

私たちは、最近のテクノロジーに縛られることがどんな感じか知っています。 子供だけでなく、私たち全員がそうです。 2018年現在、世界のスマートフォンユーザーは約25億人です。 地球上の人口が約77億人であることを考えると、これはLOTなスマートフォンですね。 それから、ソーシャルメディアもあります。 Facebookだけで、22億5000万人以上のユーザーがいます。 Instagramは約4億人、Snapchatは約2億人です。
典型的なアメリカ人は、年間約1460時間をスマートフォンに費やしています。 しかし、スマートフォンには、私たちを支配する不思議な力があり、それに抗うことは困難です。 そのため、人々はメールを打ちながら運転したり、子供や友人、パートナーを無視したり、周囲の人々や世界と関わりを持たずに、スマートフォンをチェックするのです。 スクリーンが本当に中毒性があるかどうかはまだ議論の余地がありますが、クラックベリー、スナップクラック、ワールド オブ ウォークラック、ニュース ジャンキーなど、薬物に関連する言及が多く使われてきたことは注目に値します。 以前のブログで、古典的条件付けと超常的刺激の両方が、事実上抗しがたい引き寄せを部分的に説明できるメカニズムであることを述べました。 しかし、もうひとつのメカニズムが、最新のニュースフィード、テキスト、ソーシャルメディアへの投稿、電子メールなどを求めて、強迫的に画面をチェックするよう私たちを誘惑しているのです。 カウンターストライクやスターウォーズ・バトルフロントIIなど、多くのビデオゲームに含まれる「戦利品ボックス」の魅力もそれである。 このメカニズムは、可変比率強化スケジュールとして知られています。
A Little About Reinforcement Schedules
心理学の入門コースを受講したことがあるなら、おそらく B.F. スキナーに遭遇したことでしょう。 彼は心理学者であり行動学者で、異なる強化スケジュールによって行動反応がどのように確立され強化されるかを研究していました。 例えば、ケージに入れられたラットがレバーを押すと餌がもらえることを教えられると、レバーを3回押すごとに餌が1つもらえることを教えられるかもしれません。 これは固定間隔強化スケジュールの例でしょう。
異なる行動反応の可能性に影響を与える強化スケジュールにはさまざまな種類とサブタイプがありますが、可変比率強化スケジュールについて詳しく見ていきましょう。
Variable Ratio Reinforcement Schedule
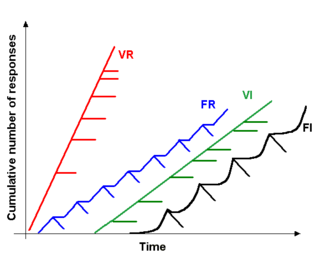
可変比率強化スケジュールは、X回行動した後に、ある報酬が達成される場合に発生します。 ラットの例では、ラットはレバーを何回押せば餌が出るのか知りません。 1回のときもあれば、5回のときもあり、15回のときもある。 そこで研究者は、ネズミが何回押せば餌が出るかわからないように、分布をランダム化する。
研究者は、可変比率のスケジュールが高い反応率になる傾向があることを発見しました (上のグラフの VR 線を参照ください)。 また、可変比率は消滅に対して極めて強い抵抗力を持ちます。 ラットの場合、もし研究者がレバーを押した後に餌のペレットを与えるのを止めると、ラットは最終的に諦めるまで非常に長い間頻繁にレバーを押すようになります(これが絶滅の部分です)。
Variable Reinforcement in Our Daily Lives
ギャンブルなど多くの行動依存症には、可変比率強化スケジュールが関与していることがわかりました。 はい、そのとおりです。 ある意味、強迫的に携帯電話をチェックするのは、強迫的なギャンブルとよく似ています。 これを「ベガス効果」と呼ぶこともできます。つまり、特定の行動に従事するために、ほとんど熱狂的な強迫観念を経験することができるのです。 実際、多くの「強迫観念」や趣味も、この可変比率の強化スケジュールを含んでおり、たとえば次のようなものがあります。 ポケモンカードや切手を集める)
Why Are Variable Reinforcement Schedules Powerful?
Variable reinforcement schedules are not bad. 私たちの脳の中にあるモチベーションと学習システムの重要な一部なのです。 私たちは「点をつなぐ」ことでカジュアルな関係を学びます。 進化の観点から、因果関係を学ぶことは、生存のチャンスを高めます。 例えば、「行動A」をしたときに、「結果B」の可能性が高いかどうかを学ぶことが重要なのです。 変動関係がある場合、「行動A」をしたときに「結果B」が出る可能性があるということです。 脳内の報酬系は、変動する状況下でドーパミンを放出し、生体に注意を促し、因果関係を学習させる。 これをインセンティブ・サリエンスと呼ぶことがある。 要するに、脳は生物に「暗号を解読せよ」という動機を与えているのです。
重要なのは、このドーパミン報酬系は「欲しい」と「好き」の間でより関与する傾向があることです。 何かが起こるかもしれないという期待感から、より頻繁に放出されるのです。 例えば、ジョニーがポケモンカードのパックを買って、今まさに開けようとしているとしましょう。 実際にカードパックを開ける前に、ドーパミンが放出されているのです。 事実上、ドーパミンは小さなジョニーにカードパックを開けるように(まあ、おそらく最初にカードを買うように!)動機づけしているのです。
可変強化およびスクリーン
ソーシャルメディア、テキスト、ゲームなどのテクノロジーが、可変強化スケジュールでどのように機能するかを見るのは簡単です(補足:スクリーンによっては、可変間隔と可変比率のスケジュールでより私たちに働きかけるかもしれませんが、同じ結果である可能性が高いと思われます)。 チョコレートの箱のように、私たちは何が出てくるかわからないのです。 誰がFacebookに投稿したのか? 彼らは何を投稿したのでしょうか? 私の投稿にコメントしたのは誰でしょう? 彼らは何を言ったのだろう? 何か重要な情報が入っているかもしれない。 携帯が鳴っている-何だろう? トランプの最新情報は? もう1回だけニュースフィードをチェックしてみよう…
私たちのスマートフォンがブザーやチャイムを鳴らした瞬間、このドーパミン報酬系は活性化します。 繰り返しになりますが、この報酬系を活性化させるカギとなるのは期待段階です。 私たちは、それが何であれ、この情報を見つけなければならないのです。 それはまるで、かゆいところに手が届くような、喉の渇きを癒すような感覚です。 ネズミが餌をもらおうとレバーを押すように、私たちは携帯電話をチェックし続けるのです。 このような強迫的な行動に陥ることはないと信じたいところですが、私たちはしばしば檻の中のネズミのように行動してしまうのです。