
Por: Aaron Bertrand | Actualizado: 2019-12-03 | Comentarios (1) | Relacionado: Más >Ajuste del rendimiento
Problema
Hace varios años, escribí en el blog sobre cómo se puede reducir el impacto en el transactionlog rompiendo las operaciones de eliminación en trozos. En lugar de eliminar 100.000 filas en una gran transacción, puedes eliminar 100 o 1.000 o algún número arbitrario de filas a la vez, en varias transacciones más pequeñas, en un bucle. Además de reducir el impacto en el registro, se podría aliviar el bloqueo de larga duración. En aquel momento, las unidades SSD estaban ganando terreno y aún no existían nuevas tecnologías, como los índices agrupados de almacenes de columnas, la durabilidad retardada y la recuperación acelerada de bases de datos. Por lo tanto, pensé que podría ser el momento para una actualización para dar una mejor imagen de cómo esto se desarrolla en SQL Server2019.
Solución
La eliminación de grandes porciones de una tabla no es siempre la única respuesta. Si usted está eliminando el 95% de una tabla y manteniendo el 5%, en realidad puede ser más rápido mover las filas que desea mantener en una nueva tabla, eliminar la tabla antigua, y cambiar el nombre de la nueva.O copiar las filas que se mantienen fuera, truncar la tabla, y luego copiarlas de nuevo. Pero incluso cuando la purga es mucho mayor que la conservación, esto no siempre es posible debido a otras restricciones en la tabla, los SLA y otros factores.
Además, si resulta que tiene que eliminar filas, querrá minimizar el impacto en el registro de transacciones y cómo las operaciones afectan al resto de la carga de trabajo.El enfoque de chunking no es una idea nueva o novedosa, pero puede funcionar bien con algunas de estas nuevas tecnologías, así que vamos a ponerlas a prueba en una variedad de combinaciones.
Para la configuración, tenemos múltiples constantes que serán verdaderas para cada prueba:
- SQL Server 2019 RC1, con cuatro núcleos y 32 GB de RAM (memoria máxima del servidor =28 GB)
- Tabla de 10 millones de filas
- Reiniciar SQL Server después de cada prueba (para resetear memoria, buffers, y plancache)
- Restaurar una copia de seguridad que tenía las estadísticas ya actualizadas y las estadísticas automáticas deshabilitadas(para evitar que cualquier actualización de las estadísticas desencadenada interfiera con las operaciones de eliminación)
También tenemos muchas variables que cambiarán por prueba:
Esto producirá 864 pruebas únicas, y es mejor que creas que voy a automatizar todas estas permutaciones.
Y las métricas que mediremos:
- Duración total
- Uso medio/pico de la CPU
- Uso medio/pico de la memoria
- Uso del registro de transacciones/crecimiento del archivo
- Uso del archivo de la base de datos, tamaño del almacén de versiones (cuando se utiliza Accelerated DatabaseRecovery)
- Tamaño del grupo de filas delta (cuando se utiliza Columnstore)
Tabla de origen
En primer lugar, restauré una copia de AdventureWorks (AdventureWorks2017.bak, concretamente). Para crear una tabla con 10 millones de filas, hice una copia de Sales.SalesOrderDetail, con su propia columna de identidad, y añadí una columna de relleno sólo para dar a cada fila un poco más de carne y reducir la densidad de la página:
CREATE TABLE dbo.SalesOrderDetailCopy
(
SalesOrderDetailID int IDENTITY,
SalesOrderID int,
CarrierTrackingNumber nvarchar(25),
OrderQty smallint,
ProductID int,
SpecialOfferID int,
UnitPrice money,
UnitPriceDiscount money,
LineTotal numeric(38,6),
rowguid uniqueidentifier,
ModifiedDate datetime,
filler char(50) NOT NULL DEFAULT ''
);
GO
Entonces, para generar los 10.000.000 de filas, inserté 100.000 filas a la vez, y ejecuté la inserción 100 veces:
INSERT dbo.SalesOrderDetailCopy
(
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
)
SELECT TOP(100000)
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
FROM Sales.SalesOrderDetail;GO 100
No creé ningún índice en la tabla; dependiendo del enfoque de almacenamiento, crearé un nuevo índice agrupado (columnstore la mitad de las veces) después de restaurar la base de datos como parte de cada prueba.
Automatización de las pruebas
Una vez que la tabla de 10 millones de filas existía, configuré algunas opciones, hice una copia de seguridad de la base de datos, hice una copia de seguridad del registro dos veces, y luego volví a hacer una copia de seguridad de la base de datos (para que el registro tuviera el menor espacio usado posible cuando se restaurara):
Luego, creé una base de datos de Control, donde almacenaría los procedimientos almacenados que ejecutarían las pruebas, y las tablas que contendrían los resultados de las pruebas (sólo la hora de inicio y fin de cada prueba) y las métricas de rendimiento capturadas a lo largo de todas las pruebas.
Capturar las permutaciones de las 864 pruebas que quería realizar me llevó unos cuantos intentos, pero acabé con esto:
Como era de esperar, esto insertó 864 filas con todas esas combinaciones.
A continuación, creé un procedimiento almacenado para capturar el conjunto de métricas descritas anteriormente.También estoy monitoreando la instancia conSentryOne SQL Sentry, por lo que seguramente habrá otra información interesante disponible allí, pero también quería capturar los detalles importantes sin el uso de ninguna herramienta de terceros. Aquí está el procedimiento, que sale de su manera toproduce todas las métricas para cualquier timestamp dado en una sola fila:
Puse ese procedimiento almacenado en un paso de trabajo y lo inició. Es posible que desee utilizar un retraso de más de tres segundos – hay un equilibrio entre el coste de la recopilación y la integridad de los datos que puede inclinarse más hacia un lado que hacia el otro para usted.
Por último, creé el procedimiento que contendría toda la lógica para determinar exactamente qué hacer con la combinación de parámetros para cada prueba individual.Esto también llevó varias iteraciones, pero el producto final es el siguiente:
Hay mucho que hacer, pero la lógica básica es la siguiente:
- Sacar los datos específicos de la prueba (TestID y todos los parámetros) de la dbo.Teststable
- Dar una patada a SQL Server haciendo un cambio sp_configure y limpiando los buffersy la caché del plan
- Restaurar una copia limpia de AdventureWorks, con los 10 millones de filas intactas,y sin índices
- Cambiar las opciones de la base de datos en función de los parámetros de la prueba actual
- Crear un índice columnstore agrupado o un índice B-tree agrupado
- Actualizar las estadísticas de la tabla manualmente, sólo para estar seguros
- Registrar que hemos iniciado la prueba
- Determinar cuántas iteraciones del bucle necesitamos, y cuántas filas borrar dentro de cada iteración
- Dentro del bucle:
- Determinamos si necesitamos iniciar una transacción en esta iteración
- Realizamos el borrado
- Determinamos si necesitamos consignar la transacción en esta iteración
- Determinamos si necesitamos hacer un checkpoint/respaldo del log en esta iteración
- Después del bucle, registramos que esta prueba está terminada, y confirmamos cualquier transacción no comprometida
Para ejecutar realmente la prueba, no quiero hacer esto en Management Studio (incluso en la misma VM), debido a toda la salida, el tráfico adicional, y el uso de recursos.He creado un procedimiento almacenado y poner esto en un trabajo también:
Eso tomó mucho más tiempo de lo que estoy cómodo admitir. Parte de eso fue porque originalmente había incluido una prueba de 0,1% para rowperloopque, en algunos casos, tomó varias horas. Así que eliminé eso de la tabla a los pocos días, y puedo decir fácilmente: si estás eliminando 1.000.000 de filas, eliminar 1.000 filas a la vez es muy poco probable que sea una opción óptima, independientemente de cualquier otra variable:

(Aunque eso parece ser una anomalía en comparación con la mayoría de las otras pruebas, apuesto a que no sería mucho más rápido que eliminar una fila o 10 filas a la vez. Y, de hecho, fue más lento que borrar la mitad de la tabla o la mayor parte de la tabla en todos los demás escenarios.)
Resultados de rendimiento
Después de descartar los resultados de las pruebas del 0,1%, puse el resto en una segunda tabla de métricas con las duraciones cargadas:
Tuve que usar un outer join en la tabla de métricas porque algunas pruebas se ejecutaron tan rápidoque no hubo tiempo suficiente para capturar ningún dato. Esto significa que, para algunas de las pruebas más rápidas, no habrá ninguna correlación con otros detalles de rendimiento aparte de la rapidez con la que se ejecutaron.
Entonces empecé a buscar tendencias y anomalías. En primer lugar, comprobé la duración y la CPU en función de si la Durabilidad Retardada (DD) y/o la Recuperación Acelerada de la Base de Datos (ADR) estaban activadas:
Resultados (con las anomalías resaltadas):

Parece que la duración general mejora, de media, en la misma medida, cuando se activa cualquiera de las dos opciones (o ambas – y cuando ambas están activadas, el pico es menor). Parece que hay un valor atípico de duración para ADR solo que no afectó a la media (esta prueba específica implicó la eliminación de 9.000.000 filas, 90.000 filas a la vez, en la recuperación completa, en una tabla rowstore). El valor atípico de la CPU para DD tampoco afectó a la media: este ejemplo concreto consistió en borrar 1.000.000 de filas, todas a la vez, en una tabla columnstore.
¿Qué hay de las diferencias generales al comparar rowstore y columnstore?
Resultados:

Columnstore es un 20% más lento, de media, pero requiere menos memoria. También quería ver el impacto en el tamaño y uso de los archivos de datos y de registro:
Resultados:

Por último, en el hardware actual, el borrado en trozos no parece tener las mismas ventajas que antes, al menos en términos de duración. Los 18 resultados más rápidos aquí, y 72 de los 100 más rápidos, fueron pruebas en las que todas las filas se borraron de una sola vez, lo que revela esta consulta:
Resultados:
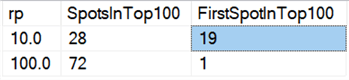
Y si miramos los promedios de todos los datos, como en esta consulta:
Vemos que borrar todas las filas de una vez, independientemente de si borramos el 10%, el 50% o el 90%, es más rápido que borrar en trozos de cualquier manera (de nuevo, en promedio):
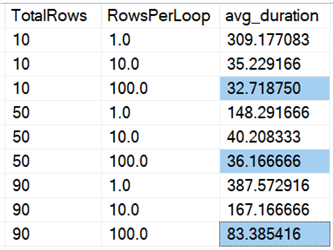
En forma de gráfico:
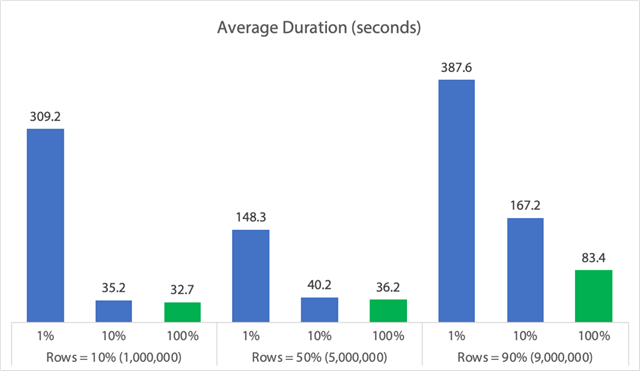
(Obsérvese que si quitamos el max_durationoutlier de 6.062 segundos identificado antes, esa primera columna baja de 309 a 162 segundos.)
Ahora bien, incluso en el mejor de los casos, eso sigue siendo 33, 36 u 83 segundos en los que adelete se está ejecutando y bloqueando potencialmente a todos los demás, y esto está ignorando otros impactos medidos como la memoria, el archivo de registro, la CPU, etc. La duración no debería ser el único criterio; lo que ocurre es que suele ser lo primero (y a veces lo único) en lo que se fija la gente. Este arnés de pruebas pretendía mostrar que también se pueden y se deben capturar otras métricas, y los resultados muestran que los valores atípicos pueden venir de cualquier parte.
Usando este arnés como modelo, puedes construir tus propias pruebas centradas más estrechamente en las limitaciones y capacidades de tu entorno. No he atacado las métricas desde todos los ángulos posibles, ya que son muchas permutaciones, pero voy a mantener esta base de datos. Así que, si hay otras formas en las que quieres ver los datos divididos, házmelo saber en los comentarios de abajo, y veré lo que puedo hacer. Pero no me pidas que vuelva a hacer todas las pruebas.
Caveats
Todo esto no tiene en cuenta una carga de trabajo concurrente, el impacto de las restricciones de la tabla como las claves foráneas, la presencia de desencadenantes, y un montón de otros escenarios posibles.Otra cosa para probar (potencialmente en un consejo futuro) es tener múltiples trabajos que interactúan con esta misma tabla a lo largo de la operación, y medir cosas como duraciones de bloqueo, tipos y tiempos de espera, y medir en qué situaciones un conjunto de actividad tiene un impacto más dramático en el otro conjunto.
Siguientes pasos
Siga leyendo para obtener consejos relacionados y otros recursos:
- Operaciones CRUD en SQL Server
- Diferencias entre Delete y Truncate en SQL Server
- Eliminación de datos históricos de una gran tabla de base de datos de SQL Server altamente concurrente
- Dividir las operaciones de eliminación grandes en trozos
- Ejemplo de índice Columnstore de SQL Server agrupado y no agrupado
- Duración retardada en SQL Server 2014
- Duración retardada al purgar datos
- Recuperación acelerada de bases de datos en SQL Server 2019
Última actualización: 2019-12-03


Acerca del autor
 Aaron Bertrand (@AaronBertrand) es un tecnólogo apasionado con experiencia en la industria que se remonta a Classic ASP y SQL Server 6.5. Es editor jefe del blog relacionado con el rendimiento, SQLPerformance.com, y también tiene un blog en sqlblog.org.
Aaron Bertrand (@AaronBertrand) es un tecnólogo apasionado con experiencia en la industria que se remonta a Classic ASP y SQL Server 6.5. Es editor jefe del blog relacionado con el rendimiento, SQLPerformance.com, y también tiene un blog en sqlblog.org.Ver todos mis consejos
- Más consejos de DBA de SQL Server…