
Un șablon este definit în 1978 în Webster’s New Collegiate Dictionary ca fiind o moleculă (cum ar fi ARN) într-un sistem biologic care poartă codul genetic pentru o altă moleculă. De asemenea, Concise Oxford Dictionary, ediția a noua, din 1995, descrie un șablon ca fiind modelul molecular care guvernează asamblarea unei proteine etc. Conform acestor definiții generale, ADN-ul este șablonul pentru ADN (în replicarea ADN-ului) și pentru ARN (în transcriere ), iar ARN-ul este șablonul pentru proteine (în traducere ). Cu alte cuvinte, un șablon este o entitate moleculară esențială pentru transferul informației genetice de la ADN la ADN la ARN la proteină (dogma centrală). Mai precis, cuvântul „șablon” este utilizat atunci când o moleculă care transferă informații (șablonul) este în contact direct cu molecula primitoare (produsul). Prin urmare, în acest sens, ARN-ul nu este un șablon pentru proteină, deoarece nu are loc nicio interacțiune directă între ARN-ul mesager și proteină în timpul traducerii (a se vedea Biosinteza proteinelor). În cazurile care fac excepție de la dogma centrală, ARN-ul viral este sintetizat din ARN folosind ARN-ul ca șablon (a se vedea Virusuri cu ARN) și, mai mult, ADN-ul este sintetizat folosind ARN-ul ca șablon în timpul infecției retrovirușilor (a se vedea și Transcripția inversă).
În replicarea ADN, dublul helix este derulat, iar fiecare moleculă de ADN monocatenar este utilizată ca șablon pentru a sintetiza un catenar complementar. Deoarece ADN-ul suferă o replicare semiconservativă, ADN-ul parental servește drept șablon și devine o componentă a moleculei de ADN fiică. În transcripție, în schimb, un șir de ADN servește drept șablon pentru sinteza ARN-ului care apoi se disociază de șablon (a se vedea Transcripție). ADN polimerazele care asamblează dezoxiribonucleotide pe șuvița de ADN șablon conform regulii de complementaritate a bazelor Adenină (A):Timină (T), Guanină(G):Citosină (C) (împerechere de baze Watson-Crick) au nevoie atât de un șablon, cât și de o amorsă pentru ca reacția să aibă loc (Fig. 1). În consecință, sinteza ADN-ului este precedată de sinteza unor molecule mici de ARN de mai puțin de 10 pb de către ARN primază, care poate iniția sinteza ARN-ului complementar ADN-ului șablon (a se vedea fragmente Okazaki). ARN amorsă este în cele din urmă înlocuit de ADN prin intermediul șirului de ADN întârziat extins din regiunea care precede sinteza de ARN amorsă [a se vedea Furculița de replicare (intermediar Y-Fork)]. Relația șablon-produs prin complementaritatea bazelor A cu T și G cu C nu este 100% exactă, dar duce la formarea de perechi greșite o dată la 10 3 până la 104 ori. Pe de altă parte, perechile greșite apar, în general, doar o dată la 10 la 10 atunci când genomurile sunt replicate în interiorul celulei . Acest lucru se realizează prin activitatea de corecție a ADN polimerazelor în sine și prin alte mecanisme de reparare a ADN-ului.
Figura 1. ADN polimeraza are nevoie de șablon și amorsă. La o furcă de replicare în creștere, șirurile simple de ADN furnizate de ADN elicaza ADN servesc drept temple pentru ADN polimerazele ADN. Enzimele sintetizează legături fosfodiesterice între capătul 3′( al amorsă, șir nou sintetizat, și dezoxiribonucleotid-trifosfat care este corect împerecheat în baze cu șirul șablon. Aici este prezentată schematic doar sinteza șirului conducător.
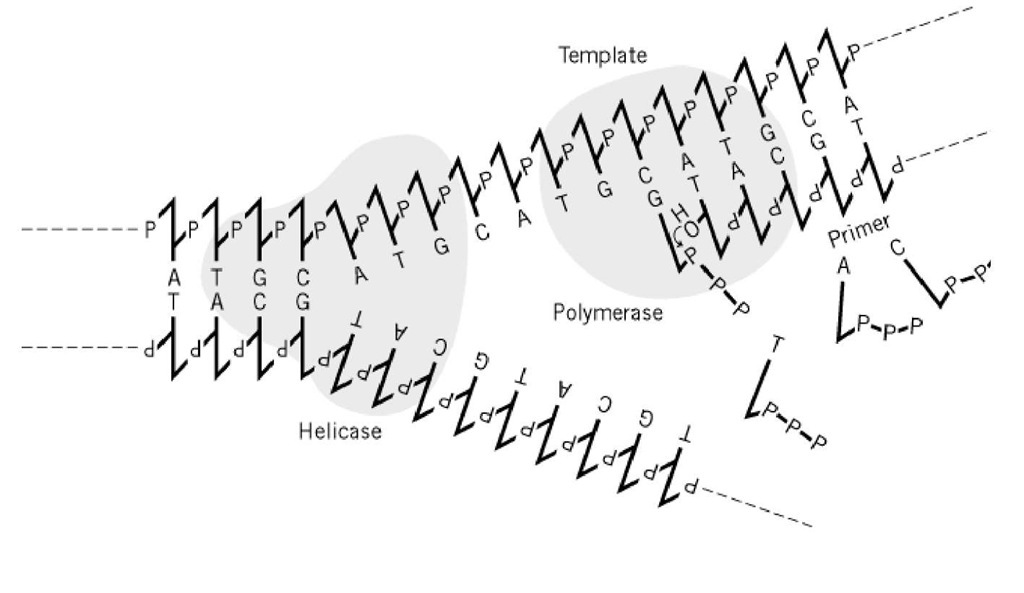
Relația șablon-produs este foarte importantă în transferul de informație genetică în sistemele biologice. Cu toate acestea, natura fizico-chimică a relației în sine nu este suficient de precisă pentru a realiza procesele biologice reglementate cu precizie, iar multe proteine au evoluat pentru a repara erorile care rezultă în mod inevitabil.
.