
毎日使うデータ構造を知っておこう。
👋 ようこそ! 重要なコンテキストから始めましょう。 これをお聞きします。
✅ スマートフォンで音楽を聴きますか?
✅ 携帯電話に連絡先のリストを保存していますか?
✅ 競技中にリーダーボードを見たことがありますか?
これらの質問のいずれかに「はい」と答えた場合、ほぼ確実に、知らないうちに配列を使っています!
配列を使用する方法については、次のとおりです。 配列は、要素のリストを格納する非常に強力なデータ構造です。 その用途は無限大です。
この記事では、配列の長所と短所、その構造、操作、および使用例について学びます。 👍
🔎 配列の基本構造への深入り
配列の仕組みを理解するには、コンピューターのメモリを下の図のような格子状に視覚化すると非常に便利です。 8081>

配列はこの「グリッド」構造を利用して、関連する情報のリストを隣接するメモリ位置に格納し、それらの値を見つけるための非常に効率的な方法を保証しています。 🔳🔳🔳
配列はこのように考えることができます:
その要素はメモリ内で互いに隣接して配置されます。 複数の要素にアクセスする必要がある場合、コンピューターはすでに値がどこにあるか知っているので、処理は非常に最適化されます。
すごいでしょう? では、これが舞台裏でどのように機能しているのかを学んでいきましょう!
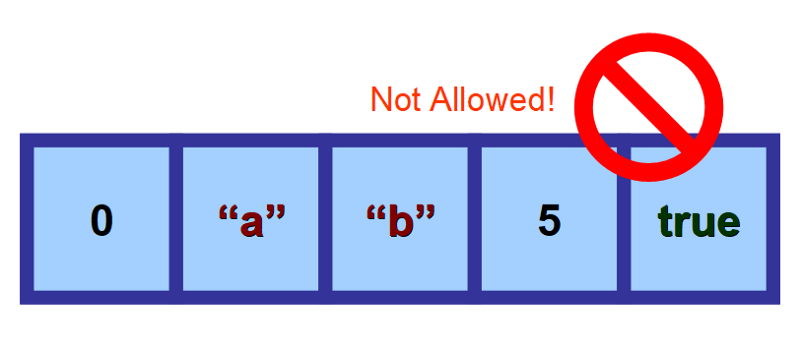
配列は、同じ型の要素を格納するため、同種のデータ構造に分類されます。 しかし、いったん配列が格納する値の型を定義すると、その要素はすべてその同じ型である必要があります。 8081>
👀 値の読み取り – 魔法の始まり!
配列の驚くべき力は、値にアクセスする効率から来るものです。 これは、その格子状の構造のおかげで達成されます。 より詳しく見ていきましょう。🔍
配列を作成するとき、
-変数に代入します。 👈
