
- Obțineți acces la proiecte ML de top
- Proiecte de învățare automată pentru începători în 2021
- Sales Forecasting using Walmart Dataset
- BigMart Sales Prediction ML Project
- Music Recommendation System Project
- Human Activity Recognition using Smartphone Dataset
- Stock Prices Predictor using TimeSeries
- Predicting Wine Quality using Wine Quality Dataset
- MNIST Clasificarea cifrelor scrise de mână
- Învățați să construiți sisteme de recomandare cu setul de date Movielens
- Proiect ML de predicție a prețului locuințelor din Boston
- Analiza sentimentelor din social media folosind Twitter Dataset
- Iris Flowers Classification ML Project
- Retail Price Optimization using Machine Learning
- Customer Churn Prediction Analysis
- 1. Predicția vânzărilor utilizând setul de date Walmart
- 2. BigMart Sales Prediction ML Project – Learn about Unsupervised Machine Learning Algorithms
- Music Recommendation System Project
- Human Activity Recognition using Smartphone Dataset
- Stock Prices Predictor using TimeSeries
- Predicerea calității vinului folosind setul de date privind calitatea vinului
- MNIST Handwritten Digit Classification
- Învățați să construiți sisteme de recomandare cu setul de date Movielens
- Boston Housing Price Prediction ML Project
- Social Media Sentiment Analysis using Twitter Dataset
- Iris Flowers Classification ML Project- Learn about Supervised Machine Learning Algorithms
- Proiecte de învățare automată pentru începători cu cod sursă în Python pentru 2021
- 12) Proiect ML de optimizare a prețurilor de vânzare cu amănuntul – Model de învățare automată a prețurilor dinamice pentru o piață dinamică
- 13) Analiza de predicție a renunțării clienților folosind tehnici de ansamblu în învățarea automată
- Cum încep un proiect de învățare automată?
- 1) Primul pas: Definirea domeniului de aplicare a proiectului de învățare automată
- 2) Al doilea pas: Date
- 3) Al treilea pas – Construirea modelului
- 4) Al patrulea pas -Dezvoltarea modelului în producție
- Cum puneți proiectele de învățare automată pe CV-ul dumneavoastră?
- Ce urmează?
Obțineți acces la proiecte ML de top
×
Ultima actualizare: 05 Mar 2021

Vreți să învățați învățarea automată, dar aveți probleme în a începe cu ea. Cărțile și cursurile s-ar putea să nu fie doar suficiente atunci când vine vorba de învățare automată, deși acestea oferă întotdeauna exemple de coduri și fragmente de învățare automată, nu aveți ocazia să implementați învățarea automată la probleme din lumea reală și să vedeți cum se potrivesc aceste fragmente de cod. Cel mai bun mod de a începe cu învățarea mașinilor este să implementați proiecte de învățare a mașinilor de la nivel începător la avansat. Este întotdeauna util să obțineți informații despre modul în care oamenii reali își încep cariera în domeniul învățării automate prin implementarea proiectelor ML de la un capăt la altul.
În această postare pe blog, veți afla cum începătorii ca și dvs. pot face progrese mari în aplicarea învățării automate la probleme din lumea reală cu aceste proiecte fantastice de învățare automată pentru începători recomandate de experții din industrie. Experții din industrie ProjectPro au curatoriat cu atenție lista de proiecte de top de învățare automată pentru începători care acoperă aspectele de bază ale învățării automate, cum ar fi învățarea supravegheată, învățarea nesupravegheată, învățarea profundă și rețelele neuronale. În toate aceste proiecte de învățare automată veți începe cu seturi de date din lumea reală care sunt disponibile în mod public. Vă asigurăm că veți găsi acest blog absolut interesant și merită să îl citiți datorită tuturor lucrurilor pe care le puteți învăța de aici despre cele mai populare proiecte de învățare automată.
„Ce proiecte pot face cu învățarea automată ?” Această întrebare ne este adresată foarte des de către începătorii care se inițiază în machine learning. Experții din industria ProjectPro vă recomandă să explorați câteva idei de proiecte de învățare automată interesante, interesante, distractive și ușoare din diverse domenii de afaceri pentru a obține experiență practică în ceea ce privește abilitățile de învățare automată pe care le-ați învățat. Am curatoriat o listă de proiecte inovatoare și interesante de învățare automată cu cod sursă pentru profesioniștii care își încep cariera în domeniul învățării automate. Aceste proiecte pentru începători în domeniul învățării automate sunt un amestec perfect de diverse tipuri de provocări pe care le poate întâlni cineva atunci când lucrează ca inginer de învățare automată sau cercetător de date.
