
- Zugang zu Top ML Projekten erhalten
- Maschinenlernprojekte für Anfänger im Jahr 2021
- Verkaufsprognose mit Walmart-Datensatz
- BigMart-Verkaufsprognose ML-Projekt
- Musikempfehlungssystem Projekt
- Human Activity Recognition using Smartphone Dataset
- Stock Prices Predictor using TimeSeries
- Predicting Wine Quality using Wine Quality Dataset
- MNIST Klassifizierung handgeschriebener Ziffern
- Erlernen der Erstellung von Empfehlungssystemen mit dem Movielens-Datensatz
- Boston Housing Price Prediction ML Project
- Social Media Sentiment Analysis using Twitter Datensatz
- ML-Projekt zur Klassifizierung von Irisblüten
- Preisoptimierung im Einzelhandel mithilfe von maschinellem Lernen
- Analyse zur Vorhersage der Kundenabwanderung
- 1. Umsatzprognose mit dem Walmart-Datensatz
- 2. BigMart Sales Prediction ML Project – Erfahren Sie mehr über unüberwachte maschinelle Lernalgorithmen
- Music Recommendation System Project
- Human Activity Recognition using Smartphone Dataset
- Börsenkursvorhersage mit Zeitreihen
- Vorhersage der Weinqualität anhand des Weinqualitätsdatensatzes
- MNIST Handwritten Digit Classification
- Learn to build Recommender Systems with Movielens Dataset
- Boston Housing Price Prediction ML Project
- Social Media Sentiment Analysis using Twitter Dataset
- Iris Flowers Klassifizierungs-ML-Projekt – Lernen Sie über überwachte Machine Learning-Algorithmen
- Machine Learning Projects for Beginners with Source Code in Python for 2021
- 12) Retail Price Optimization ML Project – Dynamic Pricing Machine Learning Model for a Dynamic Market
- 13) Customer Churn Prediction Analysis Using Ensemble Techniques in Machine Learning
- Wie beginne ich ein Projekt für maschinelles Lernen?
- 1) Erster Schritt: Scoping des Projekts für maschinelles Lernen
- 2) Zweiter Schritt: Daten
- 3) Dritter Schritt – Erstellung des Modells
- 4) Vierter Schritt – Bereitstellung des Modells in der Produktion
- Wie können Sie Projekte zum maschinellen Lernen in Ihren Lebenslauf aufnehmen?
- Wie geht es weiter?
Zugang zu Top ML Projekten erhalten
×
Zuletzt aktualisiert: 05 Mar 2021

Sie wollen maschinelles Lernen lernen, haben aber Schwierigkeiten, damit anzufangen. Bücher und Kurse reichen nicht aus, wenn es um maschinelles Lernen geht, obwohl sie immer Beispielcodes und -schnipsel für maschinelles Lernen enthalten, erhalten Sie keine Gelegenheit, maschinelles Lernen auf reale Probleme anzuwenden und zu sehen, wie diese Codeschnipsel zusammenpassen. Der beste Weg, um mit dem maschinellen Lernen zu beginnen, ist die Implementierung von Projekten für Anfänger und Fortgeschrittene im Bereich des maschinellen Lernens. Es ist immer hilfreich, Einblicke zu erhalten, wie echte Menschen ihre Karriere im Bereich des maschinellen Lernens beginnen, indem sie End-to-End-ML-Projekte implementieren.
In diesem Blog-Beitrag erfahren Sie, wie Anfänger wie Sie große Fortschritte bei der Anwendung des maschinellen Lernens auf reale Probleme mit diesen fantastischen maschinellen Lernprojekten für Anfänger machen können, die von Branchenexperten empfohlen werden. Die Branchenexperten von ProjectPro haben sorgfältig eine Liste der besten Projekte zum maschinellen Lernen für Anfänger zusammengestellt, die die wichtigsten Aspekte des maschinellen Lernens wie überwachtes Lernen, unüberwachtes Lernen, Deep Learning und neuronale Netze abdecken. Bei all diesen Projekten zum maschinellen Lernen werden Sie mit realen Datensätzen beginnen, die öffentlich zugänglich sind. Wir versichern Ihnen, dass Sie diesen Blog absolut interessant und lesenswert finden werden, weil Sie hier alles über die beliebtesten Projekte zum maschinellen Lernen erfahren können.