– 格納する要素の種類を定義する。 🎈
– サイズ (要素の最大数) を定義する。 注:この変数に割り当てる名前は、後のコードで値にアクセスしたり配列を変更したりするために使用するため、非常に重要です。 これは、インデックスが重要な役割を果たすところです!
1️⃣ インデックス
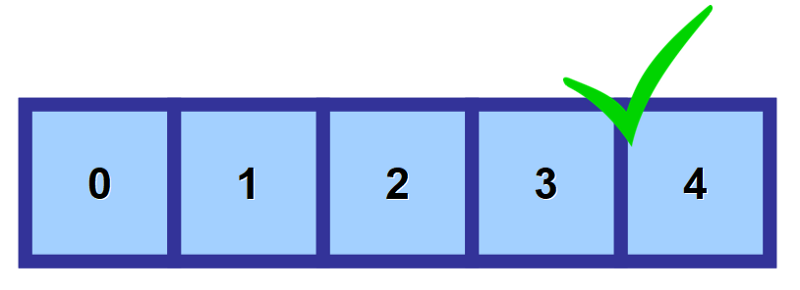
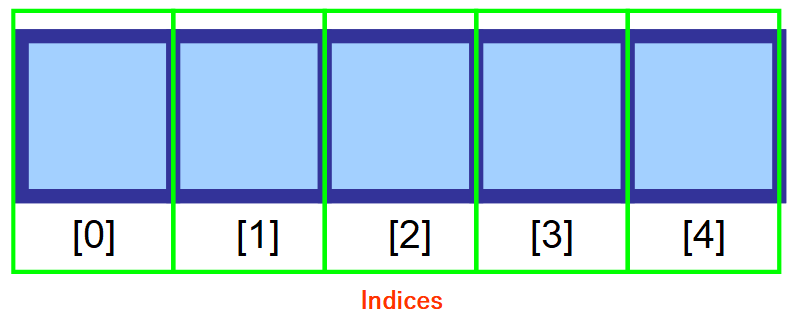
配列内の値にアクセスするには、「インデックス」(複数形で「indices」)と呼ばれるものを使用します。 これは、値が格納されている場所を示す番号です。
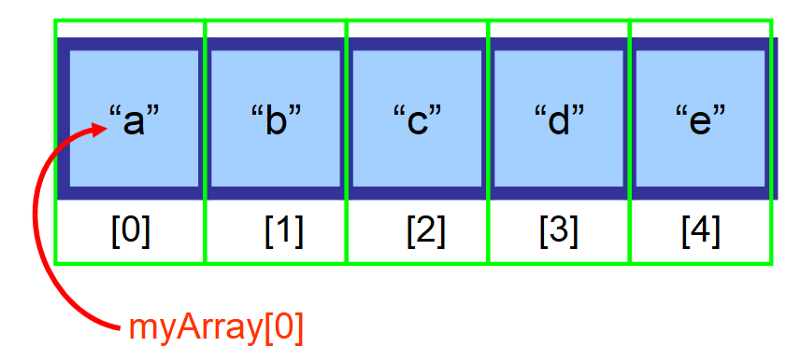
下の図でわかるように、配列の最初の要素はインデックス 0 を使用して参照されます。 さらに右に進むと、メモリ内のスペースごとにインデックスが 1 つずつ増えます。
💡 注: 最初は 1 からではなく 0 から数え始めるのはおかしいと思うでしょうが、これはゼロベース番号付けと呼ばれるものです。 コンピューター サイエンスでは非常に一般的です。
要素にアクセスするための一般的な構文は次のとおりです。 <ArrayVariable>
たとえば、配列が変数 myArray に格納されていて、最初の要素(インデックス 0)にアクセスしたい場合、myArray
2️⃣ Memory
値へのアクセス方法がわかったところで、配列がコンピューターのメモリにどう格納されるかを見てみましょう。 配列のサイズを定義すると、メモリ内のそのスペースはすべて、将来挿入したい値のためにその時点から「予約」されます。
💡注意:配列に値を入力しない場合、そのスペースは予約されて空いたまま、その値を入力するまで保持されます。