Proiecte de învățare automată pentru începători în 2021
-
Sales Forecasting using Walmart Dataset
-
BigMart Sales Prediction ML Project
-
Music Recommendation System Project
-
Human Activity Recognition using Smartphone Dataset
-
Stock Prices Predictor using TimeSeries
-
Predicting Wine Quality using Wine Quality Dataset
-
MNIST Clasificarea cifrelor scrise de mână
-
Învățați să construiți sisteme de recomandare cu setul de date Movielens
-
Proiect ML de predicție a prețului locuințelor din Boston
-
-
Iris Flowers Classification ML Project
-
Retail Price Optimization using Machine Learning
-
Customer Churn Prediction Analysis
Să ne scufundăm!

1. Predicția vânzărilor utilizând setul de date Walmart
Prognoza vânzărilor este unul dintre cele mai comune cazuri de utilizare a învățării automate pentru identificarea factorilor care afectează vânzările unui produs și estimarea volumului vânzărilor viitoare. Acest proiect de învățare automată utilizează setul de date Walmart care conține date privind vânzările pentru 98 de produse din 45 de puncte de vânzare. Setul de date conține vânzări săptămânale pentru fiecare magazin, pentru fiecare departament. Scopul acestui proiect de învățare automată este de a prognoza vânzările pentru fiecare departament din fiecare punct de vânzare pentru a-i ajuta să ia decizii mai bune bazate pe date pentru optimizarea canalelor și planificarea stocurilor. Aspectul provocator al lucrului cu setul de date Walmart este faptul că acesta conține evenimente de reducere selectate care afectează vânzările și care trebuie luate în considerare.
Acesta este unul dintre cele mai simple și mai interesante proiecte de învățare automată în care veți construi un model predictiv folosind setul de date Walmart pentru a estima numărul de vânzări pe care le vor face în viitor și iată cum –
- Importați datele și explorați-le pentru a înțelege structura și valorile din cadrul datelor – Începeți prin importarea unui fișier CSV și efectuarea unei analize exploratorii de bază a datelor (EDA).
- Pregătiți datele pentru modelare – Uniți mai multe seturi de date și aplicați funcția de grupare după pentru a analiza datele.
- Plotați un grafic al seriilor de timp și analizați-l.
- Adaptați modelele dezvoltate de prognoză a vânzărilor la datele de instruire- Creați un model ARIMA pentru prognoza seriilor de timp
- Comparați modelele dezvoltate pe datele de testare.
- Optimizați modelele de prognoză a vânzărilor prin alegerea unor caracteristici importante pentru a îmbunătăți scorul de precizie.
- Utilizați cel mai bun model de învățare automată pentru a prezice vânzările de anul viitor.
După ce veți lucra la acest proiect Kaggle de învățare automată veți înțelege cum modelele puternice de învățare automată pot simplifica procesul general de prognoză a vânzărilor. Reutilizați aceste modele de învățare automată de prognoză a vânzărilor de la un capăt la altul în producție pentru a prognoza vânzările pentru orice departament sau magazin cu amănuntul.
Vreți să lucrați cu Walmart Dataset? Accesați soluția completă pentru acest proiect minunat de învățare automată aici – Walmart Store Sales Forecasting Machine Learning Project
2. BigMart Sales Prediction ML Project – Learn about Unsupervised Machine Learning Algorithms
BigMart sales dataset consists of 2013 sales data for 1559 products across 10 different outlets in different cities. Scopul proiectului ML de predicție a vânzărilor BigMart este de a construi un model de regresie pentru a prezice vânzările fiecăruia dintre cele 1559 de produse pentru anul următor în fiecare dintre cele 10 puncte de vânzare BigMart diferite. Setul de date privind vânzările BigMart constă, de asemenea, în anumite atribute pentru fiecare produs și magazin. Acest model ajută BigMart să înțeleagă proprietățile produselor și ale magazinelor care joacă un rol important în creșterea vânzărilor globale.
