
- Krijg Toegang Tot Top ML Projecten
- Machine learning-projecten voor beginners in 2021
- Verkoopvoorspelling met behulp van Walmart-dataset
- BigMart-verkoopvoorspelling ML-project
- Muziekaanbevelingssysteem Project
- Herkenning van menselijke activiteit met behulp van smartphone-dataset
- Voorspelling van aandelenkoersen met behulp van tijdreeksen
- Voorspelling van wijnkwaliteit met behulp van wijnkwaliteit-dataset
- MNIST Handgeschreven cijferclassificatie
- Leren bouwen van aanbevelingssystemen met Movielens-dataset
- Boston Housing Price Prediction ML Project
- Social Media Sentiment Analysis using Twitter Dataset
- Iris Flowers Classification ML Project
- Retail Price Optimization using Machine Learning
- Customer Churn Prediction Analysis
- 1. Sales Forecasting using Walmart Dataset
- 2. BigMart Sales Prediction ML Project – Leer over Unsupervised Machine Learning Algorithms
- Music Recommendation System Project
- Human Activity Recognition using Smartphone Dataset
- Voorspeller van aandelenkoersen met behulp van tijdreeksen
- Predicting Wine Quality using Wine Quality Dataset
- MNIST Handwritten Digit Classification
- Leer aanbevelingssystemen te bouwen met Movielens Dataset
- Boston Housing Price Prediction ML Project
- Social Media Sentiment Analysis using Twitter Dataset
- Iris Flowers Classification ML Project- Learn about Supervised Machine Learning Algorithms
- Machine Learning Projecten voor beginners met broncode in Python voor 2021
- 12) Retail Price Optimization ML Project – Dynamic Pricing Machine Learning Model voor een dynamische markt
- 13) Customer Churn Prediction Analysis Using Ensemble Techniques in Machine Learning
- Hoe begin ik een machine learning-project?
- 1) Eerste stap: Machine Learning Project Scoping
- 2) Tweede stap: Data
- 3) Derde stap – Model bouwen
- 4) Vierde stap – Model uitrollen in productie
- Hoe zet je machine learning-projecten op je cv?
- What Next?
Krijg Toegang Tot Top ML Projecten
×
Laatst bijgewerkt: 05 mrt 2021

Je wilt machinaal leren leren, maar je hebt moeite om ermee te beginnen. Boeken en cursussen zijn misschien niet genoeg als het gaat om machine learning. Hoewel ze altijd voorbeeldcodes en -fragmenten voor machine learning geven, krijg je niet de kans om machine learning toe te passen op echte problemen en te zien hoe deze codefragmenten in elkaar passen. De beste manier om te beginnen met het leren van machine learning is om beginner tot gevorderd niveau machine learning projecten uit te voeren. Het is altijd nuttig om inzicht te krijgen in hoe echte mensen hun carrière in machine learning beginnen door end-to-end ML-projecten te implementeren.
In deze blogpost ontdekt u hoe beginners zoals u grote vooruitgang kunnen boeken bij het toepassen van machine learning op echte problemen met deze fantastische machine learning-projecten voor beginners die worden aanbevolen door industrie-experts. ProjectPro industrie-experts hebben zorgvuldig de lijst samengesteld van top machine learning projecten voor beginners die de kernaspecten van machine learning zoals supervised learning, unsupervised learning, deep learning, en neurale netwerken dekken. In al deze machine learning projecten zal je beginnen met real-world datasets die publiek beschikbaar zijn. We verzekeren je dat je deze blog absoluut interessant en de moeite waard zult vinden om te lezen vanwege alles wat je hier kunt leren over de meest populaire machine learning projecten.
“Welke projecten kan ik doen met machine learning ?” We krijgen deze vraag vaak gesteld van beginners die aan de slag gaan met machine learning. ProjectPro industrie-experts raden u aan om een aantal spannende, coole, leuke en gemakkelijke machine learning projectideeën in diverse zakelijke domeinen te verkennen om hands-on ervaring op te doen met de machine learning vaardigheden die u hebt geleerd. We hebben een lijst samengesteld van innovatieve en interessante machine learning projecten met broncode voor professionals die hun carrière in machine learning beginnen. Deze beginnersprojecten over machine learning zijn een perfecte mix van verschillende soorten uitdagingen die men kan tegenkomen bij het werken als een machine learning engineer of data scientist.