配列は、すべての要素がメモリ内の連続したスペースに格納されるため、値へのアクセスにおいて非常に効率的なので、これは重要なポイントです。 この方法では、コンピューターは要求された情報を見つけるためにどこを見ればよいかを正確に知っています。
しかし…これには欠点があります😞 なぜならこれはメモリ効率的ではないためです。 発生しないかもしれない将来の操作のために、メモリを予約していることになります。
🔧 演算 – 裏技!
配列がどのようなときに使われ、どのように要素を格納するかがわかったところで、挿入や削除といった操作に飛び込みます。
1️⃣ 挿入 – ようこそ!
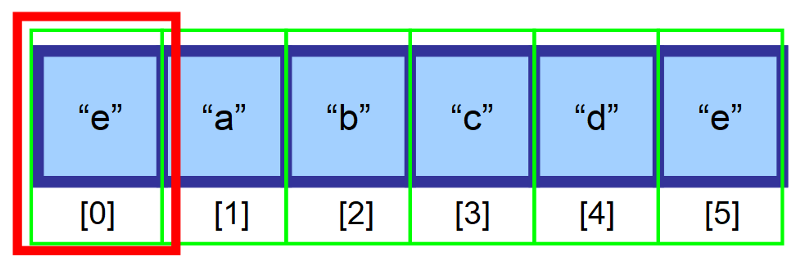
サイズ6の配列があって、まだ空のスペースがあるとします。 配列の先頭(インデックス 0)に要素 “e” を挿入したいのですが、この場所はすでに要素 “a” によって占拠されています。 どうすればよいでしょうか。
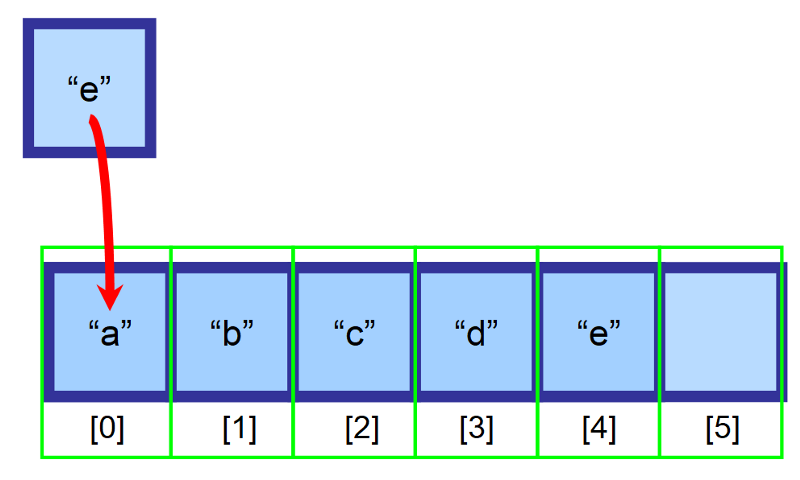
配列に挿入するには、挿入場所の右側にあるすべての要素を、1 つのインデックス右に移動させるのです。 要素「a」は現在インデックス 1 に、要素「b」はインデックス 2 に…というようになります。
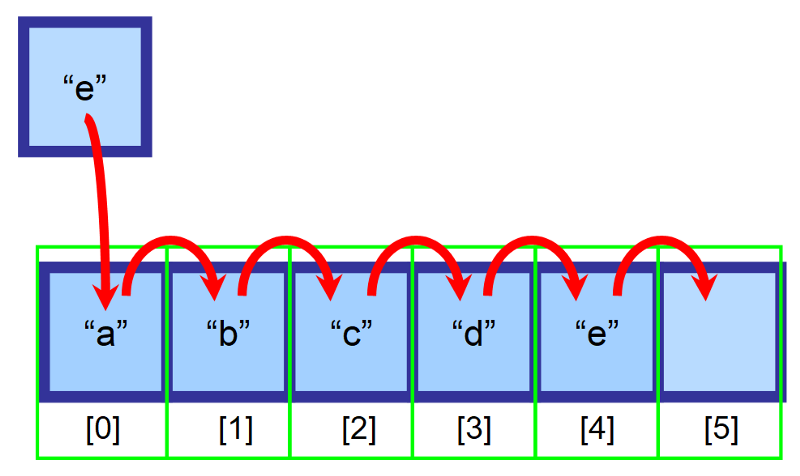
💡注意:要素を含む最後のインデックスを追跡するための変数を作成する必要があります。 上の図では、挿入前に配列はインデックス 4 まで埋め尽くされています。 この方法で、配列が一杯になったかどうかを判断し、最後に要素を挿入するためにどのインデックスを使用すべきかを判断できます。
これを行った後、要素が正常に挿入されました。 👏
⚠️ ちょっと待った! 配列が一杯になったらどうなるんだ❔❔
配列が一杯になって、要素を挿入しようとしたらどうなると思う? 😱
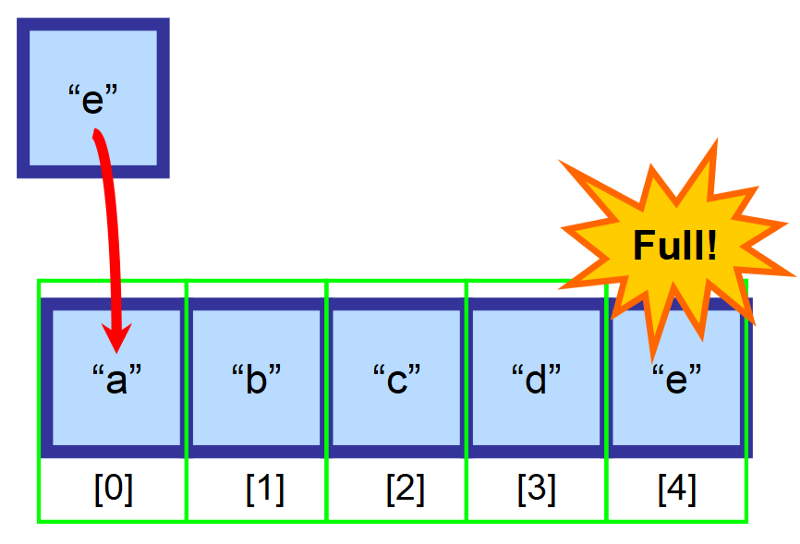