Accesați soluția completă a acestui proiect ML aici – BigMart Sales Prediction Machine Learning Project Solution
Music Recommendation System Project
Acest proiect este unul dintre cele mai populare proiecte de învățare automată și poate fi utilizat în diferite domenii. S-ar putea să fiți foarte familiarizat cu un sistem de recomandare dacă ați folosit vreun site de comerț electronic sau un site de filme/muzică. În majoritatea site-urilor de E-commerce, cum ar fi Amazon, în momentul efectuării comenzii, sistemul vă va recomanda produse care pot fi adăugate în coș. În mod similar, pe Netflix sau Spotify, pe baza filmelor care v-au plăcut, vă va arăta filme sau melodii similare care v-ar putea plăcea. Cum reușește sistemul să facă acest lucru? Acesta este un exemplu clasic în care se poate aplica Machine Learning.
În acest proiect, folosim setul de date de la cel mai important serviciu de streaming muzical din Asia pentru a construi un sistem de recomandare muzicală mai bun. Vom încerca să determinăm ce melodie nouă sau ce artist nou i-ar putea plăcea unui ascultător pe baza alegerilor sale anterioare. Sarcina principală este de a prezice șansele ca un utilizator să asculte o melodie în mod repetat într-un interval de timp. În setul de date, predicția este marcată cu 1 dacă utilizatorul a ascultat aceeași melodie în decurs de o lună. Setul de date constă în ce melodie a fost ascultată de către ce utilizator și la ce oră.
Vreți să construiți un sistem de recomandare – verificați acest proiect ML rezolvat aici – Music Recommendation Machine Learning Project
Human Activity Recognition using Smartphone Dataset
Setul de date pentru smartphone-uri constă în înregistrări ale activității de fitness a 30 de persoane capturate prin intermediul unor smartphone-uri dotate cu senzori inerțiali. Scopul acestui proiect de învățare automată este de a construi un model de clasificare care poate identifica cu precizie activitățile de fitness uman. Lucrul la acest proiect de învățare automată vă va ajuta să înțelegeți cum să rezolvați probleme de clasificare multiplă.
Obțineți acces la codul sursă al acestui proiect ML aici Human Activity Recognition using Smartphone Dataset Project
Click aici pentru a vedea o listă de 50+ proiecte rezolvate, end-to-end Big Data and Machine Learning Project Solutions (cod reutilizabil + videoclipuri)
Stock Prices Predictor using TimeSeries
Aceasta este o altă idee interesantă de proiect de învățare automată pentru cercetătorii de date/inginerii de învățare automată care lucrează sau intenționează să lucreze cu domeniul financiar. Un predictor al prețurilor acțiunilor este un sistem care învață despre performanța unei companii și prezice prețurile viitoare ale acțiunilor. Provocările asociate cu lucrul cu datele privind prețul acțiunilor sunt că acestea sunt foarte granulare și, în plus, există diferite tipuri de date, cum ar fi indici de volatilitate, prețuri, indicatori macroeconomici globali, indicatori fundamentali și altele. Un lucru bun în ceea ce privește lucrul cu datele bursiere este că piețele financiare au cicluri de feedback mai scurte, ceea ce face mai ușor pentru experții în date să își valideze predicțiile pe baza unor date noi. Pentru a începe să lucrați cu date de pe piața bursieră, puteți prelua o problemă simplă de învățare automată, cum ar fi prezicerea mișcărilor de preț pe 6 luni pe baza indicatorilor fundamentali din raportul trimestrial al unei organizații. Puteți descărca seturi de date privind piața bursieră de pe Quandl.com sau Quantopian.com. Există diferite metode de prognoză a seriilor de timp pentru a prognoza prețul acțiunilor, cererea etc.
Veziți acest proiect de învățare automată în care veți învăța să determinați ce metodă de prognoză să fie utilizată când și cum să o aplicați cu un exemplu de prognoză a seriilor de timp. Predicția prețurilor acțiunilor folosind proiectul TimeSeries
Predicerea calității vinului folosind setul de date privind calitatea vinului
Este un fapt cunoscut că, cu cât este mai vechi vinul, cu atât este mai bun gustul. Cu toate acestea, există mai mulți factori, alții decât vârsta, care intră în certificarea calității vinului, care includ teste fizico-chimice, cum ar fi cantitatea de alcool, aciditatea fixă, aciditatea volatilă, determinarea densității, pH-ul și altele. Scopul principal al acestui proiect de învățare automată este de a construi un model de învățare automată pentru a prezice calitatea vinurilor prin explorarea diferitelor proprietăți chimice ale acestora. Setul de date privind calitatea vinului este format din 4898 de observații cu 11 variabile independente și 1 variabilă dependentă.