„Welche Projekte kann ich mit maschinellem Lernen durchführen?“ Diese Frage wird uns oft von Anfängern gestellt, die mit dem maschinellen Lernen beginnen. Die Branchenexperten von ProjectPro empfehlen Ihnen, einige spannende, coole, lustige und einfache Projektideen für maschinelles Lernen in verschiedenen Geschäftsbereichen zu erkunden, um praktische Erfahrungen mit den erlernten Fähigkeiten des maschinellen Lernens zu sammeln. Wir haben eine Liste innovativer und interessanter Projekte zum maschinellen Lernen mit Quellcode für Fachleute zusammengestellt, die ihre Karriere im maschinellen Lernen beginnen. Diese Einsteigerprojekte zum maschinellen Lernen sind eine perfekte Mischung aus verschiedenen Arten von Herausforderungen, denen man bei der Arbeit als Ingenieur für maschinelles Lernen oder Datenwissenschaftler begegnen kann.
Maschinenlernprojekte für Anfänger im Jahr 2021
-
Verkaufsprognose mit Walmart-Datensatz
-
BigMart-Verkaufsprognose ML-Projekt
-
Musikempfehlungssystem Projekt
-
Human Activity Recognition using Smartphone Dataset
-
Stock Prices Predictor using TimeSeries
-
Predicting Wine Quality using Wine Quality Dataset
-
MNIST Klassifizierung handgeschriebener Ziffern
-
Erlernen der Erstellung von Empfehlungssystemen mit dem Movielens-Datensatz
-
Boston Housing Price Prediction ML Project
-
Social Media Sentiment Analysis using Twitter Datensatz
-
ML-Projekt zur Klassifizierung von Irisblüten
-
Preisoptimierung im Einzelhandel mithilfe von maschinellem Lernen
-
Analyse zur Vorhersage der Kundenabwanderung
Lassen Sie uns eintauchen!

1. Umsatzprognose mit dem Walmart-Datensatz
Die Umsatzprognose ist einer der häufigsten Anwendungsfälle des maschinellen Lernens, um Faktoren zu ermitteln, die sich auf den Umsatz eines Produkts auswirken, und um das künftige Umsatzvolumen zu schätzen. In diesem Projekt zum maschinellen Lernen wird der Walmart-Datensatz verwendet, der Verkaufsdaten für 98 Produkte in 45 Verkaufsstellen enthält. Der Datensatz enthält die Verkäufe pro Geschäft und pro Abteilung auf wöchentlicher Basis. Das Ziel dieses maschinellen Lernprojekts ist es, den Umsatz für jede Abteilung in jeder Filiale zu prognostizieren, um bessere datengestützte Entscheidungen für die Optimierung der Vertriebskanäle und die Bestandsplanung zu treffen. Die Herausforderung bei der Arbeit mit dem Walmart-Datensatz besteht darin, dass er ausgewählte Rabattaktionen enthält, die sich auf den Umsatz auswirken und berücksichtigt werden sollten.
Dies ist eines der einfachsten und coolsten Projekte im Bereich des maschinellen Lernens, bei dem du ein Vorhersagemodell mit dem Walmart-Datensatz erstellst, um die Anzahl der Verkäufe in der Zukunft abzuschätzen, und zwar wie folgt –
- Importiere die Daten und untersuche sie, um die Struktur und die Werte innerhalb der Daten zu verstehen – Beginne mit dem Import einer CSV-Datei und führe eine grundlegende explorative Datenanalyse (EDA) durch.
- Daten für die Modellierung vorbereiten – Mehrere Datensätze zusammenführen und die Funktion „Gruppieren nach“ anwenden, um die Daten zu analysieren.
- Eine Zeitreihengrafik erstellen und analysieren.
- Die entwickelten Absatzprognosemodelle an die Trainingsdaten anpassen- Ein ARIMA-Modell für Zeitreihenprognosen erstellen
- Die entwickelten Modelle mit den Testdaten vergleichen.
- Die Absatzprognosemodelle durch die Auswahl wichtiger Merkmale optimieren, um die Genauigkeit zu verbessern.