この場合、新しい大きな配列を作成し、この新しい配列にすべての要素を手動でコピーする必要があります。 この操作は、時間的に非常に高くつきます。 何百万もの要素を持つ配列があった場合、何が起こるか想像してみてください! 何百万もの要素を持つ配列があったらどうなるか、想像してみてください!完了するまでに非常に長い時間がかかるでしょう。 ⏳
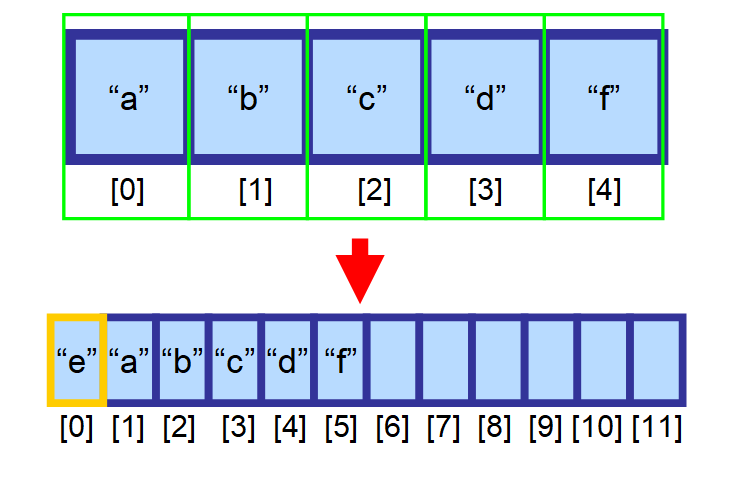
💡 注意:挿入が非常に速い場合の唯一の例外は、配列の最後(最後の要素の右側にあるインデックス)に要素を挿入するとき、まだ空きがあることです。 これは定数時間 O(1) で行われます。
2️⃣ Deletion- Bye, Bye!
さて、配列から要素を削除したいとします。
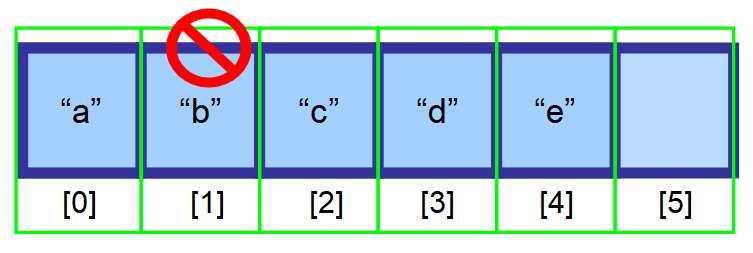
ランダム アクセスの効率(インデックスを通して配列に非常に速くアクセスできる)を維持するには、要素がメモリの連続した空間に格納されていなければなりません。 要素を削除してそのスペースを空にすることはできません。
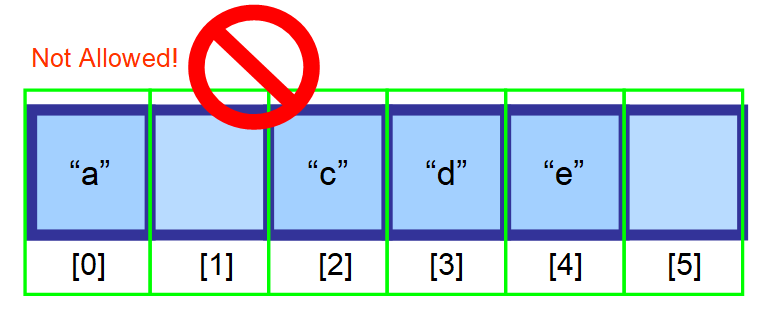
削除したい要素の後に来る要素は、1 つ左のインデックスに移動させる必要があります。
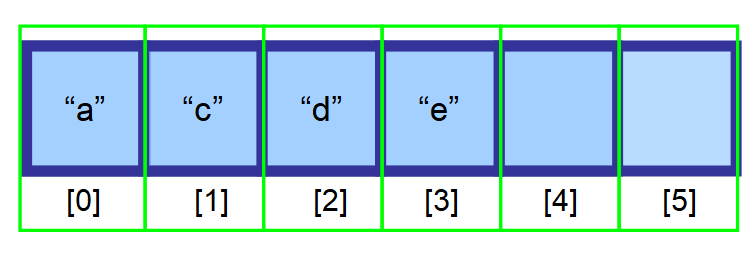
💡 注意:削除は、最後の要素を削除するときに非常に効率的です。 要素を含む最後のインデックス(上の図ではインデックス3)を記録するための変数を作成する必要があるので、インデックスを使って直接その要素を削除することができます。
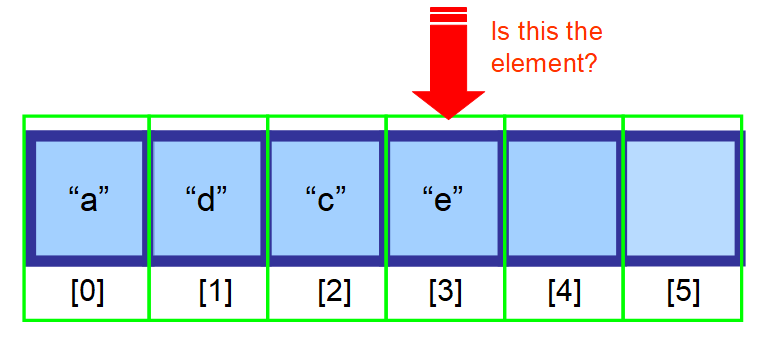
3️⃣ 要素の検索
配列内の要素を検索するには、3 つのオプションがあります:
- それがどこにあるかがわかっている場合、インデックスを使用します。