Obțineți acces la soluția completă a acestui proiect de învățare automată aici – Wine Quality Prediction in R
MNIST Handwritten Digit Classification
Învățarea profundă și rețelele neuronale joacă un rol vital în recunoașterea imaginilor, generarea automată a textelor și chiar în mașinile care se conduc singure. Pentru a începe să lucrați în aceste domenii, trebuie să începeți cu un set de date simplu și ușor de gestionat, cum ar fi setul de date MNIST. Este dificil să lucrezi cu date de imagine peste date relaționale plate și, ca începător, îți sugerăm să poți lua și să rezolvi provocarea MNIST Handwritten Digit Classification Challenge. Setul de date MNIST este prea mic pentru a încăpea în memoria PC-ului dvs. și este ușor de utilizat pentru începători. Cu toate acestea, recunoașterea cifrelor scrise de mână vă va pune la încercare.
Faceți intrarea clasică în rezolvarea problemelor de recunoaștere a imaginilor accesând soluția completă aici – MNIST Handwritten Digit Classification Project
Învățați să construiți sisteme de recomandare cu setul de date Movielens
De la Netflix la Hulu, nevoia de a construi un sistem eficient de recomandare a filmelor a căpătat importanță de-a lungul timpului, odată cu cererea tot mai mare de conținut personalizat din partea consumatorilor moderni. Unul dintre cele mai populare seturi de date disponibile pe web pentru ca începătorii să învețe să construiască sisteme de recomandare este setul de date Movielens, care conține aproximativ 1.000.209 evaluări de filme din 3.900 de filme făcute de 6.040 de utilizatori Movielens. Puteți începe să lucrați cu acest set de date construind o vizualizare world-cloud a titlurilor de filme pentru a construi un sistem de recomandare a filmelor.
Acesul gratuit la exemple de coduri rezolvate poate fi găsit aici (acestea sunt gata de utilizare pentru proiectele dvs. ML)
Boston Housing Price Prediction ML Project
Boston House Prices Dataset constă în prețurile caselor în diferite locuri din Boston. Setul de date constă, de asemenea, în informații cu privire la zonele în care se desfășoară activități comerciale fără vânzare cu amănuntul (INDUS), rata criminalității (CRIM), vârsta persoanelor care dețin o casă (AGE) și alte câteva atribute (setul de date are un total de 14 atribute). Setul de date Boston Housing poate fi descărcat de la UCI Machine Learning Repository. Scopul acestui proiect de învățare automată este de a prezice prețul de vânzare al unei case noi prin aplicarea unor concepte de bază de învățare automată la datele privind prețurile locuințelor. Acest set de date este prea mic, cu 506 observații, și este considerat un bun început pentru începătorii în domeniul învățării automate pentru a-și începe practica practică asupra conceptelor de regresie.
Lectură recomandată – 15+ Proiecte de știință a datelor pentru începători
Social Media Sentiment Analysis using Twitter Dataset
Platformele de social media precum Twitter, Facebook, YouTube, Reddit generează cantități uriașe de date mari care pot fi exploatate în diverse moduri pentru a înțelege tendințele, sentimentele și opiniile publicului. Astăzi, datele din social media au devenit relevante pentru branding, marketing și afaceri în ansamblu. Un analizor de sentimente învață despre diferitele sentimente din spatele unei „bucăți de conținut” (poate fi un mesaj instantaneu, un e-mail, un tweet sau orice altă postare din social media) prin învățare automată și prezice același lucru folosind inteligența artificială.Datele Twitter sunt considerate ca fiind un punct de intrare definitiv pentru începători pentru a practica problemele de învățare automată a analizei sentimentelor. Utilizând setul de date Twitter, se poate obține un amestec captivant de conținuturi de tweet-uri și alte metadate conexe, cum ar fi hashtag-uri, retweet-uri, locație, utilizatori și multe altele care deschid calea pentru o analiză profundă. Setul de date Twitter este format din 31.962 de tweet-uri și are o dimensiune de 3 MB. Cu ajutorul datelor Twitter puteți afla ce spune lumea despre un subiect, fie că este vorba de filme, de sentimente legate de alegerile din SUA sau de orice alt subiect în trend, cum ar fi prezicerea câștigătorului Cupei Mondiale FIFA 2018. Lucrul cu setul de date Twitter vă va ajuta să înțelegeți provocările asociate cu extragerea datelor din social media și, de asemenea, să învățați în profunzime despre clasificatori. Cea mai importantă problemă la care puteți începe să lucrați ca începător este să construiți un model pentru a clasifica tweet-urile ca fiind pozitive sau negative.