Machine learning-projecten voor beginners in 2021
-
Verkoopvoorspelling met behulp van Walmart-dataset
-
BigMart-verkoopvoorspelling ML-project
-
Muziekaanbevelingssysteem Project
-
Herkenning van menselijke activiteit met behulp van smartphone-dataset
-
Voorspelling van aandelenkoersen met behulp van tijdreeksen
-
Voorspelling van wijnkwaliteit met behulp van wijnkwaliteit-dataset
-
MNIST Handgeschreven cijferclassificatie
-
Leren bouwen van aanbevelingssystemen met Movielens-dataset
-
Boston Housing Price Prediction ML Project
-
Social Media Sentiment Analysis using Twitter Dataset
-
Iris Flowers Classification ML Project
-
Retail Price Optimization using Machine Learning
-
Customer Churn Prediction Analysis
Let’s duik in!

1. Sales Forecasting using Walmart Dataset
Sales forecasting is een van de meest voorkomende use cases van machine learning voor het identificeren van factoren die de verkoop van een product beïnvloeden en het schatten van toekomstige verkoopvolumes. Dit machine-learningproject maakt gebruik van de Walmart-dataset die verkoopgegevens bevat voor 98 producten in 45 verkooppunten. De dataset bevat de verkoop per winkel, per afdeling op wekelijkse basis. Het doel van dit machine-learning project is om de verkoop te voorspellen voor elke afdeling in elk verkooppunt om hen te helpen betere data-gedreven beslissingen te nemen voor kanaal optimalisatie en voorraadplanning. Het uitdagende aspect van het werken met de Walmart-dataset is dat deze geselecteerde markdown-evenementen bevat die de verkoop beïnvloeden en waarmee rekening moet worden gehouden.
Dit is een van de meest eenvoudige en coole machine learning-projecten waarbij je een voorspellend model zult bouwen met behulp van de Walmart-dataset om het aantal verkopen in te schatten dat ze in de toekomst zullen maken en hier is hoe –
- Importeer de gegevens en verken deze om de structuur en waarden binnen de gegevens te begrijpen – Begin met het importeren van een CSV-bestand en het uitvoeren van elementaire verkennende gegevensanalyse (EDA).
- Voorbereiden van de gegevens voor modellering – Meerdere gegevenssets samenvoegen en groep door functie toepassen om gegevens te analyseren.
- Plot een tijdreeksgrafiek en analyseer deze.
- Pas de ontwikkelde verkoopvoorspellingsmodellen op de trainingsgegevens- Maak een ARIMA-model voor tijdreeksvoorspelling
- Vergelijk de ontwikkelde modellen op de testgegevens.
- Optimaliseer de verkoopvoorspellingsmodellen door belangrijke kenmerken te kiezen om de nauwkeurigheidsscore te verbeteren.
- Maak gebruik van het beste machine learning model om de verkoop van volgend jaar te voorspellen.
Na het werken aan dit Kaggle machine learning project zult u begrijpen hoe krachtige machine learning modellen het totale verkoopvoorspellingsproces eenvoudig kunnen maken. Hergebruik deze end-to-end sales forecasting machine learning modellen in productie om de verkoop te voorspellen voor elke afdeling of retail store.
Wilt u werken met Walmart Dataset? Bekijk de volledige oplossing voor dit geweldige machine learning-project hier – Walmart Store Sales Forecasting Machine Learning Project
2. BigMart Sales Prediction ML Project – Leer over Unsupervised Machine Learning Algorithms
BigMart verkoopdataset bestaat uit 2013 verkoopgegevens voor 1559 producten over 10 verschillende verkooppunten in verschillende steden. Het doel van het BigMart-verkoopvoorspellings ML-project is het bouwen van een regressiemodel om de verkoop van elk van 1559 producten voor het volgende jaar te voorspellen in elk van de 10 verschillende BigMart-verkooppunten. De BigMart verkoop dataset bestaat ook uit bepaalde attributen voor elk product en winkel. Dit model helpt BigMart de eigenschappen van producten en winkels te begrijpen die een belangrijke rol spelen bij het verhogen van hun totale verkoop.
