
De: Aaron Bertrand | Actualizat: 2019-12-03 | Comentarii (1) | Related: Mai multe > Tuning de performanță
Problemă
Cu câțiva ani în urmă, am scris pe blog despre modul în care puteți reduce impactul asupra jurnalului de tranzacții prin împărțirea operațiunilor de ștergere în bucăți. În loc să ștergeți 100.000 de rânduri într-o singură tranzacție mare, puteți șterge 100 sau 1.000 sau un număr arbitrar de rânduri la un moment dat, în mai multe tranzacții mai mici, într-o buclă. În plus față de reducerea impactului asupra jurnalului, ați putea ușura blocajele de lungă durată. La acea vreme, SSD-urile abia începeau să se dezvolte, iar tehnologiile mai noi precumClustered Columnstore Indexes, Delayed Durability și Accelerated Database Recovery nu existau încă. Așadar, m-am gândit că ar fi timpul pentru o reîmprospătare pentru a oferi o imagine mai bună a modului în care acest lucru se prezintă în SQL Server2019.
Soluție
Eliminarea unor porțiuni mari dintr-un tabel nu este întotdeauna singurul răspuns. Dacă ștergeți 95% dintr-un tabel și păstrați 5%, poate fi de fapt mai rapid să mutați rândurile pe care doriți să le păstrați într-un tabel nou, să renunțați la vechiul tabel și să redenumiți noul tabel.sau să copiați rândurile păstrate, să trunchiați tabelul și apoi să le copiați din nou în tabel. Dar chiar și atunci când epurarea este mult mai mare decât păstrarea, acest lucru nu este întotdeauna posibil din cauza altor constrângeri asupra tabelului, a SLA-urilor și a altor factori.
Din nou, dacă se dovedește că trebuie să ștergeți rânduri, veți dori să minimizați impactul asupra jurnalului de tranzacții și modul în care operațiunile afectează restul volumului de lucru.Abordarea chunking nu este o idee nouă sau inedită, dar poate funcționa bine cu unele dintre aceste tehnologii mai noi, așa că haideți să le punem la încercare într-o varietate de combinații.
Pentru a configura, avem mai multe constante care vor fi adevărate pentru fiecare test:
- SQL Server 2019 RC1, cu patru nuclee și 32 GB RAM (memoria maximă a serverului =28 GB)
- Tabelă de 10 milioane de rânduri
- Reporniți SQL Server după fiecare test (pentru a reseta memoria, tampoanele, și plancache)
- Refaceți o copie de rezervă care avea statisticile deja actualizate și auto-statisticile dezactivate (pentru a preveni ca orice actualizare de statistici declanșată să interfereze cu operațiunile de ștergere)
De asemenea, avem multe variabile care se vor schimba la fiecare test:
Aceasta va produce 864 de teste unice și ar fi bine să credeți că am de gând să automatizez toate aceste permutări.
Și metricile pe care le vom măsura:
- Durată totală
- Utilizarea CPU medie/cu vârf
- Utilizarea medie/cu vârf a memoriei
- Utilizarea jurnalului de tranzacții/creșterea fișierelor
- Utilizarea fișierelor bazei de date, dimensiunea stocului de versiuni (atunci când se utilizează Accelerated DatabaseRecovery)
- Dimensiunea grupului de rânduri delta (atunci când se utilizează Columnstore)
Source Table
Primul rând, am restaurat o copie a AdventureWorks (AdventureWorks2017.bak,pentru a fi mai precis). Pentru a crea un tabel cu 10 milioane de rânduri, am făcut o copie a Sales.SalesOrderDetail,cu propria coloană de identitate, și am adăugat o coloană de umplutură doar pentru a da fiecărui rând un pic mai multă carne și pentru a reduce densitatea paginii:
CREATE TABLE dbo.SalesOrderDetailCopy
(
SalesOrderDetailID int IDENTITY,
SalesOrderID int,
CarrierTrackingNumber nvarchar(25),
OrderQty smallint,
ProductID int,
SpecialOfferID int,
UnitPrice money,
UnitPriceDiscount money,
LineTotal numeric(38,6),
rowguid uniqueidentifier,
ModifiedDate datetime,
filler char(50) NOT NULL DEFAULT ''
);
GO
Apoi, pentru a genera cele 10.000.000 de rânduri, am inserat 100.000 de rânduri la un moment dat și am rulat inserarea de 100 de ori:
INSERT dbo.SalesOrderDetailCopy
(
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
)
SELECT TOP(100000)
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
FROM Sales.SalesOrderDetail;GO 100
Nu am creat nici un index pe tabelă; în funcție de abordarea de stocare, voi crea un nou index clusterizat (coloana de stocare jumătate din timp) după ce baza de date este restaurată ca parte a fiecărui test.
