
Door: Aaron Bertrand | Bijgewerkt: 2019-12-03 | Comments (1) | Related: Meer > Performance Tuning
Probleem
Enkele jaren geleden heb ik geblogd over hoe je de impact op het transactielog kunt verminderen door verwijderbewerkingen in brokken op te splitsen. In plaats van 100.000 rijen in één grote transactie te verwijderen, kun je 100 of 1.000 of een willekeurig aantal rijen per keer verwijderen, in verschillende kleinere transacties, in een lus. Naast het verminderen van de impact op het log, kun je zo ook langdurige blokkeringen tegengaan. In die tijd waren SSD’s nog maar net op gang gekomen, en nieuwere technologieën zoalsClustered Columnstore Indexes,Delayed Durability, enAccelerated Database Recovery bestonden nog niet. Dus, ik dacht dat het misschien tijd was voor een opfrissing om een beter beeld te geven van hoe dit uitpakt in SQL Server 2019.
Oplossing
Het verwijderen van grote delen van een tabel is niet altijd het enige antwoord. Als u 95% van een tabel verwijdert en 5% behoudt, kan het eigenlijk sneller zijn om de rijen die u wilt behouden naar een nieuwe tabel te verplaatsen, de oude tabel te verwijderen en de nieuwe tabel een nieuwe naam te geven. Of kopieer de rijen die u wilt behouden naar buiten, maak de tabel leeg en kopieer ze er vervolgens weer in. Maar zelfs als de zuivering zoveel groter is dan de bewaar, is dit niet altijd mogelijk vanwege andere beperkingen op de tabel, SLA’s, en andere factoren.
Wederom, als blijkt dat je rijen moet verwijderen, wil je de impact op het transactielogboek minimaliseren en hoe de operaties de rest van de werklast beïnvloeden.De chunking aanpak is geen nieuw of nieuw idee, maar het kan goed werken met een aantal van deze nieuwere technologieën, dus laten we ze op de proef stellen in een verscheidenheid van combinaties.
Om op te zetten, hebben we meerdere constanten die bij elke test waar zullen zijn:
- SQL Server 2019 RC1, met vier cores en 32 GB RAM (max servergeheugen =28 GB)
- 10 miljoen rijen tabel
- Restart SQL Server na elke test (om geheugen, buffers te resetten, en plancache)
- Herstel een backup waarin de stats al zijn bijgewerkt en auto-stats uitgeschakeld (om te voorkomen dat getriggerde stats updates interfereren met verwijder operaties)
We hebben ook veel variabelen die zullen veranderen per test:
Dit levert 864 unieke tests op, en geloof maar dat ik al die permutaties ga automatiseren.
En de metriek die we zullen meten:
- Alle duur
- Gemiddeld/piek CPU-gebruik
- Gemiddeld/piek geheugengebruik
- Transactieloggebruik/bestandsgroei
- Databasebestandsgebruik, grootte van version store (bij gebruik van Accelerated DatabaseRecovery)
- Delta rowgroup grootte (bij gebruik van Columnstore)
Brontabel
Eerst heb ik een kopie van AdventureWorks teruggezet (AdventureWorks2017.bak, om precies te zijn). Om een tabel met 10 miljoen rijen te maken, heb ik een kopie gemaakt van Sales.SalesOrderDetail, met zijn eigen identiteitskolom, en voegde een vulkolom toe om elke rij wat meer vlees te geven en de paginadichtheid te verminderen:
CREATE TABLE dbo.SalesOrderDetailCopy
(
SalesOrderDetailID int IDENTITY,
SalesOrderID int,
CarrierTrackingNumber nvarchar(25),
OrderQty smallint,
ProductID int,
SpecialOfferID int,
UnitPrice money,
UnitPriceDiscount money,
LineTotal numeric(38,6),
rowguid uniqueidentifier,
ModifiedDate datetime,
filler char(50) NOT NULL DEFAULT ''
);
GO
Om de 10.000.000 rijen te genereren, voegde ik vervolgens 100.000 rijen tegelijk in, en voegde 100 keer in:
INSERT dbo.SalesOrderDetailCopy
(
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
)
SELECT TOP(100000)
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
FROM Sales.SalesOrderDetail;GO 100
Ik heb geen indexen op de tabel gemaakt; afhankelijk van de opslagbenadering zal ik een nieuwe geclusterde index maken (columnstore de helft van de tijd) nadat de database is hersteld als onderdeel van elke test.
Automating Tests
Eenmaal de 10 miljoen rijen tellende tabel bestond, stelde ik een paar opties in, maakte een back-up van de database, maakte twee keer een back-up van het log, en maakte toen weer een back-up van de database (zodat het log zo min mogelijk gebruikte ruimte zou hebben wanneer het hersteld zou worden):
Daarna maakte ik een Control database, waar ik de opgeslagen procedures zou opslaan die de tests zouden uitvoeren, en de tabellen die de testresultaten zouden bevatten (alleen de begin- en eindtijd van elke test) en de prestatie metrieken die gedurende alle tests zouden worden vastgelegd.
Het vastleggen van de permutaties van alle 864 tests die ik wilde uitvoeren kostte een paar pogingen, maar ik eindigde met dit:
Zoals verwacht, voegde dit 864 rijen in met al die combinaties.
Volgende, creëerde ik een opgeslagen procedure om de set van eerder beschreven metrieken vast te leggen.Ik monitor de instantie ook metSentryOne SQL Sentry, dus er zal zeker nog andere interessante informatie beschikbaar zijn, maar ik wilde ook de belangrijke details vastleggen zonder gebruik te maken van tools van derden. Hier is de procedure, die alles in het werk stelt om alle metrieken voor een gegeven tijdstempel in een enkele rij te produceren:
Ik heb die opgeslagen procedure in een job step gezet en hem gestart. Misschien wilt u een andere vertraging dan drie seconden gebruiken – er is een afweging tussen de kosten van het verzamelen en de volledigheid van de gegevens die meer de ene kant dan de andere voor u kan overhellen.
Ten slotte creëerde ik de procedure die alle logica zou bevatten om precies te bepalen wat te doen met de combinatie van parameters voor elke individuele test.Dit kostte weer een aantal iteraties, maar het eindproduct is als volgt:
Er gebeurt daar een heleboel, maar de basislogica is dit:
- Haal de testspecifieke gegevens (TestID en alle parameters) uit de dbo.Teststable
- Geef SQL Server een kick door een sp_configure wijziging uit te voeren en buffers en plan cache te wissen
- Herstel een schone kopie van AdventureWorks, met alle 10 miljoen rijen intact,en geen indexen
- Wijzig de opties van de database, afhankelijk van de parameters voor de huidige test
- Maak ofwel een geclusterde columnstore index of een geclusterde B-tree index
- Update stats on the table manually, voor de zekerheid
- Log dat we de test hebben gestart
- Bepaal hoeveel iteraties van de lus we nodig hebben, en hoeveel rijen we binnen elke iteratie moeten verwijderen
- Binnen de lus:
- Bepaal of we een transactie moeten starten op deze iteratie
- Uitvoeren van de verwijdering
- Bepaal of we de transactie moeten committen op deze iteratie
- Bepaal of we een checkpoint / back-up van het logboek moeten maken op deze iteratie
- Na de lus, loggen we dat deze test is voltooid, en commit eventuele uncommittedtransacties
Om de test daadwerkelijk uit te voeren, wil ik niet om dit te doen in Management Studio (zelfs op dezelfde VM), vanwege alle output, extra verkeer, en het gebruik van hulpbronnen.Ik heb een stored procedure gemaakt en deze ook in een job gezet:
Dat duurde veel langer dan ik graag wil toegeven. Een deel daarvan was omdat ik oorspronkelijk een 0.1% test had opgenomen voor rowperloop die, in sommige gevallen, enkele uren duurde. Dus heb ik die een paar dagen later uit de tabel verwijderd, en ik kan gemakkelijk zeggen: als je 1.000.000 rijen verwijdert, is het zeer onwaarschijnlijk dat het verwijderen van 1.000 rijen per keer een optimale keuze is, ongeacht andere variabelen:

(Hoewel dat een afwijking lijkt te zijn vergeleken met de meeste andere tests, durf ik te wedden dat dat niet veel sneller zou zijn dan het verwijderen van één rij of 10 rijen per keer. En in feite was het langzamer dan het verwijderen van de helft van de tabel of het grootste deel van de tabel in elk ander scenario.)
Resultaten
Nadat ik de resultaten van de 0,1%-tests had weggegooid, zette ik de rest in een tweede metriekentabel met de duur geladen:
Ik moest een outer join gebruiken op de metriekentabel omdat sommige tests zo snel liepen dat er niet genoeg tijd was om gegevens vast te leggen. Dit betekent dat, voor sommige van de snellere tests, er geen correlatie zal zijn met andere performancedetails anders dan hoe snel ze liepen.
Daarna begon ik te zoeken naar trends en anomalieën. Eerst heb ik de duur en CPU bekeken op basis van de vraag of Delayed Durability (DD) en/of Accelerated Database Recovery (ADR) waren ingeschakeld:
Resultaten (met anomalieën gemarkeerd):

Het lijkt erop dat de totale duur gemiddeld ongeveer evenveel wordt verbeterd als een van beide opties is ingeschakeld (of beide – en als beide zijn ingeschakeld, is de piek lager). Er lijkt een uitbijter te zijn voor ADR alleen die geen invloed heeft op het gemiddelde (deze specifieke test bestond uit het verwijderen van 9.000.000 rijen, 90.000 rijen per keer, in FULL recovery, op een rowstore tabel). De CPU-uitschieter voor DD had ook geen invloed op het gemiddelde – dit specifieke voorbeeld was het verwijderen van 1.000.000 rijen, allemaal tegelijk, op een columnstore tabel.
Hoe zit het met de algemene verschillen tussen rowstore en columnstore?
Resultaten:

Columnstore is gemiddeld 20% langzamer, maar heeft minder geheugen nodig. Ik wilde ook zien wat het effect was op de grootte en het gebruik van gegevensbestanden en logbestanden:
Resultaten:

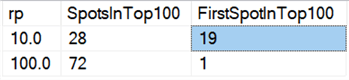
Ten slotte lijkt het verwijderen in brokken op de huidige hardware niet meer dezelfde voordelen te hebben als vroeger, althans wat de duur betreft. De 18 snelste resultaten hier, en 72 van de snelste 100, waren tests waarbij alle rijen in één keer werden verwijderd, zoals blijkt uit deze query:
Resultaten:
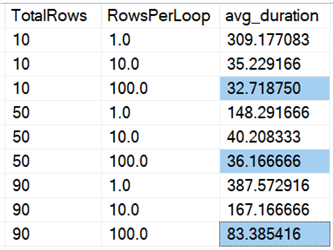
En als we kijken naar gemiddelden over alle gegevens, zoals in deze query:
We zien dat het in één keer verwijderen van alle rijen, ongeacht of we 10%, 50% of 90% verwijderen, sneller is dan het in groepen verwijderen op welke manier dan ook (opnieuw, gemiddeld):
In grafiekvorm:
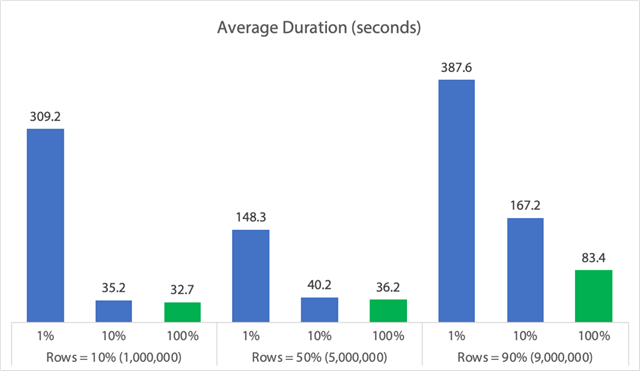
(Merk op dat als we de eerder geïdentificeerde max_durationoutlier van 6,062 seconden eruit halen, de eerste kolom daalt van 309 seconden naar 162 seconden.
Nu, zelfs in het beste geval, is dat nog steeds 33, 36 of 83 seconden waarin een verwijderopdracht wordt uitgevoerd en mogelijk iedereen wordt geblokkeerd, en dan hebben we het nog niet over andere gemeten gevolgen, zoals geheugen, logbestand, CPU, enzovoort. Duur zou zeker niet je enige criterium moeten zijn; het is gewoon dat het meestal het eerste (en soms enige) is waar mensen naar kijken. Deze test is bedoeld om te laten zien dat je ook andere metrieken kunt en moet meten, en de resultaten laten zien dat uitschieters overal vandaan kunnen komen.
Met deze testopstelling als model, kun je je eigen tests construeren die meer zijn toegespitst op de beperkingen en mogelijkheden in je omgeving. Ik heb de metriek niet vanuit alle mogelijke hoeken benaderd, omdat dat veel permutaties zijn, maar ik ga deze database bijhouden. Dus, als er andere manieren zijn om de gegevens opgesplitst te zien, laat het me weten in de commentaren hieronder, en ik zal zien wat ik kan doen. Vraag me alleen niet om alle tests opnieuw uit te voeren.
Caveats
Dit alles houdt geen rekening met een gelijktijdige werkbelasting, de invloed van tabelrestricties zoals foreign keys, de aanwezigheid van triggers, en een groot aantal andere mogelijke scenario’s.Iets anders om te testen (mogelijk in een toekomstige tip) is om meerdere jobs te hebben die interageren met dezelfde tabel gedurende de operatie, en dingen te meten als duur van blokkades, wachttypes en -tijden, en te meten in welke situaties de ene set activiteiten een dramatischere impact heeft op de andere set.
Next Steps
Lees verder voor gerelateerde tips en andere bronnen:
- CRUD-bewerkingen in SQL Server
- Verschillen tussen Delete en Truncate in SQL Server
- Historische gegevens verwijderen uit een grote, sterk gelijktijdige SQL Server DatabaseTabel
- Breek grote verwijderbewerkingen op in stukken
- SQL Server Clustered and Nonclustered Columnstore Index Example
- Delayed Durability in SQL Server 2014
- Delayed Durability while Purging Data
- Accelerated Database Recovery in SQL Server 2019
Last bijgewerkt: 2019-12-03


Over de auteur
 Aaron Bertrand (@AaronBertrand) is een gepassioneerd technoloog met ervaring in de industrie die teruggaat tot Classic ASP en SQL Server 6.5. Hij is hoofdredacteur van de prestatie-gerelateerde blog, SQLPerformance.com, en blogt ook op sqlblog.org.
Aaron Bertrand (@AaronBertrand) is een gepassioneerd technoloog met ervaring in de industrie die teruggaat tot Classic ASP en SQL Server 6.5. Hij is hoofdredacteur van de prestatie-gerelateerde blog, SQLPerformance.com, en blogt ook op sqlblog.org.Bekijk al mijn tips
- Meer SQL Server DBA Tips…