
- Ayez accès aux meilleurs projets ML
- Projets d’apprentissage automatique pour les débutants en 2021
- Prévision des ventes à l’aide du jeu de données Walmart
- Projet ML de prédiction des ventes de BigMart
- Système de recommandation musicale. Projet
- Reconnaissance de l’activité humaine à l’aide d’un ensemble de données sur les smartphones
- Prédiction des prix des actions à l’aide de séries temporelles
- Prédiction de la qualité du vin à l’aide d’un ensemble de données sur la qualité du vin
- MNIST Classification de chiffres manuscrits
- Apprendre à construire des systèmes de recommandation avec le jeu de données Movielens
- Projet ML de prédiction du prix des logements à Boston
- Analyse du sentiment des médias sociaux à l’aide de Twitter. Ensemble de données
- Projet ML de classification des fleurs d’iris
- Optimisation des prix de détail à l’aide du Machine Learning
- Analyse de prédiction du taux de désabonnement des clients
- 1. Prévision des ventes à l’aide du jeu de données Walmart
- 2. Projet ML de prévision des ventes BigMart – Apprenez les algorithmes d’apprentissage automatique non supervisés
- Projet de système de recommandation musicale
- Human Activity Recognition using Smartphone Dataset
- Prédicteur de prix des actions utilisant des séries temporelles
- Prédire la qualité du vin en utilisant le jeu de données sur la qualité du vin
- Classification des chiffres manuscrits du MNIST
- Apprenez à construire des systèmes de recommandation avec le Movielens Dataset
- Projet ML de prédiction des prix des logements à Boston
- Social Media Sentiment Analysis using Twitter Dataset
- Projet ML de classification Iris Flowers – Apprenez les algorithmes d’apprentissage automatique supervisés
- Projets d’apprentissage automatique pour les débutants avec code source en Python pour 2021
- 12) Projet ML d’optimisation des prix de détail – Modèle d’apprentissage automatique de tarification dynamique pour un marché dynamique
- 13) Analyse de prédiction du taux de désabonnement des clients à l’aide de techniques d’ensemble en apprentissage automatique
- Comment puis-je commencer un projet d’apprentissage automatique?
- 1) Première étape : Délimitation du projet d’apprentissage automatique
- 2) Deuxième étape : Les données
- 3) Troisième étape – Construire le modèle
- 4) Quatrième étape -Déploiement du modèle en production
- Comment mettre des projets d’apprentissage automatique sur votre CV ?
- Quoi ensuite ?
Ayez accès aux meilleurs projets ML
×
Dernière mise à jour : 05 Mar 2021

Vous voulez apprendre l’apprentissage automatique mais vous avez du mal à vous y mettre. Les livres et les cours pourraient ne pas être juste suffisants quand il s’agit de l’apprentissage automatique bien qu’ils donnent toujours des exemples de codes et de snippets d’apprentissage automatique, vous n’avez pas l’occasion de mettre en œuvre l’apprentissage automatique à des problèmes du monde réel et de voir comment ces snippets de code s’assemblent. La meilleure façon de commencer à apprendre l’apprentissage automatique est de mettre en œuvre des projets d’apprentissage automatique de niveau débutant à avancé. Il est toujours utile d’avoir un aperçu de la façon dont les vraies personnes commencent leur carrière dans l’apprentissage automatique en mettant en œuvre des projets ML de bout en bout.
Dans cet article de blog, vous découvrirez comment les débutants comme vous peuvent faire de grands progrès dans l’application de l’apprentissage automatique à des problèmes du monde réel avec ces fantastiques projets d’apprentissage automatique pour les débutants recommandés par des experts de l’industrie. Les experts industriels de ProjectPro ont soigneusement sélectionné la liste des meilleurs projets d’apprentissage automatique pour les débutants qui couvrent les aspects fondamentaux de l’apprentissage automatique tels que l’apprentissage supervisé, l’apprentissage non supervisé, l’apprentissage profond et les réseaux neuronaux. Dans tous ces projets d’apprentissage automatique, vous commencerez par des ensembles de données du monde réel qui sont accessibles au public. Nous vous assurons que vous trouverez ce blog absolument intéressant et digne d’être lu en raison de toutes les choses que vous pouvez apprendre ici sur les projets d’apprentissage automatique les plus populaires.