Automatizarea testelor
După ce a existat tabelul de 10 milioane de rânduri, am setat câteva opțiuni, am făcut o copie de rezervă a bazei de date,am făcut o copie de rezervă a jurnalului de două ori și apoi am făcut din nou o copie de rezervă a bazei de date (astfel încât jurnalul să aibă cel mai puțin spațiu utilizat posibil la restaurare):
În continuare, am creat o bază de date de control, în care voi stoca procedurile stocate care vor rula testele și tabelele care vor conține rezultatele testelor (doar ora de început și de sfârșit a fiecărui test) și indicatorii de performanță capturați pe parcursul tuturor testelor.
Capturarea permutărilor tuturor celor 864 de teste pe care doream să le efectuez a necesitat câteva încercări, dar am ajuns la următorul rezultat:
Așa cum era de așteptat, aceasta a inserat 864 de rânduri cu toate aceste combinații.
Apoi, am creat o procedură stocată pentru a captura setul de măsurători descris mai devreme.De asemenea, monitorizez instanța cuSentryOne SQL Sentry, așa că vor exista cu siguranță și alte informații interesantedisponibile acolo, dar am vrut, de asemenea, să capturez detaliile importante fără a utiliza instrumente terțe. Iată procedura, care se străduiește să producă toate metricile pentru orice dată de timp într-un singur rând:
Am pus această procedură stocată într-o etapă de lucru și am pornit-o. S-ar putea să doriți să folosiți o altă întârziere decât trei secunde – există un compromis între costul colectării și caracterul complet al datelor care ar putea înclina mai mult într-o parte decât în cealaltă pentru dumneavoastră.
În cele din urmă, am creat procedura care ar conține toată logica pentru a determinaexact ce să facă cu combinația de parametri pentru fiecare test individual.Acest lucru a necesitat, din nou, mai multe iterații, dar produsul final este următorul:
Se întâmplă multe lucruri acolo, dar logica de bază este următoarea:
- Scoate datele specifice testului (TestID și toți parametrii) din dbo.Teststable
- Dă-i un șut lui SQL Server făcând o modificare sp_configure și ștergând tampoaneleși memoria cache a planului
- Restaurează o copie curată a AdventureWorks, cu toate cele 10 milioane de rânduri intacte,și fără indici
- Modificați opțiunile bazei de date în funcție de parametrii pentru testul curent
- Crearea fie a unui indice de tip columnstore clusterizat, fie a unui indice de tip B-tree clusterizat
- Actualizați manual statisticile tabelei, doar pentru a fi siguri
- Demarcați că am început testul
- Determinați de câte iterații ale buclei avem nevoie și câte rânduri să ștergem în interiorul fiecărei iterații
- În interiorul buclei:
- Determinați dacă trebuie să pornim o tranzacție în această iterație
- Executați ștergerea
- Determinați dacă trebuie să validăm tranzacția în această iterație
- Determinați dacă trebuie să efectuăm un punct de control/un back-up al jurnalului în această iterație
- După buclă, înregistrăm în jurnal că acest test s-a încheiat și confirmăm orice tranzacție neangajată
Pentru a rula efectiv testul, nu vreau să fac acest lucru în Management Studio (chiar și pe aceeași mașină virtuală), din cauza întregii ieșiri, a traficului suplimentar și a utilizării resurselor.Am creat o procedură stocată și am pus și acest lucru într-un job:
Aceasta a durat mult mai mult decât îmi convine să recunosc. O parte din asta s-a datorat faptului că inițial am inclus un test de 0,1% pentru rowperloopcare, care, în unele cazuri, a durat câteva ore. Așa că le-am eliminat pe acelea din tabel după câteva zile și pot spune cu ușurință: dacă eliminați 1.000.000 de rânduri, este foarte puțin probabil ca ștergerea a 1.000 de rânduri la un moment dat să fie o alegere optimă, indiferent de orice alte variabile:

(Deși pare a fi o anomalie în comparație cu majoritatea celorlalte teste, pariez că nu ar fi mult mai rapid decât ștergerea unui rând sau a 10 rânduri la un moment dat. Și, de fapt, a fost mai lent decât ștergerea a jumătate de tabel sau a majorității tabelului în toate celelalte scenarii.)