Acces gratuit la codul rezolvat Exemplele Python și R pot fi găsite aici (acestea sunt gata de utilizare pentru proiectele dvs. de știință a datelor și ML)
Iris Flowers Classification ML Project- Learn about Supervised Machine Learning Algorithms
Acesta este unul dintre cele mai simple proiecte de învățare automată, Iris Flowers fiind cel mai simplu set de date de învățare automată din literatura de clasificare. Această problemă de învățare automată este adesea denumită „Hello World” a învățării automate. Setul de date are atribute numerice, iar începătorii în ML trebuie să își dea seama cum să încarce și să manipuleze datele. Setul de date iris este mic, care încape cu ușurință în memorie și nu necesită transformări speciale sau scalare, pentru început.
Iris Dataset poate fi descărcat de la UCI ML Repository – Download Iris Flowers Dataset
Obiectivul acestui proiect de învățare automată este de a clasifica florile între cele trei specii – virginica, setosa sau versicolor, pe baza lungimii și lățimii petalelor și sepalelor.
Acesul gratuit la exemple de coduri Python și R de învățare automată rezolvate poate fi găsit aici (acestea sunt gata de utilizare pentru proiectele dvs.)
Proiecte de învățare automată pentru începători cu cod sursă în Python pentru 2021
12) Proiect ML de optimizare a prețurilor de vânzare cu amănuntul – Model de învățare automată a prețurilor dinamice pentru o piață dinamică
Cursele de stabilire a prețurilor sunt în creștere non-stop în fiecare verticală industrială, iar optimizarea prețurilor este cheia pentru a gestiona eficient profiturile pentru orice afacere. Identificarea unui interval de preț rezonabil și efectuarea unei ajustări a prețurilor produselor pentru a crește vânzările, menținând în același timp marjele de profit optime, a fost întotdeauna o provocare majoră în industria de retail. Cea mai rapidă modalitate prin care comercianții cu amănuntul pot asigura cel mai mare randament al investiției în prezent, optimizând în același timp prețurile, este să valorifice puterea învățării automate pentru a crea soluții eficiente de stabilire a prețurilor. Gigantul comerțului electronic Amazon a fost unul dintre primii adoptatori ai învățării automate în optimizarea prețurilor de vânzare cu amănuntul, care a contribuit la creșterea sa stelară de la 30 de miliarde în 2008 la aproximativ 1 trilion în 2019.

Image Credit: spd. group
100+ Datasets for Machine Learning Projects Curated Specially For You
Soluția problemei de învățare automată a optimizării prețurilor de vânzare cu amănuntul necesită antrenarea unui model de învățare automată capabil să stabilească automat prețurile produselor în modul în care acestea ar fi stabilite de către oameni. Modelele de învățare automată de optimizare a prețurilor de vânzare cu amănuntul iau în considerare datele istorice privind vânzările, diverse caracteristici ale produselor și alte date nestructurate, cum ar fi imagini și informații textuale, pentru a învăța regulile de stabilire a prețurilor fără intervenție umană, ajutând comercianții cu amănuntul să se adapteze la un mediu dinamic de stabilire a prețurilor pentru a maximiza veniturile fără a pierde din marjele de profit. Algoritmul de învățare automată de optimizare a prețurilor de vânzare cu amănuntul procesează un număr infinit de scenarii de stabilire a prețurilor pentru a selecta prețul optim pentru un produs în timp real, luând în considerare mii de relații latente în cadrul unui produs.
Verificați acest proiect de învățare automată interesant privind optimizarea prețurilor de vânzare cu amănuntul pentru o scufundare profundă în analiza datelor de vânzări din viața reală pentru o cafenea în care veți construi o soluție de învățare automată de la un capăt la altul care sugerează automat prețurile corecte ale produselor.
13) Analiza de predicție a renunțării clienților folosind tehnici de ansamblu în învățarea automată
Clienții sunt cel mai mare activ al unei companii și păstrarea clienților este importantă pentru orice afacere pentru a crește veniturile și a construi o relație semnificativă de lungă durată cu clienții. În plus, costul de achiziție a unui nou client este de cinci ori mai mare decât cel de păstrare a unui client existent. Ratarea/abandonarea clienților este una dintre cele mai recunoscute probleme în afaceri, atunci când clienții sau abonații încetează să mai facă afaceri cu un serviciu sau o companie. În mod ideal, aceștia încetează să mai fie un client plătit. Se spune că un client este dezabonat dacă a trecut o anumită perioadă de timp de când clientul a interacționat ultima dată cu afacerea.