- それがどこにあるかがわからない場合、データがソートされていれば、2 進探索などのアルゴリズムを使用して最適な検索が可能です。
- 位置がわからず、データがソートされていない場合は、配列のすべての要素を検索し、現在の要素が探している要素であるかどうかを確認する必要があります(以下の一連の図を参照してください)。
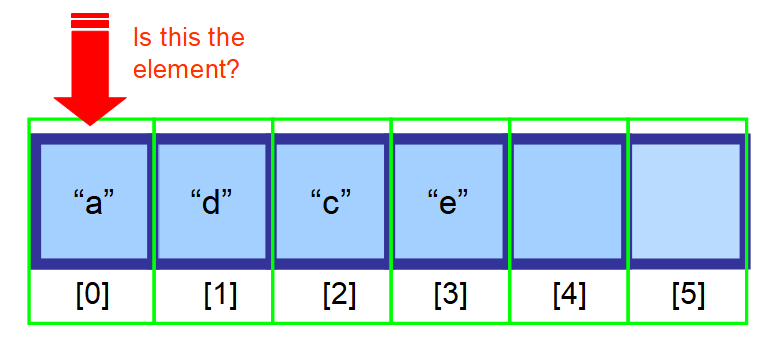

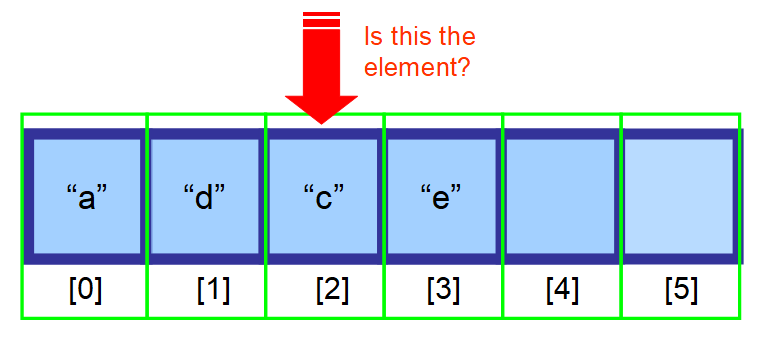
👋 まとめ…
- 配列は同じ型の要素を格納する非常に強力なデータ構造である。 要素の型と配列のサイズは固定で、作成時に定義されます。
- メモリは配列の作成直後に割り当てられ、値を代入するまで空の状態です。
- その要素はメモリ内の連続した場所に配置されるので、インデックスを使用して非常に効率的にアクセスできます (ランダムアクセス、O(1) = 定時間)。
- インデックスは、我々が慣れている1ではなく 0 から始まります。 配列が一杯の場合は、新しい大きな配列を作成します (これはあまり効率的ではありません)。
- 配列の先頭または途中から要素を削除する場合、メモリに空きができないように、すべての要素を左に移動させます。 これにより,メモリ内の連続したスペースに要素が格納されることが保証されます。 配列の終端での削除は、最後の要素だけを削除するので非常に効率的です。
- ある要素を見つけるには、それを見つけるまで配列全体をチェックする必要があります。
「昨日から学び、今日を生き、明日に希望を持て。 重要なのは、疑問を持つことを止めないことだ」
– Albert Einstein
👋 ありがとうございます!
私の記事を気に入ってもらえたなら、本当に嬉しいです。 ❤️
このような記事をもっと見つけるために、Twitterで私をフォローしてください。 😃