- Nutzen Sie das beste maschinelle Lernmodell, um die Umsätze des nächsten Jahres vorherzusagen.
Nach der Arbeit an diesem Kaggle-Projekt zum maschinellen Lernen werden Sie verstehen, wie leistungsstarke maschinelle Lernmodelle den gesamten Prozess der Umsatzprognose vereinfachen können. Verwenden Sie diese durchgängigen maschinellen Lernmodelle zur Umsatzprognose in der Produktion, um den Umsatz für jede Abteilung oder jedes Einzelhandelsgeschäft zu prognostizieren.
Möchten Sie mit dem Walmart-Datensatz arbeiten? Greifen Sie hier auf die vollständige Lösung für dieses großartige maschinelle Lernprojekt zu – Walmart Store Sales Forecasting Machine Learning Project
2. BigMart Sales Prediction ML Project – Erfahren Sie mehr über unüberwachte maschinelle Lernalgorithmen
Der BigMart-Verkaufsdatensatz besteht aus Verkaufsdaten aus dem Jahr 2013 für 1559 Produkte in 10 verschiedenen Filialen in verschiedenen Städten. Das Ziel des BigMart-Verkaufsvorhersage-ML-Projekts ist die Erstellung eines Regressionsmodells zur Vorhersage der Verkäufe jedes der 1559 Produkte für das folgende Jahr in jeder der 10 verschiedenen BigMart-Filialen. Der BigMart-Verkaufsdatensatz besteht auch aus bestimmten Attributen für jedes Produkt und jede Filiale. Dieses Modell hilft BigMart, die Eigenschaften von Produkten und Geschäften zu verstehen, die eine wichtige Rolle bei der Steigerung des Gesamtumsatzes spielen.
Zugriff auf die vollständige Lösung für dieses ML-Projekt hier – BigMart Sales Prediction Machine Learning Project Solution
Music Recommendation System Project
Dies ist eines der beliebtesten Machine-Learning-Projekte und kann in verschiedenen Bereichen verwendet werden. Sie sind vielleicht mit einem Empfehlungssystem vertraut, wenn Sie eine E-Commerce-Website oder eine Film-/Musik-Website genutzt haben. Auf den meisten E-Commerce-Websites wie Amazon empfiehlt das System zum Zeitpunkt der Kaufabwicklung Produkte, die in den Warenkorb gelegt werden können. Ähnlich verhält es sich bei Netflix oder Spotify: Basierend auf den Filmen, die Ihnen gefallen haben, werden ähnliche Filme oder Songs angezeigt, die Ihnen gefallen könnten. Wie macht das System das? Dies ist ein klassisches Beispiel für die Anwendung von maschinellem Lernen.
In diesem Projekt verwenden wir den Datensatz von Asiens führendem Musik-Streaming-Dienst, um ein besseres Musikempfehlungssystem zu entwickeln. Wir werden versuchen zu bestimmen, welcher neue Song oder welcher neue Künstler einem Hörer gefallen könnte, basierend auf seinen früheren Entscheidungen. Die Hauptaufgabe besteht darin, die Wahrscheinlichkeit vorherzusagen, dass ein Nutzer ein Lied innerhalb eines bestimmten Zeitraums wiederholt anhört. Im Datensatz wird die Vorhersage als 1 markiert, wenn der Nutzer denselben Song innerhalb eines Monats angehört hat. Der Datensatz besteht daraus, welches Lied von welchem Benutzer zu welcher Zeit gehört wurde.
Wollen Sie ein Empfehlungssystem aufbauen – sehen Sie sich dieses gelöste ML-Projekt hier an – Music Recommendation Machine Learning Project
Human Activity Recognition using Smartphone Dataset
Der Smartphone-Datensatz besteht aus Fitness-Aktivitätsaufzeichnungen von 30 Personen, die mit einem Smartphone mit Inertialsensoren erfasst wurden. Ziel dieses Projekts zum maschinellen Lernen ist es, ein Klassifizierungsmodell zu erstellen, das die Fitnessaktivitäten von Menschen genau identifizieren kann. Die Arbeit an diesem Projekt zum maschinellen Lernen wird Ihnen helfen zu verstehen, wie man Probleme der Mehrfachklassifizierung löst.