« Quels projets puis-je faire avec l’apprentissage automatique ? » Cette question nous est souvent posée par les débutants qui se lancent dans l’apprentissage automatique. Les experts de l’industrie ProjectPro vous recommandent d’explorer quelques idées de projets d’apprentissage automatique passionnants, cool, amusants et faciles à réaliser dans divers domaines d’activité afin d’acquérir une expérience pratique sur les compétences d’apprentissage automatique que vous avez apprises. Nous avons dressé une liste de projets d’apprentissage automatique innovants et intéressants avec code source pour les professionnels qui débutent leur carrière dans l’apprentissage automatique. Ces projets pour débutants sur l’apprentissage automatique sont un mélange parfait de divers types de défis que l’on peut rencontrer lorsqu’on travaille en tant qu’ingénieur en apprentissage automatique ou scientifique des données.
Projets d’apprentissage automatique pour les débutants en 2021
-
Prévision des ventes à l’aide du jeu de données Walmart
-
Projet ML de prédiction des ventes de BigMart
-
Système de recommandation musicale. Projet
-
Reconnaissance de l’activité humaine à l’aide d’un ensemble de données sur les smartphones
-
Prédiction des prix des actions à l’aide de séries temporelles
-
Prédiction de la qualité du vin à l’aide d’un ensemble de données sur la qualité du vin
-
MNIST Classification de chiffres manuscrits
-
Apprendre à construire des systèmes de recommandation avec le jeu de données Movielens
-
Projet ML de prédiction du prix des logements à Boston
-
Analyse du sentiment des médias sociaux à l’aide de Twitter. Ensemble de données
-
Projet ML de classification des fleurs d’iris
-
Optimisation des prix de détail à l’aide du Machine Learning
-
Analyse de prédiction du taux de désabonnement des clients
Plongeons-nous !

1. Prévision des ventes à l’aide du jeu de données Walmart
La prévision des ventes est l’un des cas d’utilisation les plus courants de l’apprentissage automatique pour identifier les facteurs qui affectent les ventes d’un produit et estimer le volume des ventes futures. Ce projet d’apprentissage automatique utilise l’ensemble de données Walmart qui contient des données sur les ventes de 98 produits dans 45 points de vente. L’ensemble de données contient les ventes par magasin et par département sur une base hebdomadaire. L’objectif de ce projet d’apprentissage automatique est de prévoir les ventes pour chaque rayon dans chaque point de vente afin de les aider à prendre de meilleures décisions fondées sur les données pour l’optimisation des canaux et la planification des stocks. L’aspect difficile de travailler avec l’ensemble de données Walmart est qu’il contient des événements de démarque sélectionnés qui affectent les ventes et doivent être pris en considération.
C’est l’un des projets d’apprentissage automatique les plus simples et les plus cool où vous allez construire un modèle prédictif en utilisant l’ensemble de données Walmart pour estimer le nombre de ventes qu’ils vont faire dans le futur et voici comment –
- Importer les données et les explorer pour comprendre la structure et les valeurs dans les données – Commencez par importer un fichier CSV et effectuer une analyse de données exploratoires (EDA) de base.
- Préparer les données pour la modélisation- Fusionner plusieurs ensembles de données et appliquer la fonction de groupe par pour analyser les données.
- Placer un graphique de séries temporelles et l’analyser.
- Fixer les modèles de prévision des ventes développés sur les données d’entraînement- Créer un modèle ARIMA pour la prévision des séries temporelles
- Comparer les modèles développés sur les données de test.
- Optimiser les modèles de prévision des ventes en choisissant des caractéristiques importantes pour améliorer le score de précision.
- Faites usage du meilleur modèle d’apprentissage automatique pour prévoir les ventes de l’année prochaine.
Après avoir travaillé sur ce projet d’apprentissage automatique Kaggle, vous comprendrez comment de puissants modèles d’apprentissage automatique peuvent simplifier le processus global de prévision des ventes. Réutiliser ces modèles d’apprentissage automatique de prévision des ventes de bout en bout dans la production pour prévoir les ventes pour tout département ou magasin de détail.
Vous voulez travailler avec Walmart Dataset ? Accédez à la solution complète de ce projet d’apprentissage automatique génial ici – Projet d’apprentissage automatique de prévision des ventes des magasins Walmart
2. Projet ML de prévision des ventes BigMart – Apprenez les algorithmes d’apprentissage automatique non supervisés
Le jeu de données des ventes BigMart se compose de données de ventes 2013 pour 1559 produits à travers 10 points de vente différents dans différentes villes. L’objectif du projet ML de prédiction des ventes BigMart est de construire un modèle de régression pour prédire les ventes de chacun des 1559 produits pour l’année suivante dans chacun des 10 points de vente BigMart différents. Le jeu de données des ventes BigMart comprend également certains attributs pour chaque produit et chaque magasin. Ce modèle aide BigMart à comprendre les propriétés des produits et des magasins qui jouent un rôle important dans l’augmentation de leurs ventes globales.