Toegang tot de volledige oplossing voor dit ML-project hier – BigMart Sales Prediction Machine Learning Project Solution
Music Recommendation System Project
Dit is een van de meest populaire machine learning-projecten en kan worden gebruikt in verschillende domeinen. Je bent misschien wel bekend met een aanbevelingssysteem als je een website voor e-commerce of een website voor films of muziek hebt gebruikt. In de meeste E-commerce sites zoals Amazon, op het moment van afrekenen, zal het systeem producten aanbevelen die kunnen worden toegevoegd aan uw winkelwagen. Op dezelfde manier zal het systeem op Netflix of Spotify, op basis van de films die u leuk vond, gelijkaardige films of liedjes tonen die u misschien ook leuk vindt. Hoe doet het systeem dit? Dit is een klassiek voorbeeld waar Machine Learning kan worden toegepast.
In dit project gebruiken we de dataset van de toonaangevende muziekstreamingdienst van Azië om een beter muziekaanbevelingssysteem te bouwen. We zullen proberen te bepalen welk nieuw nummer of welke nieuwe artiest een luisteraar leuk zou kunnen vinden op basis van hun eerdere keuzes. De primaire taak is het voorspellen van de kans dat een gebruiker binnen een bepaalde tijd herhaaldelijk naar een liedje zal luisteren. In de dataset wordt de voorspelling als 1 gemarkeerd als de gebruiker binnen een maand naar hetzelfde liedje heeft geluisterd. De dataset bestaat uit welke song door welke gebruiker is gehoord en op welk tijdstip.
Wilt u een aanbevelingssysteem bouwen – bekijk dan hier dit opgeloste ML-project – Music Recommendation Machine Learning Project
Human Activity Recognition using Smartphone Dataset
De smartphone-dataset bestaat uit opnames van fitnessactiviteiten van 30 mensen die zijn vastgelegd via smartphones met inertiële sensoren. Het doel van dit machine-learningproject is om een classificatiemodel te bouwen dat menselijke fitnessactiviteiten nauwkeurig kan identificeren. Werken aan dit machine learning project zal u helpen begrijpen hoe multi-classificatie problemen op te lossen.
Krijg hier toegang tot de broncode van dit ML-projecten Human Activity Recognition using Smartphone Dataset Project
Klik hier om een lijst met 50+ opgeloste, end-to-end Big Data en Machine Learning Projectoplossingen (herbruikbare code + video’s)
Voorspeller van aandelenkoersen met behulp van tijdreeksen
Dit is nog een interessant machine learning-projectidee voor datawetenschappers/machine learning-engineers die werken of van plan zijn te werken met het financiële domein. Een aandelenkoersvoorspeller is een systeem dat leert over de prestaties van een bedrijf en toekomstige aandelenkoersen voorspelt. De uitdagingen bij het werken met gegevens over aandelenkoersen is dat deze zeer granulair zijn, en bovendien zijn er verschillende soorten gegevens zoals volatiliteitsindices, prijzen, wereldwijde macro-economische indicatoren, fundamentele indicatoren, en meer. Een voordeel van het werken met beursgegevens is dat de financiële markten kortere feedback cycli hebben, waardoor het voor data-experts gemakkelijker is om hun voorspellingen te valideren op nieuwe gegevens. Om te beginnen met het werken met beursgegevens, kunt u een eenvoudig machine learning probleem oppakken, zoals het voorspellen van 6-maandse koersbewegingen op basis van fundamentele indicatoren uit het kwartaalrapport van een organisatie. Je kunt datasets van de aandelenmarkt downloaden van Quandl.com of Quantopian.com. Er zijn verschillende tijdreeksvoorspellingsmethoden om aandelenkoers, vraag, enz. te voorspellen.