Hier erhalten Sie Zugang zum Quellcode dieses ML-Projekts Human Activity Recognition using Smartphone Dataset Project
Klicken Sie hier, um eine Liste von 50+ gelösten, End-to-End-Big-Data- und Machine-Learning-Projektlösungen (wiederverwendbarer Code + Videos)
Börsenkursvorhersage mit Zeitreihen
Dies ist eine weitere interessante Machine-Learning-Projektidee für Datenwissenschaftler/Machine-Learning-Ingenieure, die im Finanzbereich arbeiten oder arbeiten wollen. Ein System zur Vorhersage von Aktienkursen lernt über die Leistung eines Unternehmens und sagt zukünftige Aktienkurse voraus. Die Herausforderungen bei der Arbeit mit Aktienkursdaten bestehen darin, dass sie sehr granular sind und außerdem verschiedene Datentypen wie Volatilitätsindizes, Preise, globale makroökonomische Indikatoren, Fundamentalindikatoren und vieles mehr enthalten. Ein Vorteil der Arbeit mit Börsendaten ist, dass die Finanzmärkte kürzere Rückkopplungszyklen haben, was es Datenexperten erleichtert, ihre Vorhersagen anhand neuer Daten zu validieren. Um mit Börsendaten zu arbeiten, können Sie ein einfaches Problem des maschinellen Lernens aufgreifen, wie z. B. die Vorhersage von 6-monatigen Kursbewegungen auf der Grundlage von Fundamentalindikatoren aus dem Quartalsbericht eines Unternehmens. Sie können Börsendatensätze von Quandl.com oder Quantopian.com herunterladen. Es gibt verschiedene Zeitreihenprognosemethoden zur Vorhersage von Aktienkursen, Nachfrage usw.
Schauen Sie sich dieses Projekt zum maschinellen Lernen an, in dem Sie anhand eines Beispiels für Zeitreihenprognosen lernen, welche Prognosemethode wann und wie angewandt werden sollte. Stock Prices Predictor using TimeSeries Project
Vorhersage der Weinqualität anhand des Weinqualitätsdatensatzes
Es ist eine bekannte Tatsache, dass der Wein umso besser schmeckt, je älter er ist. Neben dem Alter gibt es jedoch noch weitere Faktoren, die bei der Zertifizierung der Weinqualität eine Rolle spielen. Dazu gehören physiochemische Tests wie Alkoholgehalt, feste Säure, flüchtige Säure, Bestimmung der Dichte, pH-Wert und vieles mehr. Das Hauptziel dieses Projekts zum maschinellen Lernen ist die Entwicklung eines maschinellen Lernmodells zur Vorhersage der Qualität von Weinen durch die Erforschung ihrer verschiedenen chemischen Eigenschaften. Der Weinqualitätsdatensatz besteht aus 4898 Beobachtungen mit 11 unabhängigen und 1 abhängigen Variablen.
Hier erhalten Sie Zugriff auf die vollständige Lösung dieses maschinellen Lernprojekts – Wine Quality Prediction in R
MNIST Handwritten Digit Classification
Deep Learning und neuronale Netze spielen eine wichtige Rolle bei der Bilderkennung, der automatischen Texterstellung und sogar bei selbstfahrenden Autos. Um mit der Arbeit in diesen Bereichen zu beginnen, muss man mit einem einfachen und überschaubaren Datensatz wie dem MNIST-Datensatz beginnen. Die Arbeit mit Bilddaten ist schwieriger als die Arbeit mit flachen relationalen Daten, und wir schlagen vor, dass Sie als Anfänger die MNIST Handwritten Digit Classification Challenge in Angriff nehmen und lösen. Der MNIST-Datensatz ist zu klein, um in den PC-Speicher zu passen, und anfängerfreundlich. Die Erkennung handgeschriebener Ziffern wird Sie jedoch herausfordern.