Rezultatele performanței
După ce am eliminat rezultatele de la testele de 0,1%, am pus restul într-un al doilea tabel de metrice cu duratele încărcate:
A trebuit să folosesc o îmbinare exterioară în tabelul de metrice pentru că unele teste s-au desfășurat atât de repede încât nu a fost suficient timp pentru a capta date. Acest lucru înseamnă că, pentru unele dintre testele mai rapide, nu va exista nicio corelație cu alte detalii de performanță în afară de cât de repede au rulat.
Apoi am început să caut tendințe și anomalii. În primul rând, am verificat duratași CPU în funcție de activarea sau nu a Durabilității întârziate (DD) și/sau a Recuperării accelerate a bazei de date (ADR):
Rezultate (cu anomalii evidențiate):

Se pare că durata totală este îmbunătățită, în medie, cam în aceeași măsură, atunci când oricare dintre opțiuni este activată (sau ambele – și când ambele sunt activate, vârful este mai mic). Se pare că există o valoare aberantă a duratei doar pentru ADR, care nu a afectat media (acest test specific a implicat ștergerea a 9 000 000 de rânduri, 90 000 de rânduri la un moment dat, în recuperare completă, pe o tabelă de stocare a rândurilor). Valoarea aberantă a CPU pentru DD, de asemenea, nu a afectat media – acest exemplu specific a constat în ștergerea a 1.000.000 de rânduri, dintr-o dată, pe un tabel columnstore.
Cum rămâne cu diferențele generale între rowstore și columnstore?
Rezultate:

Columnstore este cu 20% mai lent, în medie, dar a necesitat mai puțină memorie. Am vrut, de asemenea, să văd impactul asupra dimensiunii și utilizării fișierelor de date și a fișierelor de jurnal:
Rezultate:

În cele din urmă, pe hardware-ul de astăzi, ștergerea în bucăți nu pare să aibă aceleași beneficii pe care le avea odată, cel puțin în ceea ce privește durata. Cele 18 rezultate cele mai rapide de aici, și 72 dintre cele mai rapide 100, au fost teste în care toate rândurile au fost șterse dintr-o singură lovitură, așa cum reiese din această interogare:
Rezultate:
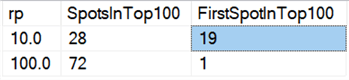
Și dacă ne uităm la mediile pentru toate datele, ca în această interogare:
Vezi că ștergerea tuturor rândurilor dintr-o dată, indiferent dacă ștergem 10%, 50% sau 90%, este mai rapidă decât ștergerile grupate în orice mod (din nou, în medie):
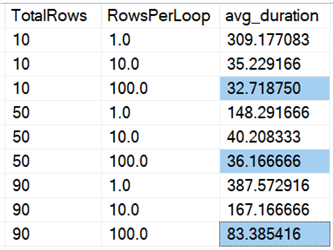
În formă de grafic:
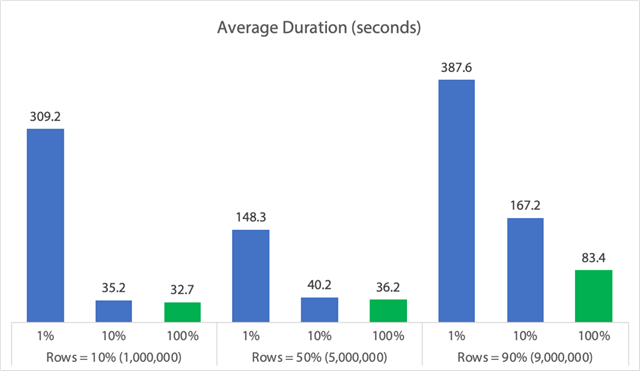
(Rețineți că dacă eliminăm valoarea maximă de 6.062 de secunde max_durationoutlier identificată mai devreme, această primă coloană scade de la 309 secunde la 162 de secunde.)
