
Par : Aaron Bertrand | Mis à jour : 2019-12-03 | Commentaires (1) | Connexe : Plus de > Performance Tuning
Problème
Il y a plusieurs années, j’ai blogué sur la façon dont vous pouvez réduire l’impact sur le journal des transactions en fractionnant les opérations de suppression en morceaux. Au lieu de supprimer 100 000 lignes dans une grande transaction, vous pouvez supprimer 100 ou 1 000 ou un nombre arbitraire de lignes à la fois, dans plusieurs petites transactions, en boucle. En plus de réduire l’impact sur le journal, vous pouvez soulager les blocages de longue durée. À l’époque, les disques SSD commençaient tout juste à être utilisés et des technologies plus récentes comme les index clusterisés en colonnes, la durabilité retardée et la récupération accélérée des bases de données n’existaient pas encore. J’ai donc pensé qu’il était peut-être temps de rafraîchir la situation pour donner une meilleure image de la façon dont cela se passe dans SQL Server2019.
Solution
Supprimer de grandes parties d’une table n’est pas toujours la seule réponse. Si vous supprimez 95 % d’une table et que vous en conservez 5 %, il peut en fait être plus rapide de déplacer les lignes que vous souhaitez conserver dans une nouvelle table, de supprimer l’ancienne table et de renommer la nouvelle.Ou de copier les lignes conservées, de tronquer la table, puis de les recopier. Mais même lorsque la purge est aussi importante que le maintien, cela n’est pas toujours possible en raison d’autres contraintes sur la table, des SLA et d’autres facteurs.
En outre, s’il s’avère que vous devez supprimer des lignes, vous voudrez minimiser l’impact sur le journal des transactions et la façon dont les opérations affectent le reste de la charge de travail.L’approche de chunking n’est pas une idée nouvelle ou novatrice, mais elle peut bien fonctionner avec certaines de ces technologies plus récentes, alors mettons-les à l’épreuve dans une variété de combinaisons.
Pour mettre en place, nous avons plusieurs constantes qui seront vraies pour chaque test :
- SQL Server 2019 RC1, avec quatre cœurs et 32 Go de RAM (mémoire maximale du serveur =28 Go)
- Table de 10 millions de lignes
- Démarrer SQL Server après chaque test (pour réinitialiser la mémoire, les tampons, et plancache)
- Restaurer une sauvegarde qui avait des stats déjà mises à jour et des stats automatiques désactivées(pour empêcher toute mise à jour de stats déclenchée d’interférer avec les opérations de suppression)
Nous avons également de nombreuses variables qui changeront par test :
Cela produira 864 tests uniques, et vous pouvez croire que je vaisautomatiser toutes ces permutations.
Et les métriques que nous allons mesurer :
- Durée totale
- Utilisation moyenne/pointe du CPU
- Utilisation moyenne/pointe de la mémoire
- Utilisation du journal des transactions/croissance du fichier
- Utilisation du fichier de la base de données, taille du magasin de versions (lors de l’utilisation de Accelerated DatabaseRecovery)
- Taille du groupe de rangées delta (lors de l’utilisation de Columnstore)
Table source
D’abord, j’ai restauré une copie d’AdventureWorks (AdventureWorks2017.bak, pour être précis). Pour créer une table de 10 millions de lignes, j’ai fait une copie de Sales.SalesOrderDetail,avec sa propre colonne d’identité, et j’ai ajouté une colonne de remplissage juste pour donner un peu plus de chair à chaque ligne et réduire la densité de la page:
CREATE TABLE dbo.SalesOrderDetailCopy
(
SalesOrderDetailID int IDENTITY,
SalesOrderID int,
CarrierTrackingNumber nvarchar(25),
OrderQty smallint,
ProductID int,
SpecialOfferID int,
UnitPrice money,
UnitPriceDiscount money,
LineTotal numeric(38,6),
rowguid uniqueidentifier,
ModifiedDate datetime,
filler char(50) NOT NULL DEFAULT ''
);
GO
Puis, pour générer les 10 000 000 de lignes, j’ai inséré 100 000 lignes à la fois, et j’ai fait 100 fois l’insertion :
INSERT dbo.SalesOrderDetailCopy
(
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
)
SELECT TOP(100000)
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
FROM Sales.SalesOrderDetail;GO 100
Je n’ai pas créé d’index sur la table ; selon l’approche de stockage, je créerai un nouvel index clusterisé (columnstore la moitié du temps) après la restauration de la base de données dans le cadre de chaque test.
Automatisation des tests
Une fois que la table de 10 millions de lignes existait, j’ai défini quelques options, sauvegardé la base de données, sauvegardé le journal deux fois, puis sauvegardé à nouveau la base de données (afin que le journal ait le moins d’espace utilisé possible lors de la restauration) :
Puis, j’ai créé une base de données de contrôle, où je stockerai les procédures stockées qui exécuteront les tests, et les tables qui contiendront les résultats des tests (juste l’heure de début et de fin de chaque test) et les mesures de performance capturées tout au long de tous les tests.
Capturer les permutations des 864 tests que je voulais effectuer a pris quelques essais, mais j’ai fini par obtenir ceci :
Comme prévu, cela a inséré 864 lignes avec toutes ces combinaisons.
Puis, j’ai créé une procédure stockée pour capturer l’ensemble des métriques décrites précédemment.Je surveille également l’instance avecSentryOne SQL Sentry, il y aura donc certainement d’autres informations intéressantes disponibles, mais je voulais également capturer les détails importants sans l’utilisation d’outils tiers. Voici la procédure, qui fait tout son possible pour produire toutes les métriques pour n’importe quel horodatage donné dans une seule ligne:
J’ai mis cette procédure stockée dans une étape de travail et je l’ai lancée. Vous pouvez vouloir utiliser un délai autre que trois secondes – il y a un compromis entre le coût de la collecte et l’exhaustivité des données qui peut pencher plus d’un côté que de l’autre pour vous.
Enfin, j’ai créé la procédure qui contiendrait toute la logique pour déterminer exactement ce qu’il faut faire avec la combinaison de paramètres pour chaque test individuel.Cela a encore pris plusieurs itérations, mais le produit final est le suivant:
Il y a beaucoup de choses qui se passent là, mais la logique de base est la suivante:
- Tirer les données spécifiques au test (TestID et tous les paramètres) à partir du dbo.Teststable
- Donner un coup de pied à SQL Server en faisant un changement sp_configure et en vidant les tamponset le cache du plan
- Restaurer une copie propre d’AdventureWorks, avec les 10 millions de lignes intactes,et sans index
- Changer les options de la base de données en fonction des paramètres du test en cours
- Créer un index clusterisé columnstore ou un index clusterisé B-tree
- Mettre à jour les stats de la table manuellement, juste pour être sûr
- Loguer que nous avons commencé le test
- Déterminer combien d’itérations de la boucle nous avons besoin, et combien de lignes à supprimer à l’intérieur de chaque itération
- Dans la boucle :
- Déterminer si nous devons commencer une transaction sur cette itération
- Exécuter la suppression
- Déterminer si nous devons commettre la transaction sur cette itération
- Déterminer si nous devons vérifier / sauvegarder le journal sur cette itération
- Après la boucle, nous enregistrons que ce test est terminé, et engageons toutes les transactions non engagées
Pour exécuter réellement le test, je ne veux pas le faire dans Management Studio(même sur la même VM), à cause de toute la sortie, du trafic supplémentaire et de l’utilisation des ressources.J’ai créé une procédure stockée et mis cela dans un travail également:
Cela a pris beaucoup plus de temps que je suis à l’aise pour l’admettre. Une partie de cela était parce que j’avais initialement inclus un test de 0,1% pour rowperloopqui, dans certains cas, prenait plusieurs heures. J’ai donc retiré ces tests du tableau quelques jours plus tard, et je peux facilement dire que si vous supprimez 1 000 000 de lignes, il est très peu probable que la suppression de 1 000 lignes à la fois soit un choix optimal, quelles que soient les autres variables :

