
By: Aaron Bertrand|Updated: 2019-12-03| コメント(1) | 関連するもの More > Performance Tuning
Problem
数年前、私は削除操作をチャンクに分割することによってトランザクション ログへの影響を減らす方法についてブログで紹介しました。 100,000 行を 1 つの大きなトランザクションで削除する代わりに、100 または 1,000 または任意の数の行を一度に、いくつかの小さなトランザクションで、ループで削除することができます。 ログへの影響を軽減するだけでなく、長時間続くブロッキングを緩和することができます。 当時はSSDが普及し始めた頃で、Clustered Columnstore Indexes、Delayed Durability、Accelerated Database Recoveryといった新しいテクノロジーはまだ存在していませんでした。 そこで、SQL Server2019 でこれがどのように展開されるかをよりよく理解するために、更新の時期が来たのかもしれないと思いました。
Solution
テーブルの大部分を削除することが常に唯一の答えというわけではありません。 テーブルの 95% を削除し、5% を保持する場合、保持する行を新しいテーブルに移動し、古いテーブルを削除して、新しいテーブルの名前を変更する方が実際に速い場合があります。 しかし、パージがキープよりも大きい場合でも、テーブル上の他の制約、SLA、および他の要因によって、これは常に可能とは限りません。
繰り返しますが、行を削除しなければならないことが判明した場合、トランザクション ログへの影響およびその操作が他の作業負荷に与える影響を最小限に抑えたいと思うでしょう。
セットアップするために、すべてのテストで真となる定数を複数用意しました。
- SQL Server 2019 RC1, 4 コアと 32 GB RAM (最大サーバー メモリ = 28 GB)
- 1000 万行テーブル
- Restart SQL Server after every test (to reset memory, buffers.)テスト毎に再起動します。 およびプランキャッシュ)
- 統計情報をすでに更新し、自動統計機能を無効にしたバックアップを復元する(統計情報の更新が削除操作に干渉するのを防ぐため)
テストごとに変更する変数も多く存在します。
これにより、864 のユニークなテストが作成され、これらの並べ替えをすべて自動化するつもりです。
そして、私たちが測定するメトリクス。
- 全体時間
- 平均/ピーク CPU 使用率
- 平均/ピーク メモリ使用率
- トランザクション ログ使用量/ファイルの増加
- データベース ファイル使用率。 バージョン ストアのサイズ (Accelerated DatabaseRecovery 使用時)
- Delta rowgroup size (Columnstore 使用時)
Source Table
まず、AdventureWorks (AdventureWorks2017) のコピーをリストアしてみました。bak,具体的には)を復元しました。 1000万行のテーブルを作成するために、Sales.Bakのコピーを作成しました。SalesOrderDetail のコピーを作成し、独自の ID 列を作成し、各行に少し肉付けしてページの密度を減らすためにフィラー列を追加しました。
INSERT dbo.SalesOrderDetailCopy
(
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
)
SELECT TOP(100000)
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
FROM Sales.SalesOrderDetail;GO 100
テーブルにはインデックスを作成しませんでした。ストレージのアプローチによっては、各テストの一環としてデータベースをリストアした後、新しいクラスタインデックス(半分の時間は列ストア)を作成する予定です。
Automating Tests
1000 万行のテーブルが存在したら、いくつかのオプションを設定し、データベースをバックアップし、ログを 2 回バックアップして、データベースを再度バックアップしました(リストア時にログの使用領域を最小にするために)。
実行したい 864 個のテストの順列をキャプチャするのに数回トライしましたが、最終的にこのようになりました。
予想どおり、これはこれらのすべての組み合わせで 864 行を挿入しました。私はまた、SentryOne SQL Sentry でインスタンスを監視しているので、そこで利用できる他の興味深い情報があることは確かですが、サードパーティのツールを使用せずに重要な詳細を捕捉したいと思いました。 以下は、与えられたタイムスタンプのすべてのメトリクスを 1 行で生成するプロシージャです。 収集のコストとデータの完全性の間のトレードオフがあり、どちらかに傾くかもしれません。
最後に、個々のテストに対してパラメータの組み合わせで何をするかを正確に決定するためのすべてのロジックを含むプロシージャを作成しました。これも何度か繰り返しましたが、最終的には次のようになりました。
そこで起こっていることはたくさんありますが、基本的なロジックは次のとおりです。SP_configure を変更し、バッファとプラン キャッシュをクリアすることにより、SQL Server を起動します。インデックスなし
- この反復処理でトランザクションを開始する必要があるかどうかを判断します
- 削除を実行します
- この反復処理でトランザクションをコミットする必要があるかどうかを判断します
- この反復処理でチェックポイント/ログバックアップを行う必要があるかどうかを判断します
実際にテストを実行するには、すべての出力、余分なトラフィック、およびリソース使用のため、Management Studio(同じ VM 上でも)でこれを実行したくありません。ストアド プロシージャを作成し、これをジョブにも入れました。
これは、私が認めるよりもはるかに時間がかかりました。 その理由の 1 つは、もともと rowperloop の 0.1% テストを含んでいたためで、場合によっては、数時間かかりました。 1,000,000 行を削除する場合、一度に 1,000 行を削除することは、他の変数に関係なく、最適な選択である可能性は非常に低いと言えます。
パフォーマンス結果
0.1%のテストの結果を破棄した後、残りを継続時間をロードした 2 番目のメトリクステーブルに入れました。 つまり、一部の高速テストでは、実行速度以外の他の性能の詳細との相関がないことを意味します。 まず、Delayed Durability (DD) および/または Accelerated Database Recovery (ADR) が有効になっているかどうかに基づいて、持続時間と CPU をチェックしました:
結果 (異常をハイライト表示):