Identificarea dacă și când un client va fi dezabonat și furnizarea rapidă de informații acționabile care vizează păstrarea clienților este esențială pentru a reduce dezabonarea. Nu este posibil pentru creierele noastre să devanseze dezabonarea clienților pentru milioane de clienți, aici este locul unde învățarea automată poate ajuta. Învățarea automată oferă metode eficiente de identificare a factorilor care stau la baza dezabonaților și instrumente pro-criptive pentru a le aborda. Algoritmii de învățare automată joacă un rol vital în gestionarea proactivă a ratei de dezabonare, deoarece dezvăluie tiparele comportamentale ale clienților care au încetat deja să mai folosească serviciile sau să cumpere produse. Apoi, modelele de învățare automată verifică comportamentul clienților existenți în raport cu astfel de tipare pentru a identifica potențialii rebeli.

Credit imagine. :gallery.azure.ai
Dar cum să începem cu rezolvarea problemei de învățare automată a predicției ratei de dezabonare a clienților? Ca orice altă problemă de învățare automată, cercetătorii de date sau inginerii de învățare automată trebuie să colecteze și să pregătească datele pentru procesare. Pentru ca orice abordare de învățare automată să fie eficientă, ingineria datelor în formatul potrivit are sens. Ingineria caracteristicilor este partea cea mai creativă a modelului de învățare automată de predicție a ratei de dezabonare, în care specialiștii în date își folosesc experiența, contextul de afaceri, cunoștințele de domeniu ale datelor și creativitatea pentru a crea caracteristici și a adapta modelul de învățare automată pentru a înțelege de ce are loc dezabonarea clienților într-o anumită afacere.
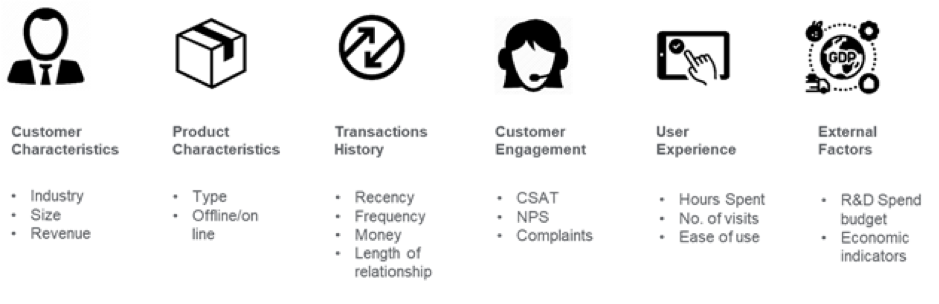
Creditul imaginii: medium.com
De exemplu, în industria bancară, două conturi care au același sold lunar de închidere pot fi dificil de diferențiat pentru predicția ratei de dezabonare. Dar, ingineria caracteristicilor poate adăuga o dimensiune temporală la aceste date, astfel încât algoritmii ML să poată diferenția dacă soldul lunar de închidere a deviat de la ceea ce se așteaptă de obicei de la un client. Indicatori precum conturile inactive, creșterea numărului de retrageri, tendințele de utilizare, ieșirea netă a soldului în ultimele câteva zile pot fi semne de avertizare timpurie a dezangajării. Aceste date interne, combinate cu date externe, cum ar fi ofertele concurenților, pot ajuta la previzionarea retragerii clienților. După identificarea caracteristicilor, următorul pas este să înțelegem de ce apar dezabonările într-un context de afaceri și să eliminăm caracteristicile care nu sunt predictori puternici pentru a reduce dimensionalitatea.
Vezi acest proiect de învățare automată de la un capăt la altul cu cod sursă în Python privind analiza predicției dezabonării clienților folosind învățarea de ansamblu pentru a combate dezabonarea.
Cum încep un proiect de învățare automată?