Machen Sie Ihren klassischen Einstieg in die Lösung von Bilderkennungsproblemen, indem Sie hier auf die vollständige Lösung zugreifen – MNIST Handwritten Digit Classification Project
Learn to build Recommender Systems with Movielens Dataset
Von Netflix bis Hulu hat die Notwendigkeit, ein effizientes Filmempfehlungssystem zu entwickeln, im Laufe der Zeit an Bedeutung gewonnen, da die Nachfrage der modernen Verbraucher nach maßgeschneiderten Inhalten steigt. Einer der beliebtesten Datensätze, der im Internet für Anfänger zur Verfügung steht, um den Aufbau von Empfehlungssystemen zu erlernen, ist der Movielens-Datensatz, der etwa 1.000.209 Filmbewertungen von 3.900 Filmen enthält, die von 6.040 Movielens-Nutzern abgegeben wurden. Sie können mit diesem Datensatz arbeiten, indem Sie eine World-Cloud-Visualisierung von Filmtiteln erstellen, um ein Film-Empfehlungssystem zu entwickeln.
Kostenlosen Zugang zu gelösten Code-Beispielen finden Sie hier (diese sind sofort für Ihre ML-Projekte verwendbar)
Boston Housing Price Prediction ML Project
Boston House Prices Dataset besteht aus Preisen von Häusern an verschiedenen Orten in Boston. Der Datensatz enthält auch Informationen über Bereiche, in denen keine Einzelhandelsgeschäfte betrieben werden (INDUS), die Kriminalitätsrate (CRIM), das Alter der Hausbesitzer (AGE) und verschiedene andere Attribute (der Datensatz umfasst insgesamt 14 Attribute). Der Boston Housing-Datensatz kann vom UCI Machine Learning Repository heruntergeladen werden. Das Ziel dieses Projekts für maschinelles Lernen ist die Vorhersage des Verkaufspreises eines neuen Hauses durch die Anwendung grundlegender Konzepte des maschinellen Lernens auf die Wohnungspreisdaten. Dieser Datensatz ist mit 506 Beobachtungen zu klein und wird als guter Start für Anfänger im maschinellen Lernen angesehen, um ihre praktischen Übungen zu Regressionskonzepten zu beginnen.
Lesetipp – 15+ Data Science-Projekte für Anfänger
Social Media Sentiment Analysis using Twitter Dataset
Social Media-Plattformen wie Twitter, Facebook, YouTube, Reddit generieren riesige Mengen an Big Data, die auf verschiedene Weise ausgewertet werden können, um Trends, öffentliche Stimmungen und Meinungen zu verstehen. Daten aus den sozialen Medien sind heute für Markenbildung, Marketing und Unternehmen insgesamt relevant geworden. Ein Sentiment-Analysator lernt durch maschinelles Lernen die verschiedenen Stimmungen hinter einem „Inhaltsstück“ (z. B. einer IM, einer E-Mail, einem Tweet oder einem anderen Social-Media-Beitrag) kennen und trifft mithilfe von KI Vorhersagen.Twitter-Daten gelten als definitiver Einstiegspunkt für Anfänger, um Probleme des maschinellen Lernens bei der Sentiment-Analyse zu üben. Mithilfe des Twitter-Datensatzes kann man eine fesselnde Mischung aus Tweet-Inhalten und anderen zugehörigen Metadaten wie Hashtags, Retweets, Standort, Nutzer und mehr erhalten, die den Weg für eine aufschlussreiche Analyse ebnen. Der Twitter-Datensatz besteht aus 31.962 Tweets und ist 3 MB groß. Mithilfe von Twitter-Daten können Sie herausfinden, was die Welt zu einem Thema sagt, sei es zu Filmen, zur Stimmung bei den US-Wahlen oder zu einem anderen Trendthema, wie z. B. der Vorhersage, wer die FIFA Fußball-Weltmeisterschaft 2018 gewinnen wird. Die Arbeit mit dem Twitter-Datensatz wird Ihnen helfen, die Herausforderungen zu verstehen, die mit dem Social Media Data Mining verbunden sind, und Sie können sich auch eingehend mit Klassifikatoren vertraut machen. Das wichtigste Problem, an dem Sie als Anfänger arbeiten können, ist der Aufbau eines Modells zur Klassifizierung von Tweets als positiv oder negativ.