Kijk eens naar dit machine learning project waar je leert om te bepalen welke voorspellingsmethode wanneer moet worden gebruikt en hoe toe te passen met tijdreeksvoorspellingsvoorbeeld. Stock Prices Predictor using TimeSeries Project
Predicting Wine Quality using Wine Quality Dataset
Het is een bekend feit dat hoe ouder de wijn, hoe beter de smaak. Er zijn echter verschillende andere factoren dan leeftijd die een rol spelen bij de certificering van de wijnkwaliteit, waaronder fysiochemische tests zoals de hoeveelheid alcohol, het vaste zuurgehalte, het vluchtige zuurgehalte, de bepaling van de dichtheid, de pH, en nog veel meer. Het hoofddoel van dit machine-learning project is het bouwen van een machine-learning model om de kwaliteit van wijnen te voorspellen door het onderzoeken van hun verschillende chemische eigenschappen. De dataset voor wijnkwaliteit bestaat uit 4898 waarnemingen met 11 onafhankelijke en 1 afhankelijke variabele.
Krijg hier toegang tot de volledige oplossing van dit machine learning-project – Wine Quality Prediction in R
MNIST Handwritten Digit Classification
Diep leren en neurale netwerken spelen een vitale rol in beeldherkenning, automatische tekstgeneratie, en zelfs zelfrijdende auto’s. Om op deze gebieden aan de slag te gaan, moet je beginnen met een eenvoudige en beheersbare dataset, zoals de MNIST-dataset. Het is moeilijk om te werken met beeldgegevens boven platte relationele gegevens en als beginner stellen we voor dat je de MNIST Handwritten Digit Classification Challenge oppakt en oplost. De MNIST dataset is te klein om in het geheugen van uw PC te passen en is beginnersvriendelijk. Handgeschreven cijferherkenning zal u echter uitdagen.
Maak uw klassieke entree in het oplossen van beeldherkenningsproblemen door hier toegang te krijgen tot de volledige oplossing – MNIST Handwritten Digit Classification Project
Leer aanbevelingssystemen te bouwen met Movielens Dataset
Van Netflix tot Hulu, de behoefte om een efficiënt filmaanbevelingssysteem te bouwen is in de loop der tijd steeds belangrijker geworden door de toenemende vraag van moderne consumenten naar aangepaste inhoud. Een van de populairste datasets op het web voor beginners om te leren recommender systemen te bouwen is de Movielens Dataset, die ongeveer 1.000.209 filmwaarderingen bevat van 3.900 films gemaakt door 6.040 Movielens gebruikers. Je kunt met deze dataset aan de slag door een world-cloud visualisatie van filmtitels te bouwen om een movie recommender system te bouwen.
Gratis toegang tot opgeloste codevoorbeelden vind je hier (deze zijn kant-en-klaar voor je ML-projecten)
Boston Housing Price Prediction ML Project
Boston House Prices Dataset bestaat uit prijzen van huizen op verschillende plaatsen in Boston. De dataset bestaat ook uit informatie over gebieden met niet-winkels (INDUS), misdaadcijfers (CRIM), leeftijd van mensen die een huis bezitten (AGE), en verschillende andere attributen (de dataset heeft een totaal van 14 attributen). De Boston Housing dataset kan worden gedownload van de UCI Machine Learning Repository. Het doel van dit machine learning project is de verkoopprijs van een nieuw huis te voorspellen door basis machine learning concepten toe te passen op de huizenprijzen data. Deze dataset is met 506 waarnemingen te klein en wordt beschouwd als een goede start voor beginners op het gebied van machinaal leren om hun praktijkervaring met regressieconcepten op te doen.
Aanbevolen lectuur – 15+ Data Science-projecten voor beginners
Social Media Sentiment Analysis using Twitter Dataset
Social media-platforms zoals Twitter, Facebook, YouTube en Reddit genereren enorme hoeveelheden big data die op verschillende manieren kunnen worden ontgonnen om trends, publieke sentimenten en meningen te begrijpen. Sociale-mediagegevens zijn vandaag relevant geworden voor branding, marketing en het bedrijfsleven in zijn geheel. Een sentiment analyzer leert over verschillende sentimenten achter een “content stuk” (kan IM, e-mail, tweet, of een andere sociale media post) door middel van machine learning en voorspelt hetzelfde met behulp van AI.Twitter data wordt beschouwd als een definitieve ingang voor beginners om sentiment analyse machine learning problemen te oefenen. Met behulp van de Twitter dataset, kan men een boeiende mix van tweet inhoud en andere gerelateerde metadata zoals hashtags, retweets, locatie, gebruikers, en nog veel meer die de weg vrijmaken voor inzichtelijke analyse. De Twitter dataset bestaat uit 31.962 tweets en is 3MB groot. Met behulp van Twitter-gegevens kunt u erachter komen wat de wereld zegt over een onderwerp, of het nu gaat om films, sentimenten over de Amerikaanse verkiezingen, of een ander trending topic zoals voorspellen wie de FIFA World Cup 2018 zou winnen. Werken met de Twitter dataset zal je helpen de uitdagingen te begrijpen die gepaard gaan met social media data mining en ook diepgaand leren over classifiers. Het eerste probleem waar je als beginner mee aan de slag kunt, is het bouwen van een model om tweets als positief of negatief te classificeren.