どちらのオプションがオンになっても、平均でほぼ同じだけ全体の持続時間が向上するように見えます (両方有効の場合はピーク値はより低くなります)。 平均に影響しない ADR だけの持続時間の異常値があるようです (この特定のテストでは、行ストア テーブルで FULL 回復中に一度に 9,000,000 行を削除しています)。 DD の CPU 異常値も平均値に影響を与えませんでした。この特定の例は、列ストア テーブル上で 1,000,000 行を一度に削除するものでした。
列ストアと列ストアの比較による全体的な違いはどうでしょうか:

列ストアは平均で 20% 遅いが必要メモリは少なかった。
Results:

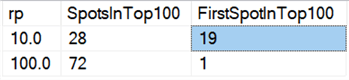
最後に、今日のハードウェアでは、チャンクでの削除は、少なくとも持続時間の点で、かつてと同じ利点はないように思われます。 最速の 18 結果、および最速の 100 結果のうち 72 結果は、すべての行を一度に削除したテストであり、このクエリで明らかになりました:
Results:
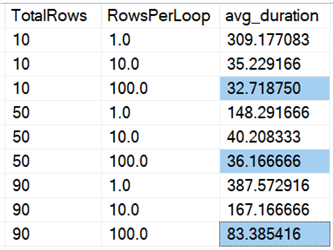
また、すべてのデータにわたる平均を見ると、このクエリと同様です。
一度にすべての行を削除すると、10%、50%、または 90% の削除に関係なく、どの方法でもチャンク削除より速いことがわかります (これも平均値)。
グラフ形式:
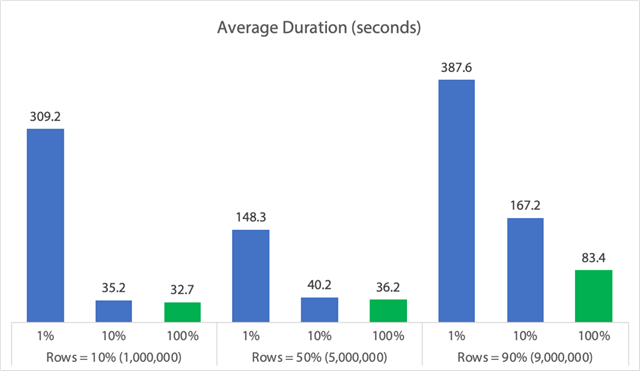
(先に特定した 6,062 秒間の max_durationoutlier を削除すると、最初の列が 309 秒から 162 秒に減少します。)
さて、最良のケースであっても、adelete が実行され、他のすべての人をブロックする可能性があるのは 33、36、または 83 秒であり、これは、メモリ、ログ ファイル、CPU などの他の測定による影響を無視した場合です。 持続時間は確かに唯一の基準であるべきではありません。それは、人々が通常最初に(そして時には唯一)見るものであることを意味します。 このテストハーネスは、他のいくつかのメトリクスもキャプチャできること、またそうする必要があることを示すためのもので、結果は、異常値はどこからでも発生することを示しています。
このハーネスをモデルとして使用すると、環境の制約や機能にもっと焦点を絞った独自のテストを構築することができます。 このハーネスをモデルとして、自分の環境の制約や能力に焦点を絞った独自のテストを構築することができます。 もし、あなたがデータをスライスして見たい他の方法があれば、下のコメント欄で知らせてください。 4431>
Caveats
これはすべて、同時作業負荷、外部キーなどのテーブル制約の影響、トリガーの存在、およびその他の可能なシナリオのホストを考慮していません。テストする別のものは (潜在的に将来のヒントで) 操作を通してこの同じテーブルと相互作用する複数のジョブがあり、ブロックの持続時間、待ちタイプと時間のようなものを測定し、どの状況で1セットの活動が他のセットにより劇的な影響を持つかを測定します。
次のステップ
関連するヒントやその他のリソースについては、こちらをお読みください。
- SQL Server における CRUD 操作
- SQL Server における Delete と Truncate の違い
- Delete は大きな並列 SQL Server DatabaseTable から履歴データを削除
- Break large delete operations into chunks
- Ready for SQL Server 5105
- SQL Server Clustered and Nonclustered Columnstore Index Example
- Delayed Durability in SQL Server 2014
- Delayed Durability while Purging Data
- Accelerated Database Recovery in SQL Server 2019
Last Updated: 2019-12-03


著者について
 Aaron Bertrand (@AaronBertrand) は情熱的な技術者で、業界の経験は Classic ASP と SQL Server 6.5 までさかのぼることができます。 彼はパフォーマンス関連のブログ SQLPerformance.com の編集長であり、sqlblog.org でもブログを書いています。
Aaron Bertrand (@AaronBertrand) は情熱的な技術者で、業界の経験は Classic ASP と SQL Server 6.5 までさかのぼることができます。 彼はパフォーマンス関連のブログ SQLPerformance.com の編集長であり、sqlblog.org でもブログを書いています。私のヒントをすべて見る
- More SQL Server DBA Tips…
私のヒントをすべて見る