Kostenlosen Zugang zu gelösten Code-Python- und R-Beispielen finden Sie hier (diese sind sofort für Ihre Data Science- und ML-Projekte einsetzbar)
Iris Flowers Klassifizierungs-ML-Projekt – Lernen Sie über überwachte Machine Learning-Algorithmen
Dies ist eines der einfachsten Machine Learning-Projekte, wobei Iris Flowers der einfachste Machine Learning-Datensatz in der Klassifizierungsliteratur ist. Dieses Problem des maschinellen Lernens wird oft als die „Hello World“ des maschinellen Lernens bezeichnet. Der Datensatz hat numerische Attribute und ML-Anfänger müssen herausfinden, wie man Daten lädt und verarbeitet. Der Iris-Datensatz ist so klein, dass er leicht in den Speicher passt und keine speziellen Transformationen oder Skalierungen erfordert.
Der Iris-Datensatz kann vom UCI ML Repository heruntergeladen werden – Download Iris Flowers Dataset
Das Ziel dieses maschinellen Lernprojekts ist es, die Blumen anhand der Länge und Breite der Blütenblätter und Kelchblätter in die drei Arten virginica, setosa oder versicolor zu klassifizieren.
Kostenlosen Zugang zu gelösten Machine Learning Python- und R-Code-Beispielen finden Sie hier (diese sind gebrauchsfertig für Ihre Projekte)
Machine Learning Projects for Beginners with Source Code in Python for 2021
12) Retail Price Optimization ML Project – Dynamic Pricing Machine Learning Model for a Dynamic Market
Die Preiswettkämpfe wachsen unaufhörlich in allen vertikalen Branchen und die Optimierung der Preise ist der Schlüssel zur effizienten Verwaltung der Gewinne für jedes Unternehmen. Die Ermittlung einer angemessenen Preisspanne und die Anpassung der Produktpreise, um den Umsatz zu steigern und gleichzeitig die Gewinnspannen optimal zu halten, war schon immer eine große Herausforderung für den Einzelhandel. Der schnellste Weg, wie Einzelhändler heute den höchsten ROI sicherstellen und gleichzeitig die Preisgestaltung optimieren können, besteht darin, die Möglichkeiten des maschinellen Lernens zu nutzen, um effektive Preisgestaltungslösungen zu entwickeln. Der E-Commerce-Gigant Amazon war einer der ersten Anwender des maschinellen Lernens bei der Preisoptimierung im Einzelhandel, was zu seinem rasanten Wachstum von 30 Milliarden im Jahr 2008 auf rund 1 Billion im Jahr 2019 beigetragen hat.

Image Credit: spd. group
100+ Datensätze für Machine Learning-Projekte speziell für Sie kuratiert
Die Lösung des Problems der Preisoptimierung im Einzelhandel durch maschinelles Lernen erfordert das Training eines maschinellen Lernmodells, das in der Lage ist, Produkte automatisch so zu bepreisen, wie sie von Menschen bepreist werden würden. Modelle für maschinelles Lernen zur Preisoptimierung im Einzelhandel nehmen historische Verkaufsdaten, verschiedene Merkmale der Produkte und andere unstrukturierte Daten wie Bilder und Textinformationen auf, um die Preisbildungsregeln ohne menschliches Eingreifen zu erlernen und den Einzelhändlern dabei zu helfen, sich an ein dynamisches Preisbildungsumfeld anzupassen, um den Umsatz zu maximieren, ohne dabei Gewinnspannen zu verlieren. Der Algorithmus für maschinelles Lernen zur Preisoptimierung im Einzelhandel verarbeitet eine unendliche Anzahl von Preisszenarien, um den optimalen Preis für ein Produkt in Echtzeit auszuwählen, indem er Tausende von latenten Beziehungen innerhalb eines Produkts berücksichtigt.
Sehen Sie sich dieses coole Projekt für maschinelles Lernen zur Preisoptimierung im Einzelhandel an, um einen tiefen Einblick in die Analyse von realen Verkaufsdaten für ein Café zu erhalten, in dem Sie eine End-to-End-Lösung für maschinelles Lernen erstellen, die automatisch die richtigen Produktpreise vorschlägt.