Niciun proiect nu avansează cu succes fără o planificare solidă, iar învățarea automată nu face excepție. Construirea primului proiect de machine learning nu este de fapt atât de dificilă pe cât pare, cu condiția să aveți o strategie de planificare solidă. Pentru a începe orice proiect de ML, trebuie să urmați o abordare cuprinzătoare de la un capăt la altul -începând de la stabilirea domeniului de aplicare a proiectului până la implementarea și gestionarea modelului în producție Iată punctul nostru de vedere cu privire la etapele fundamentale ale unui plan de proiect de învățare automată pentru a vă asigura că profitați la maximum de fiecare proiect unic –
1) Primul pas: Definirea domeniului de aplicare a proiectului de învățare automată
Înainte de orice altceva, înțelegeți care sunt cerințele de afaceri ale proiectului ML. Atunci când începeți un proiect ML, selectarea cazului de utilizare de afaceri relevant pentru care va fi construit modelul de învățare automată este pasul fundamental. Alegerea cazului de utilizare corectă a învățării automate și evaluarea rentabilității investiției sale este importantă pentru succesul oricărui proiect de învățare automată.
2) Al doilea pas: Date
Datele sunt sângele vital al oricărui model de învățare automată și este imposibil să se antreneze un model de învățare automată fără date. Etapa de date din ciclul de viață al unui proiect de învățare automată este un proces în patru etape –
-
Exigențe privind datele – Este important să înțelegeți ce fel de date vor fi necesare, formatul datelor, sursele de date și cerințele de conformitate ale surselor de date.
-
Colectarea datelor – Cu ajutorul administratorilor de baze de date, al arhitecților de date sau al dezvoltatorilor, trebuie să stabiliți strategia de colectare a datelor pentru a extrage datele din locurile în care acestea se află în cadrul organizației sau de la alți furnizori terți.
-
Analiză exploratorie a datelor – Această etapă implică, în esență, validarea cerințelor de date pentru a vă asigura că aveți datele corecte, că datele sunt în stare bună și că nu conțin erori.
-
Pregătirea datelor – Această etapă implică pregătirea datelor pentru a fi utilizate de algoritmii de învățare automată. Corectarea erorilor, ingineria caracteristicilor, codificarea în formate de date pe care mașinile le pot înțelege și corectarea anomaliilor sunt sarcinile implicate în pregătirea datelor.
3) Al treilea pas – Construirea modelului
În funcție de natura proiectului, acest pas poate dura câteva zile sau luni. În etapa de modelare, luați o decizie cu privire la algoritmul de învățare automată pe care să îl utilizați și începeți să antrenați modelul pe date. Înțelegerea măsurii de acuratețe, eroare și corectitudine la care ar trebui să adere un model de învățare automată este importantă pentru selectarea modelului. După ce ați antrenat modelul, îl evaluați pe datele de validare, astfel încât să îi analizați performanța și să preveniți supraadaptarea. Evaluarea modelului este un pas critic, deoarece dacă un model funcționează perfect cu datele istorice și returnează performanțe slabe cu datele viitoare, acesta nu este de nici un folos.
4) Al patrulea pas -Dezvoltarea modelului în producție
Acest pas implică desfășurarea software-ului sau a aplicației către utilizatorii finali, astfel încât noile date să poată intra în modelul de învățare automată pentru învățare ulterioară. Implementarea modelului de învățare automată nu este suficientă, trebuie, de asemenea, să vă asigurați că modelul de învățare automată funcționează conform așteptărilor. Ar trebui să reantrenați modelul pe noile date de producție live pentru a vă asigura acuratețea sau performanța acestuia – aceasta este reglarea modelului. Acordarea modelului necesită, de asemenea, validarea modelului pentru a vă asigura că nu este în derivă sau că nu devine părtinitor.
Cum puneți proiectele de învățare automată pe CV-ul dumneavoastră?
Experiența în lumea reală vă pregătește pentru succesul final ca nimic altceva. În calitate de începător în domeniul învățării automate, cu cât poți câștiga mai multă experiență în timp real lucrând la proiecte de învățare automată, cu atât vei fi mai pregătit să prinzi cele mai tari locuri de muncă ale deceniului. Obținerea unui loc de muncă în domeniul învățării automate după finalizarea formării în domeniul științei datelor sau obținerea succesului ca cercetător de date va depinde de capacitatea ta de a te vinde. După ce ați urmat o formare cuprinzătoare în domeniul științei datelor, următorul pas pentru a obține un loc de muncă de top ca inginer de învățare automată sau cercetător de date este să vă construiți un portofoliu remarcabil pentru a vă prezenta potențialilor angajatori capacitatea de a aplica tehnici de învățare automată. Lucrul la proiecte interesante de ML este o modalitate excelentă de a vă lansa cariera de inginer de învățare automată pentru întreprinderi sau de cercetător de date. Angajatorii doresc să vadă la ce fel de proiecte legate de știința datelor și de învățarea automată ați lucrat pentru a evalua gama de abilități pe care le aveți în a face știința datelor și învățarea automată. Evidențierea unor exemple de proiecte de știință a datelor și de învățare automatizată amuzante, cool și interesante în CV-ul dvs. va avea mai multă greutate decât să le spuneți cât de multe știți. Iată cum puteți adăuga proiecte grozave la CV-ul dvs. de învățare automată –
- Puteți menționa proiectele de învățare automată imediat după secțiunea de experiență profesională din CV-ul de învățare automată.
