Apache Spark
Opracowana przez Apache, Spark MLlib to biblioteka uczenia maszynowego, która umożliwia łatwe skalowanie Twoich obliczeń. Jest prosta w użyciu, szybka, łatwa do skonfigurowania i oferuje płynną integrację z innymi narzędziami. Spark MLlib od razu stał się wygodnym narzędziem do tworzenia algorytmów i aplikacji uczenia maszynowego.
Narzędzia, które Spark MLlib wnosi do stołu, to:
Niektóre z popularnych algorytmów i interfejsów API, które mogą wykorzystać programiści pracujący nad uczeniem maszynowym przy użyciu Spark MLlib, to:
● Regresja
● Klasteryzacja
● Optymalizacja
● Redukcja wymiaru
● Klasyfikacja
● Podstawowe statystyki
● Ekstrakcja cech
● Theano
Theano to potężna biblioteka Pythona umożliwiająca łatwe definiowanie, optymalizację i ocenę potężnych wyrażeń matematycznych. Niektóre z cech, które sprawiają, że Theano jest solidną biblioteką do przeprowadzania obliczeń naukowych na dużą skalę to:
● Wsparcie dla procesorów graficznych, aby lepiej radzić sobie w ciężkich obliczeniach w porównaniu z procesorami centralnymi
● Silne wsparcie integracji z NumPy
● Szybsze i stabilne oceny nawet najbardziej skomplikowanych zmiennych
● Możliwość tworzenia niestandardowego kodu C dla Twoich operacji matematycznych
Z Theano, możesz osiągnąć szybki rozwój jednych z najbardziej wydajnych algorytmów uczenia maszynowego. Zbudowane na szczycie Theano są niektóre z dobrze znanych bibliotek głębokiego uczenia się, takich jak Keras, Blocks i Lasagne. Dla bardziej zaawansowanych koncepcji w Theano, możesz odnieść się do samouczka Theano.
● MXNet
A flexible and efficient library for deep learning

Jeśli Twoja dziedzina wiedzy obejmuje Deep Learning, to MXNet będzie dla Ciebie idealnym rozwiązaniem. Używana do szkolenia i wdrażania głębokich sieci neuronowych, MXNet jest wysoce skalowalna i obsługuje szybkie szkolenie modeli. MXNet Apache’a działa nie tylko z Pythonem, ale także z wieloma innymi językami, takimi jak C++, Perl, Julia, R, Scala, Go i kilka innych.
Przenośność i skalowalność MXNetu pozwala przenieść go z jednej platformy na inną i skalować do wymagających potrzeb projektu. Niektóre z największych nazwisk w technice i edukacji, takie jak Intel, Microsoft, MIT i inne, obecnie wspierają MXNet. Amazon’s AWS preferuje MXNet jako swój wybór preferowanych ram głębokiego uczenia się.
● Numpy

Biblioteka NumPy dla Pythona koncentruje się na obsłudze rozległych danych wielowymiarowych i skomplikowanych funkcji matematycznych działających na tych danych. NumPy oferuje szybkość obliczeń i wykonywania skomplikowanych funkcji działających na tablicach. Kilka z punktów przemawiających za NumPy to:
● Obsługa operacji matematycznych i logicznych
● Manipulacje kształtami
● Możliwości sortowania i wybierania
● Dyskretne transformacje Fouriera
● Podstawowa algebra liniowa i operacje statystyczne
● Symulacje losowe
● Obsługa n-.tablic wymiarowych
NumPy działa w oparciu o podejście obiektowe i posiada narzędzia do integracji kodu C, C++ i Fortran, a to czyni NumPy bardzo popularnym wśród społeczności naukowej.
Zadanie podstawowe: Czyszczenie i manipulacja danymi
Google Trends – zainteresowanie Numpy w czasie

.
Wnioski
Python jest naprawdę wspaniałym narzędziem rozwoju, które nie tylko służy jako język programowania ogólnegojęzyk programowania ogólnego przeznaczenia, ale także zaspokaja specyficzne nisze twojego projektu lub przepływu pracy. Z mnóstwem bibliotek i pakietów, które rozszerzają możliwości Pythona i sprawiają, że jest on wszechstronny i doskonale nadaje się dla każdego, kto chce się zająć tworzeniem programów i algorytmów. Dzięki niektórym z nowoczesnych bibliotek uczenia maszynowego i głębokiego uczenia dla Pythona omówionych pokrótce powyżej, możesz zorientować się, co każda z tych bibliotek ma do zaoferowania i dokonać wyboru.