13) Customer Churn Prediction Analysis Using Ensemble Techniques in Machine Learning
Kunden sind das größte Kapital eines Unternehmens, und die Bindung von Kunden ist für jedes Unternehmen wichtig, um den Umsatz zu steigern und eine langfristige, sinnvolle Beziehung zu Kunden aufzubauen. Außerdem sind die Kosten für die Gewinnung eines neuen Kunden fünfmal höher als die für die Bindung eines bestehenden Kunden. Kundenabwanderung ist eines der bekanntesten Probleme in der Wirtschaft, bei dem Kunden oder Abonnenten aufhören, mit einer Dienstleistung oder einem Unternehmen Geschäfte zu machen. Im Idealfall hören sie auf, ein zahlender Kunde zu sein. Ein Kunde gilt als abgewandert, wenn seit der letzten Interaktion mit dem Unternehmen eine bestimmte Zeitspanne verstrichen ist.
Um die Abwanderung zu verringern, ist es entscheidend, zu erkennen, ob und wann ein Kunde abwandern wird, und schnell umsetzbare Informationen zur Kundenbindung zu liefern. Für unser Gehirn ist es nicht möglich, die Abwanderung von Millionen von Kunden im Voraus zu erkennen; hier kann maschinelles Lernen helfen. Das maschinelle Lernen bietet wirksame Methoden zur Identifizierung der der Abwanderung zugrunde liegenden Faktoren und aussagekräftige Tools für deren Behebung. Algorithmen des maschinellen Lernens spielen eine wichtige Rolle beim proaktiven Abwanderungsmanagement, da sie Verhaltensmuster von Kunden aufdecken, die bereits aufgehört haben, Dienstleistungen zu nutzen oder Produkte zu kaufen. Anschließend vergleichen die maschinellen Lernmodelle das Verhalten der bestehenden Kunden mit diesen Mustern, um potenzielle Abwanderer zu identifizieren.

Bildnachweis: :gallery.azure.ai
Aber wie beginnt man mit der Lösung des Problems des maschinellen Lernens zur Vorhersage der Kundenabwanderungsrate? Wie bei jedem anderen maschinellen Lernproblem müssen Datenwissenschaftler oder Ingenieure für maschinelles Lernen die Daten sammeln und für die Verarbeitung vorbereiten. Damit ein maschineller Lernansatz effektiv ist, ist es sinnvoll, die Daten im richtigen Format aufzubereiten. Das Feature-Engineering ist der kreativste Teil des maschinellen Lernmodells zur Vorhersage von Kundenabwanderung, bei dem Datenspezialisten ihre Erfahrung, ihren geschäftlichen Kontext, ihr Fachwissen über die Daten und ihre Kreativität einsetzen, um Features zu erstellen und das maschinelle Lernmodell so anzupassen, dass es versteht, warum Kundenabwanderung in einem bestimmten Unternehmen auftritt.
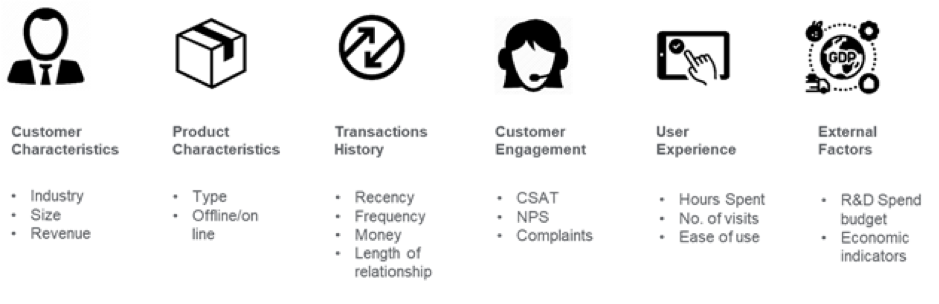
Bildnachweis: medium.com
Im Bankensektor kann es beispielsweise schwierig sein, zwei Konten, die denselben monatlichen Abschlusssaldo aufweisen, für die Vorhersage von Kundenabwanderung zu unterscheiden. Mit Hilfe von Feature Engineering kann diesen Daten jedoch eine zeitliche Dimension hinzugefügt werden, so dass ML-Algorithmen unterscheiden können, ob der monatliche Abschlusssaldo von dem abweicht, was normalerweise von einem Kunden erwartet wird. Indikatoren wie ruhende Konten, zunehmende Abhebungen, Nutzungstrends, Nettoguthabenabfluss in den letzten Tagen können Frühwarnzeichen für Abwanderung sein. Diese internen Daten in Kombination mit externen Daten wie Angeboten von Wettbewerbern können helfen, die Kundenabwanderung vorherzusagen. Nachdem die Merkmale identifiziert wurden, besteht der nächste Schritt darin, zu verstehen, warum Kundenabwanderungen in einem geschäftlichen Kontext auftreten, und die Merkmale zu entfernen, die keine starken Prädiktoren sind, um die Dimensionalität zu reduzieren.