Accéder à la solution complète de ce projet ML ici – Solution de projet d’apprentissage automatique de prédiction des ventes BigMart
Projet de système de recommandation musicale
C’est l’un des projets d’apprentissage automatique les plus populaires et peut être utilisé dans différents domaines. Vous pourriez être très familier avec un système de recommandation si vous avez utilisé un site de commerce électronique ou un site de films/musique. Sur la plupart des sites de commerce électronique comme Amazon, au moment de passer à la caisse, le système vous recommande des produits à ajouter à votre panier. De même, sur Netflix ou Spotify, en fonction des films que vous avez aimés, le système vous propose des films ou des chansons similaires que vous pourriez aimer. Comment le système fait-il cela ? C’est un exemple classique où l’apprentissage automatique peut être appliqué.
Dans ce projet, nous utilisons le jeu de données du principal service de streaming musical d’Asie pour construire un meilleur système de recommandation musicale. Nous allons essayer de déterminer quelle nouvelle chanson ou quel nouvel artiste un auditeur pourrait aimer en fonction de ses choix précédents. La tâche principale consiste à prédire les chances qu’a un utilisateur d’écouter une chanson de manière répétitive dans un laps de temps donné. Dans l’ensemble de données, la prédiction est marquée 1 si l’utilisateur a écouté la même chanson au cours d’un mois. Le jeu de données se compose de quelle chanson a été écoutée par quel utilisateur et à quel moment.
Voulez-vous construire un système de recommandation – consultez ce projet ML résolu ici – Music Recommendation Machine Learning Project
Human Activity Recognition using Smartphone Dataset
Le jeu de données du smartphone se compose d’enregistrements d’activité physique de 30 personnes capturées par le biais de smartphones équipés de capteurs inertiels. L’objectif de ce projet d’apprentissage automatique est de construire un modèle de classification qui peut identifier précisément les activités de fitness humaines. Travailler sur ce projet d’apprentissage automatique vous aidera à comprendre comment résoudre les problèmes de multi-classification.
Ayez accès au code source de ce projet ML ici Reconnaissance d’activité humaine à l’aide du projet de jeu de données de smartphone
Cliquez ici pour afficher une liste de 50+ résolus, solutions de projet Big Data et Machine Learning de bout en bout (code réutilisable + vidéos)
Prédicteur de prix des actions utilisant des séries temporelles
C’est une autre idée de projet d’apprentissage automatique intéressante pour les scientifiques de données/ingénieurs d’apprentissage automatique travaillant ou prévoyant de travailler avec le domaine de la finance. Un prédicteur de prix des actions est un système qui apprend les performances d’une entreprise et prédit les futurs prix des actions. Les défis associés au travail avec des données sur les prix des actions sont qu’elles sont très granulaires, et de plus il y a différents types de données comme les indices de volatilité, les prix, les indicateurs macroéconomiques mondiaux, les indicateurs fondamentaux, et plus encore. L’avantage de travailler avec des données boursières est que les marchés financiers ont des cycles de rétroaction plus courts, ce qui permet aux experts en données de valider plus facilement leurs prédictions sur de nouvelles données. Pour commencer à travailler avec des données boursières, vous pouvez vous attaquer à un problème d’apprentissage automatique simple, comme la prédiction de l’évolution des prix sur six mois à partir d’indicateurs fondamentaux tirés du rapport trimestriel d’une entreprise. Vous pouvez télécharger des ensembles de données boursières sur Quandl.com ou Quantopian.com. Il existe différentes méthodes de prévision de séries temporelles pour prévoir le prix des actions, la demande, etc.
Voyez ce projet d’apprentissage automatique où vous apprendrez à déterminer quelle méthode de prévision utiliser quand et comment l’appliquer avec un exemple de prévision de séries temporelles. Prédicteur des prix des actions en utilisant le projet TimeSeries
Prédire la qualité du vin en utilisant le jeu de données sur la qualité du vin
C’est un fait connu que plus le vin est vieux, meilleur est son goût. Cependant, il y a plusieurs facteurs autres que l’âge qui entrent dans la certification de la qualité du vin qui incluent des tests physiochimiques comme la quantité d’alcool, l’acidité fixe, l’acidité volatile, la détermination de la densité, le pH, et plus encore. L’objectif principal de ce projet d’apprentissage automatique est de construire un modèle d’apprentissage automatique pour prédire la qualité des vins en explorant leurs différentes propriétés chimiques. Le jeu de données sur la qualité du vin se compose de 4898 observations avec 11 variables indépendantes et 1 variable dépendante.