(Bien que cela semble être une anomalie par rapport à la plupart des autres tests, je parie que cela ne serait pas beaucoup plus rapide que la suppression d’une ligne ou de 10 lignes à la fois. Et en fait, c’était plus lent que de supprimer la moitié de la table ou la plus grande partie de la table dans tous les autres scénarios.)
Résultats de performance
Après avoir écarté les résultats des tests de 0,1%, j’ai mis le reste dans une seconde table de métrique avec les durées chargées:
J’ai dû utiliser une jointure externe sur la table de métrique parce que certains tests se sont exécutés si rapidement qu’il n’y avait pas assez de temps pour capturer des données. Cela signifie que, pour certains des tests les plus rapides, il n’y aura pas de corrélation avec d’autres détails de performance autres que leur vitesse d’exécution.
J’ai ensuite commencé à chercher des tendances et des anomalies. Tout d’abord, j’ai vérifié la durée et le CPU en fonction de l’activation de la durabilité retardée (DD) et/ou de la récupération accélérée de la base de données (ADR) :
Résultats (avec les anomalies mises en évidence) :

Il semble que la durée globale soit améliorée, en moyenne, d’environ la même quantité, lorsque l’une ou l’autre option est activée (ou les deux – et lorsque les deux sont activées, le pic est plus bas). Il semble qu’il y ait une durée aberrante pour ADR seul qui n’a pas affecté la moyenne (ce test spécifique impliquait la suppression de 9 000 000 lignes, 90 000 lignes à la fois, en récupération complète, sur une table rowstore). La valeur aberrante du CPU pour DD n’a pas non plus affecté la moyenne – cet exemple spécifique consistait à supprimer 1 000 000 de lignes, en une seule fois, sur une table columnstore.
Qu’en est-il des différences globales comparant rowstore et columnstore ?
Résultats:

Columnstore est 20% plus lent, en moyenne, mais a nécessité moins de mémoire. Je voulais également voir l’impact sur la taille et l’utilisation des fichiers de données et des fichiers journaux :
Résultats:

Enfin, sur le matériel actuel, la suppression par morceaux ne semble pas avoir les mêmes avantages qu’autrefois, du moins en termes de durée. Les 18 résultats les plus rapides ici, et 72 des 100 plus rapides, étaient des tests où toutes les lignes étaient supprimées en une seule fois, révélés par cette requête:
Résultats:
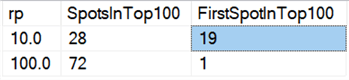
Et si nous regardons les moyennes sur toutes les données, comme dans cette requête :
Nous voyons que la suppression de toutes les lignes en une seule fois, que nous supprimions10%, 50% ou 90%, est plus rapide que le chunking des suppressions de quelque manière que ce soit (encore une fois, en moyenne):
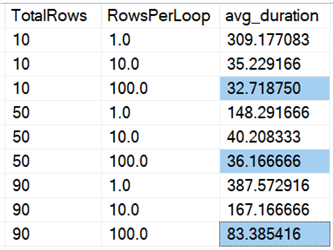
Sous forme de graphique:
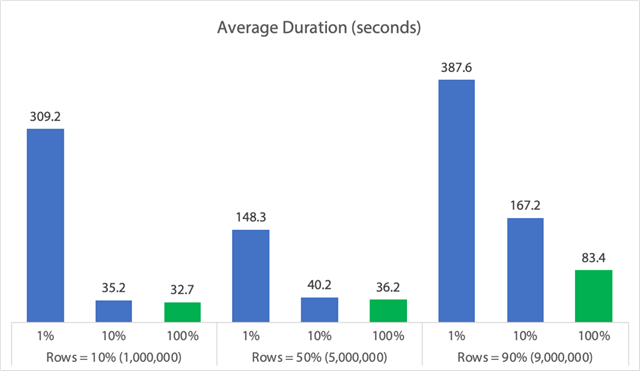
(Notez que si nous retirons le 6,062 secondes max_durationoutlier identifié plus tôt, cette première colonne tombe de 309 secondes à 162 secondes.)
Maintenant, même dans le meilleur des cas, cela fait toujours 33, 36 ou 83 secondes où l’adelete est en cours d’exécution et bloque potentiellement tout le monde, et cela ignore les autres impacts mesurés comme la mémoire, le fichier journal, le CPU, et ainsi de suite. La durée ne devrait certainement pas être votre seul critère ; il se trouve simplement que c’est généralement la première (et parfois la seule) chose que les gens regardent. Ce harnais de test avait pour but de montrer que vous pouvez et devriez capturer plusieurs autres métriques, aussi, et les résultats montrent que les valeurs aberrantes peuvent venir de n’importe où.
En utilisant ce harnais comme modèle, vous pouvez construire vos propres tests axés plus étroitement sur les contraintes et les capacités de votre environnement. Je n’ai pas attaqué les métriques sous tous les angles possibles, car cela fait beaucoup de permutations, mais je vais garder cette base de données. Donc, s’il y a d’autres façons dont vous voulez voir les données découpées, faites-le moi savoir dans les commentaires ci-dessous, et je verrai ce que je peux faire. Mais ne me demandez pas de refaire tous les tests.
Caveats
Tout cela ne tient pas compte d’une charge de travail simultanée, de l’impact des contraintes de table comme les clés étrangères, de la présence de déclencheurs, et d’une foule d’autres scénarios possibles.Une autre chose à tester (potentiellement dans une prochaine astuce) est d’avoir plusieurs emplois qui interagissent avec cette même table tout au long de l’opération, et de mesurer des choses comme les durées de blocage, les types et les temps d’attente, et de jauger dans quelles situations un setof activité a un impact plus dramatique sur l’autre set.
Prochaines étapes
Lisez la suite pour des conseils connexes et d’autres ressources :
- Opérations CRUD dans SQL Server
- Différences entre supprimer et tronquer dans SQL Server
- Supprimer des données historiques d’une grande table de base de données SQL Server hautement concurrente
- Casser les grandes opérations de suppression en morceaux
- Exemple d’index Columnstore clusterisé et non clusterisé de SQL Server
- Durabilité retardée dans SQL Server 2014
- Durabilité retardée pendant la purge des données
- Recupération accélérée des bases de données dans SQL Server 2019
.
Dernière mise à jour : 2019-12-03


A propos de l’auteur
 Aaron Bertrand (@AaronBertrand) est un technologue passionné dont l’expérience dans l’industrie remonte à Classic ASP et SQL Server 6.5. Il est rédacteur en chef du blogue sur la performance, SQLPerformance.com, et blogue également sur sqlblog.org.
Aaron Bertrand (@AaronBertrand) est un technologue passionné dont l’expérience dans l’industrie remonte à Classic ASP et SQL Server 6.5. Il est rédacteur en chef du blogue sur la performance, SQLPerformance.com, et blogue également sur sqlblog.org.Voir tous mes conseils
- Plus de conseils pour DBA SQL Server…
.