Gratis toegang tot opgeloste code Python- en R-voorbeelden zijn hier te vinden (deze zijn kant-en-klaar voor uw Data Science- en ML-projecten)
Iris Flowers Classification ML Project- Learn about Supervised Machine Learning Algorithms
Dit is een van de meest eenvoudige machine learning-projecten waarbij Iris Flowers de eenvoudigste machine learning-datasets in de classificatieliteratuur zijn. Dit machine-learning probleem wordt vaak de “Hello World” van machine-learning genoemd. De dataset heeft numerieke attributen en ML beginners moeten uitzoeken hoe ze de data moeten laden en verwerken. De iris dataset is klein die gemakkelijk past in het geheugen en vereist geen speciale transformaties of schaling, om te beginnen.
Iris Dataset kan worden gedownload van UCI ML Repository – Download Iris Flowers Dataset
Het doel van dit machine learning project is om de bloemen te classificeren in een van de drie soorten – virginica, setosa, of versicolor op basis van lengte en breedte van bloemblaadjes en kelkblaadjes.
Gratis toegang tot opgeloste machine learning Python en R code voorbeelden zijn hier te vinden (deze zijn klaar voor gebruik voor uw projecten)
Machine Learning Projecten voor beginners met broncode in Python voor 2021
12) Retail Price Optimization ML Project – Dynamic Pricing Machine Learning Model voor een dynamische markt
Prijswedstrijden groeien non-stop in elke industrie verticale en het optimaliseren van de prijzen is de sleutel tot het efficiënt beheren van de winst voor elk bedrijf. Het identificeren van een redelijke prijsklasse en het maken van een aanpassing aan de prijsstelling van producten om de verkoop te verhogen en tegelijkertijd de winstmarges optimaal te houden is altijd een grote uitdaging geweest in de detailhandel. De snelste manier waarop retailers vandaag de hoogste ROI kunnen garanderen en tegelijk de prijsstelling kunnen optimaliseren, is door gebruik te maken van de kracht van machine learning om effectieve prijsoplossingen te bouwen. E-commercegigant Amazon was een van de eerste gebruikers van machine learning in retailprijsoptimalisatie, wat heeft bijgedragen aan de enorme groei van 30 miljard in 2008 tot ongeveer 1 biljoen in 2019.

Image Credit: spd. group
100+ Datasets for Machine Learning Projects Curated Specially For You
De oplossing voor retailprijsoptimalisatie machine learning-problemen vereist het trainen van een machine learning-model dat in staat is om automatisch de prijs van producten te bepalen zoals ze door mensen zouden worden geprijsd. Retail prijs optimalisatie machine learning modellen nemen in historische verkoopgegevens, verschillende kenmerken van de producten, en andere ongestructureerde gegevens zoals afbeeldingen en tekstuele informatie om de prijsstelling regels te leren zonder menselijke tussenkomst helpen retailers aan te passen aan een dynamische prijsstelling omgeving om de omzet te maximaliseren zonder verlies op winstmarges. Het machine-learningalgoritme voor optimalisatie van detailhandelsprijzen verwerkt een oneindig aantal prijsscenario’s om in realtime de optimale prijs voor een product te selecteren door duizenden latente relaties binnen een product in overweging te nemen.
Kijk naar dit coole machine-learningproject over optimalisatie van detailhandelsprijzen voor een diepe duik in real-life verkoopgegevensanalyse voor een café waar u een end-to-end machine-learningoplossing zult bouwen die automatisch de juiste productprijzen suggereert.