Ayez accès à la solution complète de ce projet d’apprentissage automatique ici – Prédiction de la qualité du vin en R
Classification des chiffres manuscrits du MNIST
L’apprentissage profond et les réseaux neuronaux jouent un rôle essentiel dans la reconnaissance d’images, la génération automatique de textes et même les voitures à conduite autonome. Pour commencer à travailler dans ces domaines, vous devez commencer par un jeu de données simple et gérable comme le jeu de données MNIST. Il est difficile de travailler avec des données d’image sur des données relationnelles plates et, en tant que débutant, nous vous suggérons de relever et de résoudre le défi de classification de chiffres manuscrits MNIST. L’ensemble de données MNIST est trop petit pour tenir dans la mémoire de votre PC et est adapté aux débutants. Cependant, la reconnaissance de chiffres manuscrits vous mettra au défi.
Faites votre entrée classique dans la résolution de problèmes de reconnaissance d’images en accédant à la solution complète ici – MNIST Handwritten Digit Classification Project
Apprenez à construire des systèmes de recommandation avec le Movielens Dataset
De Netflix à Hulu, le besoin de construire un système de recommandation de films efficace a gagné en importance au fil du temps avec la demande croissante des consommateurs modernes pour un contenu personnalisé. L’un des ensembles de données les plus populaires disponibles sur le Web pour les débutants qui veulent apprendre à construire des systèmes de recommandation est l’ensemble de données Movielens qui contient environ 1 000 209 évaluations de films de 3 900 films faites par 6 040 utilisateurs de Movielens. Vous pouvez commencer à travailler avec ce jeu de données en construisant une visualisation world-cloud des titres de films pour construire un système de recommandation de films.
Un accès gratuit à des exemples de code résolus peut être trouvé ici (ceux-ci sont prêts à être utilisés pour vos projets ML)
Projet ML de prédiction des prix des logements à Boston
Le jeu de données des prix des logements à Boston se compose des prix des logements à travers différents endroits de Boston. Le jeu de données se compose également d’informations sur les zones d’activités non commerciales (INDUS), le taux de criminalité (CRIM), l’âge des personnes qui possèdent une maison (AGE), et plusieurs autres attributs (le jeu de données a un total de 14 attributs). Le jeu de données sur le logement à Boston peut être téléchargé à partir du dépôt d’apprentissage automatique de l’UCI. L’objectif de ce projet d’apprentissage automatique est de prédire le prix de vente d’une nouvelle maison en appliquant les concepts de base de l’apprentissage automatique aux données sur les prix des logements. Ce jeu de données est trop petit avec 506 observations et est considéré comme un bon début pour les débutants en apprentissage automatique pour donner un coup de pouce à leur pratique pratique sur les concepts de régression.
Lecture recommandée – 15+ Data Science Projects for Beginners
Social Media Sentiment Analysis using Twitter Dataset
Les plateformes de médias sociaux comme Twitter, Facebook, YouTube, Reddit génèrent d’énormes quantités de big data qui peuvent être exploitées de diverses manières pour comprendre les tendances, les sentiments du public et les opinions. Aujourd’hui, les données des médias sociaux sont devenues pertinentes pour la stratégie de marque, le marketing et les affaires dans leur ensemble. Un analyseur de sentiments apprend à connaître les différents sentiments qui se cachent derrière un « élément de contenu » (il peut s’agir d’une messagerie instantanée, d’un courrier électronique, d’un tweet ou de toute autre publication sur les médias sociaux) grâce à l’apprentissage automatique et les prédit à l’aide de l’intelligence artificielle.Les données Twitter sont considérées comme un point d’entrée définitif pour les débutants qui souhaitent s’exercer aux problèmes d’apprentissage automatique de l’analyse des sentiments. En utilisant l’ensemble de données Twitter, on peut obtenir un mélange captivant de contenu de tweet et d’autres métadonnées connexes telles que les hashtags, les retweets, l’emplacement, les utilisateurs, et plus encore qui ouvrent la voie à une analyse perspicace. L’ensemble de données Twitter se compose de 31 962 tweets et sa taille est de 3 Mo. En utilisant les données Twitter, vous pouvez découvrir ce que le monde dit sur un sujet, qu’il s’agisse de films, de sentiments sur les élections américaines ou de tout autre sujet d’actualité comme la prédiction du vainqueur de la coupe du monde de football 2018. Travailler avec l’ensemble de données Twitter vous aidera à comprendre les défis associés à l’exploration de données sur les médias sociaux et à apprendre les classificateurs en profondeur. Le premier problème sur lequel vous pouvez commencer à travailler en tant que débutant est de construire un modèle pour classer les tweets comme positifs ou négatifs.