- Să urmați o ordine secvențială de numerotare împreună cu titlul proiectelor la care ați lucrat.
- Titlul proiectului ar trebui să fie urmat de un mic rezumat despre setul de date și enunțul problemei.
- Menționați instrumentele și tehnologiile de învățare automată pe care le-ați folosit pentru a finaliza un proiect.
- În final, dar nu în ultimul rând, în portofoliul / CV-ul dvs. legați fiecare proiect de învățare automată de GitHub, site-ul personal sau blogul pentru o înțelegere în profunzime a realizărilor dvs.
Dacă doriți să construiți un portofoliu puternic de învățare automată sau doriți să puneți în practică abilitățile analitice pe care le-ați învățat în cursul de formare în domeniul științei datelor, noi v-am acoperit. Mulți începători în domeniul învățării automate nu sunt siguri de unde să înceapă, ce proiecte de învățare automată să facă, ce instrumente, tehnici și cadre de învățare automată să utilizeze. Am făcut să fie o sarcină fără bătăi de cap pentru începătorii în domeniul științei datelor și al învățării automate prin curatoria unei liste de idei interesante pentru proiecte de învățare automată, împreună cu soluțiile lor. Aceste idei de proiecte de învățare automată sunt preluate din provocările populare de știință a datelor Kaggle și reprezintă o modalitate excelentă de a învăța învățarea automată. Această listă de proiecte este o modalitate perfectă de a pune proiectele de învățare a mașinilor în CV-ul dumneavoastră. Mentalitatea potrivită, dorința de a învăța și multă explorare a datelor sunt toate necesare pentru a înțelege soluția proiectelor privind știința datelor și învățarea automată. Puteți explora 50+ proiecte de știință a datelor și ML bazate pe setul de abilități, instrumente și tehnici pe care trebuie să le învățați.
Înainte de a începe proiectul, este util să aveți acces la o bibliotecă de exemple de coduri de proiecte de învățare automată. Astfel, ori de câte ori vă blocați în proiect, puteți folosi aceste exemple rezolvate pentru a vă descurca.
Accesați exemple de coduri de proiecte de știință a datelor și învățare automată
Ce urmează?
Omul poate deveni un maestru al învățării automate numai cu multă practică și experimentare. A avea cunoștințe teoretice ajută cu siguranță, dar aplicația este cea care ajută cel mai mult la progres. Nicio cantitate de cunoștințe teoretice nu poate înlocui practica practică. Cu toate acestea, vă va ajuta dacă vă familiarizați mai întâi cu proiectele inovatoare de învățare automată enumerate mai sus.
Dacă sunteți un începător și sunteți nou în domeniul învățării automate, atunci lucrul la proiectele de învățare automată concepute de experții din industrie de la ProjectPro va fi una dintre cele mai bune investiții ale timpului dumneavoastră. Aceste proiecte au fost concepute pentru începători pentru a-i ajuta să își îmbunătățească rapid abilitățile de învățare automată aplicată, oferindu-le în același timp șansa de a explora cazuri interesante de utilizare în afaceri din diverse domenii – retail, finanțe, asigurări, producție și multe altele. Așadar, dacă doriți să vă bucurați de învățarea învățării automate, să rămâneți motivați și să faceți progrese rapide, atunci proiectele interesante de ML de la ProjectPro sunt pentru dumneavoastră. În plus, adăugați aceste proiecte de învățare automată la portofoliul dvs. și obțineți un job de top cu un salariu mai mare și avantaje recompensatoare.

Click aici pentru a vedea o listă de peste 50 de soluții de proiecte rezolvate, end-to-end, în Machine Learning și Big Data
|
PRECEDENT |
NEXT |
.