13) Customer Churn Prediction Analysis Using Ensemble Techniques in Machine Learning
Klanten zijn het grootste goed van een bedrijf en het behouden van klanten is belangrijk voor elk bedrijf om de inkomsten te stimuleren en een langdurige betekenisvolle relatie met klanten op te bouwen. Bovendien zijn de kosten van het verwerven van een nieuwe klant vijf keer hoger dan die van het behouden van een bestaande klant. Customer Churn/Attrition is een van de meest erkende problemen in het bedrijfsleven waar klanten of abonnees stoppen met zaken doen met een dienst of een bedrijf. In het ideale geval houden ze op een betaalde klant te zijn. Een klant wordt gezegd te zijn churned als een bepaalde hoeveelheid tijd is verstreken sinds de klant voor het laatst interactie had met het bedrijf.
Identificeren of en wanneer een klant zal churned en snel leveren van bruikbare informatie gericht op klantbehoud is van cruciaal belang voor het verminderen van churn. Het is niet mogelijk voor onze hersenen om klantenchurn voor miljoenen klanten voor te zijn, dit is waar machine learning kan helpen. Machine learning biedt effectieve methoden voor het identificeren van de onderliggende factoren van churn en proactieve tools om deze aan te pakken. Machine learning-algoritmen spelen een cruciale rol in proactief churn-beheer omdat ze gedragspatronen blootleggen van klanten die al zijn gestopt met het gebruik van de diensten of het kopen van producten. Vervolgens toetsen de machine learning-modellen het gedrag van de bestaande klanten aan dergelijke patronen om potentiële churners te identificeren.

Image Credit. :gallery.azure.ai
Maar hoe begin je met het oplossen van het customer churn rate predictiction machine learning-probleem? Net als elk ander machine learning-probleem moeten gegevenswetenschappers of machine learning-ingenieurs de gegevens verzamelen en voorbereiden op verwerking. Om een machine learning aanpak effectief te laten zijn, is het zinvol om de data in het juiste formaat te engineeren. Feature Engineering is het meest creatieve deel van het churn-voorspellende machine-leermodel waarbij dataspecialisten hun ervaring, bedrijfscontext, domeinkennis van de gegevens en creativiteit gebruiken om features te creëren en het machine-leermodel op maat te maken om te begrijpen waarom klantenchurn in een specifiek bedrijf plaatsvindt.
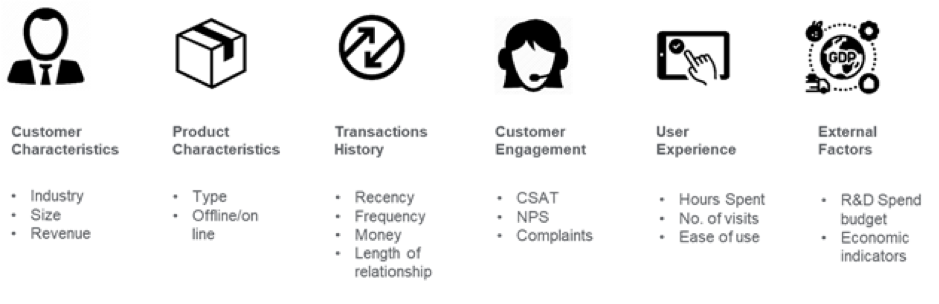
Image Credit: medium.com
In de banksector kunnen twee accounts die dezelfde maandelijkse eindsaldo hebben bijvoorbeeld moeilijk te onderscheiden zijn voor churn-voorspelling. Maar feature engineering kan een tijdsdimensie toevoegen aan deze gegevens, zodat ML-algoritmen kunnen onderscheiden of het maandelijkse eindsaldo is afgeweken van wat gewoonlijk van een klant wordt verwacht. Indicatoren zoals slapende rekeningen, toenemende opnames, gebruikstrends, nettosaldo-uitstroom over de laatste paar dagen kunnen vroege waarschuwingssignalen van churn zijn. Deze interne gegevens in combinatie met externe gegevens zoals aanbiedingen van concurrenten kunnen helpen bij het voorspellen van klantenchurn. Als de kenmerken zijn geïdentificeerd, is de volgende stap te begrijpen waarom churns zich voordoen in een zakelijke context en de kenmerken te verwijderen die geen sterke voorspellers zijn om de dimensionaliteit te verminderen.