Accès gratuit au code résolu Des exemples Python et R peuvent être trouvés ici (ils sont prêts à l’emploi pour vos projets de Data Science et de ML)
Projet ML de classification Iris Flowers – Apprenez les algorithmes d’apprentissage automatique supervisés
C’est l’un des projets d’apprentissage automatique les plus simples avec Iris Flowers étant les ensembles de données d’apprentissage automatique les plus simples dans la littérature de classification. Ce problème d’apprentissage automatique est souvent appelé le « Hello World » de l’apprentissage automatique. L’ensemble de données a des attributs numériques et les débutants en ML doivent comprendre comment charger et manipuler les données. L’ensemble de données d’iris est petit qui s’insère facilement dans la mémoire et ne nécessite pas de transformations spéciales ou de mise à l’échelle, pour commencer.
L’ensemble de données d’iris peut être téléchargé à partir de UCI ML Repository – Download Iris Flowers Dataset
Le but de ce projet d’apprentissage automatique est de classer les fleurs parmi les trois espèces – virginica, setosa, ou versicolor en fonction de la longueur et de la largeur des pétales et des sépales.
Un accès gratuit à des exemples de code Python et R d’apprentissage automatique résolus peut être trouvé ici (ceux-ci sont prêts à être utilisés pour vos projets)
Projets d’apprentissage automatique pour les débutants avec code source en Python pour 2021
12) Projet ML d’optimisation des prix de détail – Modèle d’apprentissage automatique de tarification dynamique pour un marché dynamique
Les courses à la tarification se développent sans arrêt dans toutes les verticales industrielles et l’optimisation des prix est la clé pour gérer efficacement les profits de toute entreprise. Identifier une fourchette de prix raisonnable et procéder à un ajustement de la tarification des produits pour augmenter les ventes tout en maintenant les marges bénéficiaires optimales a toujours été un défi majeur dans le secteur du commerce de détail. La façon la plus rapide pour les détaillants d’assurer le meilleur retour sur investissement aujourd’hui tout en optimisant la tarification est de tirer parti de la puissance de l’apprentissage automatique pour construire des solutions de tarification efficaces. Le géant du commerce électronique Amazon a été l’un des premiers à adopter l’apprentissage automatique dans l’optimisation des prix de détail qui a contribué à sa croissance stellaire de 30 milliards en 2008 à environ 1 trillion en 2019.

Image Credit : spd. group
100+ Datasets for Machine Learning Projects Curated Specially For You
La solution du problème d’apprentissage automatique d’optimisation des prix de détail nécessite la formation d’un modèle d’apprentissage automatique capable de fixer automatiquement le prix des produits de la façon dont ils seraient fixés par des humains. Les modèles d’apprentissage automatique d’optimisation des prix de détail prennent en compte les données historiques des ventes, les diverses caractéristiques des produits et d’autres données non structurées comme les images et les informations textuelles pour apprendre les règles de tarification sans intervention humaine, aidant ainsi les détaillants à s’adapter à un environnement de tarification dynamique pour maximiser les revenus sans perdre de marge bénéficiaire. L’algorithme d’apprentissage automatique d’optimisation des prix de détail traite un nombre infini de scénarios de tarification pour sélectionner le prix optimal d’un produit en temps réel en considérant des milliers de relations latentes au sein d’un produit.
Consultez ce projet d’apprentissage automatique cool sur l’optimisation des prix de détail pour une plongée profonde dans l’analyse des données de vente réelles pour un Café où vous construirez une solution d’apprentissage automatique de bout en bout qui suggère automatiquement les bons prix des produits.