Acum, chiar și în cel mai bun caz, asta înseamnă încă 33, 36 sau 83 de secunde în care adelete rulează și poate bloca pe oricine altcineva, iar acest lucru ignoră alte impacturi măsurate, cum ar fi memoria, fișierul jurnal, CPU și așa mai departe. Durata cu siguranță nu ar trebui să fie singurul criteriu; se întâmplă doar că, de obicei, este primul (și uneori singurul) lucru la care se uită oamenii. Acest harnașament de testare a fost menit să arate că puteți și ar trebui să captați și alți câțiva parametri, iar rezultatele arată că valorile aberante pot proveni de oriunde.
Utilizând acest harnașament ca model, vă puteți construi propriile teste axate mai mult pe constrângerile și capacitățile din mediul dumneavoastră. Nu am atacat măsurătorile din toate unghiurile posibile, deoarece sunt o mulțime de permutări,dar voi păstra această bază de date. Așadar, dacă există și alte moduri în care doriți să vedeți datele feliate, anunțați-mă în comentariile de mai jos și voi vedea ce pot face. Doar nu-mi cereți să fac din nou toate testele.
Caveats
Toate acestea nu iau în considerare o sarcină de lucru concurentă, impactul constrângerilor tabelelorcum ar fi cheile străine, prezența declanșatorilor și o multitudine de alte scenarii posibile.Un alt lucru de testat (potențial într-un sfat viitor) este de a avea mai multe lucrări careinteracționează cu aceeași tabelă pe parcursul operațiunii și de a măsura lucruri precum duratele de blocare, tipurile și timpii de așteptare și de a măsura în ce situații un set de activități are un impact mai dramatic asupra celuilalt set.
Pași următori
Continuați să citiți pentru sfaturi conexe și alte resurse:
- Operații CRUD în SQL Server
- Diferențe între Delete și Truncate în SQL Server
- Eliminarea datelor istorice dintr-o tabelă de baze de date SQL Server de mari dimensiuni și foarte concurentă
- Părțiți operațiunile mari de ștergere în bucăți
- SQL Server Clustered and Nonclustered Columnstore Index Example
- Delayed Durability in SQL Server 2014
- Delayed Durability while Purging Data
- Accelerated Database Recovery in SQL Server 2019
.
Ultima actualizare: 2019-12-03


Despre autor
 Aaron Bertrand (@AaronBertrand) este un tehnolog pasionat cu o experiență în industrie care datează de la Classic ASP și SQL Server 6.5. El este redactor-șef al blogului legat de performanță, SQLPerformance.com, și are, de asemenea, bloguri la sqlblog.org.
Aaron Bertrand (@AaronBertrand) este un tehnolog pasionat cu o experiență în industrie care datează de la Classic ASP și SQL Server 6.5. El este redactor-șef al blogului legat de performanță, SQLPerformance.com, și are, de asemenea, bloguri la sqlblog.org.Vezi toate sfaturile mele
- Mai multe sfaturi SQL Server DBA…
.