Kijk eens naar dit end-to-end machine learning-project met broncode in Python over Customer Churn Prediction Analysis using Ensemble Learning to combat churn.
Hoe begin ik een machine learning-project?
Geen project vordert met succes zonder gedegen planning, en machine learning is daarop geen uitzondering. Het bouwen van uw eerste machine learning project is eigenlijk niet zo moeilijk als het lijkt, mits je een solide planning strategie. Om een ML-project te starten, moet men een uitgebreide end-to-end aanpak volgen -van project scoping tot model deployment en beheer in productie Hier is onze kijk op de fundamentele stappen van een machine learning projectplan om ervoor te zorgen dat u het meeste uit elk uniek project haalt –
1) Eerste stap: Machine Learning Project Scoping
Voordat u iets anders doet, moet u begrijpen wat de zakelijke vereisten van het ML-project zijn. Bij het starten van een ML-project is het selecteren van de relevante business use case waarvoor het machine learning model zal worden gebouwd, de fundamentele stap. Het kiezen van de juiste machine learning use case en het evalueren van de ROI is belangrijk voor het succes van elk machine learning project.
2) Tweede stap: Data
Data is het levensbloed van elk machine learning model en het is onmogelijk om een machine learning model te trainen zonder data. De gegevensfase in de levenscyclus van een machine-learningproject bestaat uit vier stappen –
-
Gegevensvereisten – Het is belangrijk te begrijpen welk soort gegevens nodig zal zijn, het formaat van de gegevens, de gegevensbronnen en de nalevingsvereisten van de gegevensbronnen.
-
Gegevensverzameling – Met de hulp van databankbeheerders, gegevensarchitecten of ontwikkelaars moet u de strategie voor gegevensverzameling opzetten om gegevens te extraheren van plaatsen waar ze binnen de organisatie leven of van andere leveranciers van derde partijen.
-
Exploratieve gegevensanalyse – In deze stap worden de gegevensvereisten gevalideerd om te controleren of u over de juiste gegevens beschikt, of de gegevens in goede staat zijn en geen fouten bevatten.
-
Gegevensvoorbereiding – In deze stap worden de gegevens voorbereid voor gebruik door algoritmen voor machinaal leren. Foutcorrectie, feature engineering, codering tot gegevensformaten die machines kunnen begrijpen, en correctie van anomalieën zijn de taken die bij gegevensvoorbereiding komen kijken.
3) Derde stap – Model bouwen
Afhankelijk van de aard van het project kan deze stap een paar dagen of maanden duren. In de modelleringsfase beslist u welk algoritme voor machinaal leren u wilt gebruiken en begint u het model op de gegevens te trainen. Inzicht in de maatstaven voor nauwkeurigheid, fouten en correctheid waaraan een model voor machinaal leren moet voldoen, is belangrijk voor de modelselectie. Nadat het model is getraind, evalueert u het op validatiegegevens om de prestaties te analyseren en overfitting te voorkomen. De evaluatie van het model is een kritieke stap, want als een model perfect werkt met historische gegevens en slecht presteert met toekomstige gegevens, heeft het geen nut.
4) Vierde stap – Model uitrollen in productie
Deze stap omvat het uitrollen van software of app naar eindgebruikers, zodat nieuwe gegevens in het machine learning-model kunnen stromen om verder te leren. Het uitrollen van het model voor machinaal leren is niet voldoende, u moet er ook voor zorgen dat het model voor machinaal leren presteert zoals verwacht. U moet uw model opnieuw trainen op de nieuwe live productiegegevens om de nauwkeurigheid of de prestaties te garanderen – dit is model tuning. Modelafstemming vereist ook validatie van het model om ervoor te zorgen dat het niet afwijkt of vertekend raakt.
Hoe zet je machine learning-projecten op je cv?