13) Analyse de prédiction du taux de désabonnement des clients à l’aide de techniques d’ensemble en apprentissage automatique
Les clients sont le plus grand atout d’une entreprise et la fidélisation des clients est importante pour toute entreprise afin de stimuler les revenus et de construire une relation significative durable avec les clients. De plus, le coût d’acquisition d’un nouveau client est cinq fois plus élevé que celui de la fidélisation d’un client existant. La perte ou l’attrition de la clientèle est l’un des problèmes les plus reconnus dans le monde des affaires, lorsque les clients ou les abonnés cessent de faire affaire avec un service ou une entreprise. Idéalement, ils cessent d’être des clients payants. On dit d’un client qu’il s’est désabonné si un laps de temps spécifique s’est écoulé depuis sa dernière interaction avec l’entreprise.
Identifier si et quand un client va se désabonner et fournir rapidement des informations exploitables visant à fidéliser le client est essentiel pour réduire le désabonnement. Il n’est pas possible pour nos cerveaux d’anticiper le désabonnement de millions de clients, c’est là que l’apprentissage automatique peut aider. L’apprentissage automatique fournit des méthodes efficaces pour identifier les facteurs sous-jacents de la désaffection et des outils proscriptifs pour y remédier. Les algorithmes d’apprentissage automatique jouent un rôle essentiel dans la gestion proactive des désabonnements, car ils révèlent les schémas comportementaux des clients qui ont déjà cessé d’utiliser les services ou d’acheter des produits. Ensuite, les modèles d’apprentissage automatique vérifient le comportement des clients existants par rapport à ces modèles pour identifier les churners potentiels.

Crédit image. :gallery.azure.ai
Mais comment commencer à résoudre le problème d’apprentissage automatique de prédiction du taux de churning des clients ? Comme tout autre problème d’apprentissage automatique, les data scientists ou les ingénieurs en apprentissage automatique doivent collecter et préparer les données à traiter. Pour que toute approche d’apprentissage automatique soit efficace, l’ingénierie des données dans le bon format est logique. L’ingénierie des fonctionnalités est la partie la plus créative du modèle d’apprentissage automatique de prédiction de churn où les spécialistes des données utilisent leur expérience, le contexte commercial, la connaissance du domaine des données et la créativité pour créer des fonctionnalités et adapter le modèle d’apprentissage automatique afin de comprendre pourquoi le churn des clients se produit dans une entreprise spécifique.
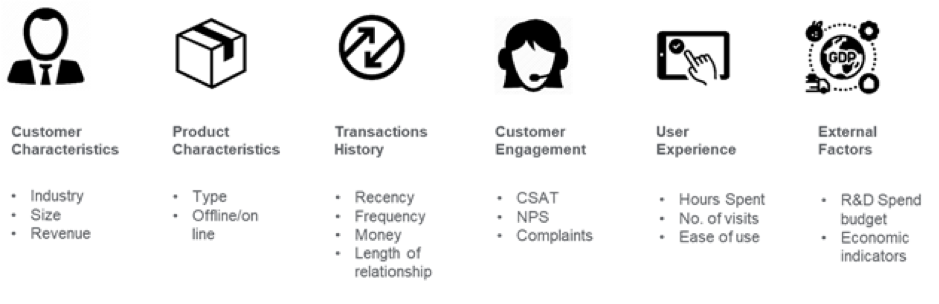
Image Credit : medium.com
Par exemple, dans le secteur bancaire, deux comptes qui ont le même solde de clôture mensuel peuvent être difficiles à différencier pour la prédiction de churn. Mais l’ingénierie des fonctionnalités peut ajouter une dimension temporelle à ces données afin que les algorithmes ML puissent différencier si le solde de clôture mensuel s’est écarté de ce que l’on attend habituellement d’un client. Des indicateurs tels que les comptes dormants, l’augmentation des retraits, les tendances d’utilisation, les sorties nettes de solde au cours des derniers jours peuvent être des signes précurseurs de désabonnement. Ces données internes, combinées à des données externes comme les offres de la concurrence, peuvent aider à prédire le taux de désabonnement. Après avoir identifié les caractéristiques, l’étape suivante consiste à comprendre pourquoi les désabonnements se produisent dans un contexte commercial et à supprimer les caractéristiques qui ne sont pas des prédicteurs forts pour réduire la dimensionnalité.
Voyez ce projet d’apprentissage automatique de bout en bout avec le code source en Python sur l’analyse de prédiction de désabonnement des clients en utilisant l’apprentissage d’ensemble pour combattre le désabonnement.
Comment puis-je commencer un projet d’apprentissage automatique?
Aucun projet n’avance avec succès sans une planification solide, et l’apprentissage automatique ne fait pas exception. Construire votre premier projet d’apprentissage automatique n’est en fait pas aussi difficile qu’il n’y paraît, à condition d’avoir une stratégie de planification solide. Pour démarrer tout projet ML, il faut suivre une approche complète de bout en bout -en commençant par le cadrage du projet jusqu’au déploiement et à la gestion du modèle en production Voici notre prise sur les étapes fondamentales d’un plan de projet d’apprentissage automatique pour s’assurer que vous tirez le meilleur parti de chaque projet unique –
1) Première étape : Délimitation du projet d’apprentissage automatique
Avant toute chose, comprenez quelles sont les exigences commerciales du projet ML. Lors du démarrage d’un projet, sélectionner le cas d’utilisation métier pertinent pour lequel le modèle d’apprentissage automatique sera construit est l’étape fondamentale. Choisir le bon cas d’utilisation de l’apprentissage automatique et évaluer son retour sur investissement est important pour le succès de tout projet d’apprentissage automatique.
2) Deuxième étape : Les données
Les données sont l’élément vital de tout modèle d’apprentissage automatique et il est impossible de former un modèle d’apprentissage automatique sans données. L’étape des données dans le cycle de vie d’un projet d’apprentissage automatique est un processus en quatre étapes –
-
Exigences en matière de données – Il est important de comprendre quel type de données sera nécessaire, le format des données, les sources de données et les exigences de conformité des sources de données.
-
Collecte de données – Avec l’aide des administrateurs de bases de données, des architectes de données ou des développeurs, vous devez mettre en place la stratégie de collecte de données pour extraire les données des endroits où elles vivent au sein de l’organisation ou d’autres fournisseurs tiers.
-
Analyse exploratoire des données – Cette étape consiste essentiellement à valider les besoins en données pour s’assurer que vous avez les bonnes données, que les données sont en bon état et qu’elles sont exemptes d’erreurs.
-
Préparation des données – Cette étape consiste à préparer les données pour qu’elles soient utilisées par les algorithmes d’apprentissage automatique. La correction des erreurs, l’ingénierie des caractéristiques, l’encodage dans des formats de données que les machines peuvent comprendre, et la correction des anomalies sont les tâches impliquées dans la préparation des données.
3) Troisième étape – Construire le modèle
Selon la nature du projet, cette étape peut prendre quelques jours ou quelques mois. Dans l’étape de modélisation, vous prenez une décision sur l’algorithme d’apprentissage automatique à utiliser et commencez à former le modèle sur les données. Il est important de comprendre la mesure de la précision, de l’erreur et de l’exactitude à laquelle un modèle d’apprentissage automatique doit se conformer pour le choix du modèle. Après avoir entraîné le modèle, vous l’évaluez sur des données de validation afin d’analyser ses performances et d’éviter un surajustement. L’évaluation du modèle est une étape critique car si un modèle fonctionne parfaitement avec les données historiques et renvoie des performances médiocres avec les données futures, il n’est d’aucune utilité.
4) Quatrième étape -Déploiement du modèle en production
Cette étape consiste à déployer le logiciel ou l’application aux utilisateurs finaux afin que les nouvelles données puissent affluer dans le modèle d’apprentissage automatique pour un apprentissage supplémentaire. Déployer le modèle d’apprentissage automatique n’est pas suffisant, vous devez également vous assurer que le modèle d’apprentissage automatique fonctionne comme prévu. Vous devez réentraîner votre modèle sur les nouvelles données de production en direct pour garantir sa précision ou ses performances – c’est l’ajustement du modèle. Le réglage du modèle nécessite également de valider le modèle pour s’assurer qu’il ne dérive pas ou ne devient pas biaisé.
Comment mettre des projets d’apprentissage automatique sur votre CV ?