Echte-wereldervaring bereidt je als niets anders voor op uiteindelijk succes. Als beginner in machine learning geldt: hoe meer realtime ervaring je kunt opdoen met het werken aan machine learning-projecten, hoe beter je bent voorbereid om de heetste banen van het decennium te grijpen. Het krijgen van een machine learning baan na het voltooien van data science training of succesvol worden als een data scientist zal afhangen van je vermogen om jezelf te verkopen. Na het volgen van een uitgebreide data science training, is de volgende stap om een top gig als een machine learning engineer of een data scientist te landen het bouwen van een uitstekende portfolio om uw vermogen om machine learning technieken toe te passen aan uw toekomstige werkgevers te laten zien. Werken aan interessante ML-projecten is een geweldige manier om je carrière als enterprise machine learning engineer of data scientist een kick-start te geven. Werkgevers willen zien aan wat voor soort projecten met betrekking tot data science en machine learning je hebt gewerkt om het bereik van je capaciteiten in het doen van data science en machine learning te evalueren. Leuke, coole en interessante voorbeelden van projecten op het gebied van data science en machine learning in je cv leggen meer gewicht in de schaal dan vertellen hoeveel je weet. Hier is hoe je geweldige projecten kunt toevoegen aan je machine learning cv –
- Je kunt de machine learning-projecten direct na je werkervaringsectie in het machine learning cv vermelden.
- Volg een opeenvolgende volgorde van nummering samen met de titel van de projecten waaraan je hebt gewerkt.
- De titel van het project moet worden gevolgd door een klein kort over de dataset en de probleemstelling.
- Melding van de machine learning tools en technologieën die u hebt gebruikt voor het voltooien van een project.
- Last but not the least, in uw portfolio / cv link elke machine leren project naar GitHub, persoonlijke website, of blog voor een diepgaand inzicht in uw prestaties.
Of u nu een sterke machine learning portfolio wilt opbouwen of u wilt analytische vaardigheden oefenen die u hebt geleerd in uw data science training, we hebben je gedekt. Veel beginners op het gebied van machine learning weten niet zeker waar ze moeten beginnen, welke machine learning-projecten ze moeten doen, welke machine learning-tools, -technieken en -frameworks ze moeten gebruiken. We hebben het een probleemloze taak voor data science en machine learning beginners door het cureren van een lijst met interessante ideeën voor machine learning projecten, samen met hun oplossingen. Deze machine learning projecten ideeën zijn afkomstig van populaire Kaggle data science uitdagingen en zijn een geweldige manier om machine learning te leren. Deze lijst van projecten is een perfecte manier om machine learning projecten op je cv te zetten. De juiste mindset, bereidheid om te leren, en veel data-exploratie zijn allemaal vereist om de oplossing voor projecten op het gebied van data science en machine learning te begrijpen. U kunt 50 + data science en ML-projecten verkennen op basis van de set vaardigheden, tools en technieken die u moet leren.
Voordat u aan uw project begint, is het handig om toegang te hebben tot een bibliotheek met machine learning-projectcodevoorbeelden. Dus op elk moment dat u vastzit op het project kunt u deze opgeloste voorbeelden gebruiken om los te komen.
Toegang Data Science en Machine Learning Project Code Examples
What Next?
One kan een meester in machine learning worden alleen met veel oefening en experimenteren. Theoretische kennis hebben helpt zeker, maar het is de toepassing die het meest helpt vooruitgang te boeken. Geen enkele hoeveelheid theoretische kennis kan de praktijk vervangen. Het zal echter helpen als je jezelf eerst vertrouwd maakt met de hierboven genoemde innovatieve machine learning-projecten.
Als je een beginner bent en nieuw bent voor machine learning, dan zal het werken aan machine learning-projecten die zijn ontworpen door experts uit de industrie bij ProjectPro een aantal van de beste investeringen van je tijd zijn. Deze projecten zijn ontworpen voor beginners om hen te helpen hun toegepaste machine learning-vaardigheden snel te verbeteren, terwijl ze hen een kans geven om interessante zakelijke use cases in verschillende domeinen te verkennen – Retail, Finance, Insurance, Manufacturing, en nog veel meer. Dus, als u wilt genieten van het leren van machine learning, gemotiveerd wilt blijven en snel vooruitgang wilt boeken, dan zijn de interessante ML-projecten van ProjectPro iets voor u. Bovendien kun je deze machine learning-projecten aan je portfolio toevoegen en een topklus binnenhalen met een hoger salaris en lonende extraatjes.

Klik hier voor een lijst met meer dan 50 opgeloste, end-to-end projectoplossingen in Machine Learning en Big Data
|
VORIGE |
NEXT |