L’expérience du monde réel vous prépare au succès ultime comme rien d’autre. En tant que débutant en apprentissage automatique, plus vous pouvez acquérir une expérience en temps réel en travaillant sur des projets d’apprentissage automatique, plus vous serez prêt à saisir les emplois les plus chauds de la décennie. Obtenir un emploi en apprentissage automatique après avoir suivi une formation en science des données ou réussir en tant que scientifique des données dépendra de votre capacité à vous vendre. Après avoir suivi une formation complète en science des données, l’étape suivante pour décrocher un emploi de premier plan en tant qu’ingénieur en apprentissage automatique ou scientifique des données consiste à constituer un portefeuille exceptionnel afin de montrer votre capacité à appliquer les techniques d’apprentissage automatique à vos employeurs potentiels. Travailler sur des projets intéressants d’apprentissage automatique est un excellent moyen de lancer votre carrière d’ingénieur en apprentissage automatique ou de scientifique des données. Les employeurs veulent voir sur quel type de projets liés à la science des données et à l’apprentissage automatique vous avez travaillé pour évaluer l’étendue de vos capacités en matière de science des données et d’apprentissage automatique. Mettre en avant des exemples de projets de science des données et d’apprentissage automatique amusants, cool et intéressants sur votre CV aura plus de poids que de leur dire combien vous en savez. Voici comment vous pouvez ajouter des projets géniaux à votre CV d’apprentissage automatique –
- Vous pouvez mentionner les projets d’apprentissage automatique juste après votre section d’expérience professionnelle dans le CV d’apprentissage automatique.
- Suivez un ordre séquentiel de numérotation ainsi que le titre des projets sur lesquels vous avez travaillé.
- Le titre du projet devrait être suivi d’une petite brève sur l’ensemble de données et l’énoncé du problème.
- Mentionnez les outils et les technologies d’apprentissage automatique que vous avez utilisés pour mener à bien un projet.
- En dernier lieu, mais non le moindre, dans votre portefeuille / curriculum vitae, liez chaque projet d’apprentissage automatique à GitHub, au site Web personnel ou au blog pour une compréhension approfondie de vos réalisations.
Que vous souhaitiez constituer un solide portefeuille d’apprentissage automatique ou que vous souhaitiez mettre en pratique les compétences analytiques que vous avez apprises dans votre cours de formation en science des données, nous avons tout prévu. De nombreux débutants en apprentissage automatique ne savent pas par où commencer, quels projets d’apprentissage automatique réaliser, quels outils, techniques et cadres d’apprentissage automatique utiliser. Nous avons simplifié la tâche des débutants en science des données et en apprentissage automatique en établissant une liste d’idées intéressantes pour des projets d’apprentissage automatique, ainsi que leurs solutions. Ces idées de projets d’apprentissage automatique sont tirées des défis de science des données populaires de Kaggle et constituent un excellent moyen d’apprendre l’apprentissage automatique. Cette liste de projets est un moyen idéal d’ajouter des projets d’apprentissage automatique à votre CV. Le bon état d’esprit, la volonté d’apprendre et beaucoup d’exploration de données sont tous nécessaires pour comprendre la solution aux projets sur la science des données et l’apprentissage automatique. Vous pouvez explorer 50+ projets de science des données et de ML basés sur l’ensemble des compétences, des outils et des techniques que vous devez apprendre.
Avant de vous lancer dans votre projet, il est utile d’avoir accès à une bibliothèque d’exemples de code de projet d’apprentissage automatique. Ainsi, à chaque fois que vous êtes bloqué sur le projet, vous pouvez utiliser ces exemples résolus pour vous décoincer.
Accéder à la science des données et aux exemples de code de projet d’apprentissage automatique
Quoi ensuite ?
On ne peut devenir un maître de l’apprentissage automatique qu’avec beaucoup de pratique et d’expérimentation. Avoir des connaissances théoriques aide sûrement mais c’est l’application qui permet de progresser le plus. Aucune quantité de connaissances théoriques ne peut remplacer la pratique. Cependant, cela vous aidera si vous vous familiarisez d’abord avec les projets innovants d’apprentissage automatique énumérés ci-dessus.
Si vous êtes un débutant et nouveau à l’apprentissage automatique, alors travailler sur des projets d’apprentissage automatique conçus par des experts de l’industrie à ProjectPro fera certains des meilleurs investissements de votre temps. Ces projets ont été conçus pour les débutants afin de les aider à améliorer rapidement leurs compétences en apprentissage automatique appliqué tout en leur donnant une chance d’explorer des cas d’utilisation commerciale intéressants dans divers domaines – vente au détail, finance, assurance, fabrication, et plus encore. Donc, si vous voulez prendre plaisir à apprendre l’apprentissage machine, rester motivé, et faire des progrès rapides, alors les projets ML intéressants de ProjectPro sont pour vous. De plus, ajoutez ces projets d’apprentissage machine à votre portefeuille et décrochez un gig top avec un salaire plus élevé et des avantages gratifiants.

Cliquez ici pour voir une liste de 50+ solutions de projets résolus, de bout en bout, en apprentissage automatique et en Big Data
|
PREVIOUS |
NEXT |
.