Sehen Sie sich dieses End-to-End-Projekt für maschinelles Lernen mit Quellcode in Python zur Analyse der Kundenabwanderungsvorhersage mit Ensemble Learning an, um die Abwanderung zu bekämpfen.
Wie beginne ich ein Projekt für maschinelles Lernen?
Kein Projekt kommt ohne solide Planung erfolgreich voran, und maschinelles Lernen bildet da keine Ausnahme. Der Aufbau Ihres ersten maschinellen Lernprojekts ist gar nicht so schwierig, wie es scheint, vorausgesetzt, Sie haben eine solide Planungsstrategie. Um ein ML-Projekt zu starten, muss man einen umfassenden End-to-End-Ansatz verfolgen – angefangen beim Projekt-Scoping bis hin zur Modellbereitstellung und -verwaltung in der Produktion. Hier ist unsere Sicht auf die grundlegenden Schritte eines Projektplans für maschinelles Lernen, um sicherzustellen, dass Sie das Beste aus jedem einzelnen Projekt machen –
1) Erster Schritt: Scoping des Projekts für maschinelles Lernen
Vor allem anderen müssen Sie verstehen, was die geschäftlichen Anforderungen des ML-Projekts sind. Beim Start eines ML-Projekts ist die Auswahl des relevanten geschäftlichen Anwendungsfalls, für den das maschinelle Lernmodell entwickelt werden soll, der wichtigste Schritt. Die Wahl des richtigen Anwendungsfalls für maschinelles Lernen und die Bewertung seiner Rentabilität sind wichtig für den Erfolg eines jeden Projekts für maschinelles Lernen.
2) Zweiter Schritt: Daten
Daten sind das Lebenselixier eines jeden maschinellen Lernmodells, und es ist unmöglich, ein maschinelles Lernmodell ohne Daten zu trainieren. Die Datenphase im Lebenszyklus eines maschinellen Lernprojekts besteht aus vier Schritten:
-
Datenanforderungen – Es ist wichtig zu verstehen, welche Art von Daten benötigt wird, das Format der Daten, die Datenquellen und die Compliance-Anforderungen an die Datenquellen.
-
Datenerfassung – Mit Hilfe von Datenbankadministratoren, Datenarchitekten oder Entwicklern müssen Sie die Datenerfassungsstrategie einrichten, um Daten von Orten zu extrahieren, an denen sie innerhalb des Unternehmens oder von anderen Drittanbietern vorhanden sind.
-
Explorative Datenanalyse – Dieser Schritt umfasst im Wesentlichen die Validierung der Datenanforderungen, um sicherzustellen, dass Sie über die richtigen Daten verfügen, die Daten in gutem Zustand und frei von Fehlern sind.
-
Datenaufbereitung – Dieser Schritt umfasst die Vorbereitung der Daten für die Verwendung durch Algorithmen für maschinelles Lernen. Fehlerkorrektur, Feature-Engineering, Kodierung in Datenformaten, die Maschinen verstehen können, und Anomaliekorrektur sind die Aufgaben, die mit der Datenvorbereitung verbunden sind.
3) Dritter Schritt – Erstellung des Modells
Abhängig von der Art des Projekts kann dieser Schritt einige Tage oder Monate dauern. In der Modellierungsphase wird entschieden, welcher Algorithmus für das maschinelle Lernen verwendet werden soll, und das Modell wird mit den Daten trainiert. Für die Auswahl des Modells ist es wichtig, das Maß an Genauigkeit, Fehler und Korrektheit zu kennen, das ein maschinelles Lernmodell einhalten sollte. Nachdem Sie das Modell trainiert haben, bewerten Sie es anhand von Validierungsdaten, um seine Leistung zu analysieren und eine Überanpassung zu vermeiden. Die Modellevaluierung ist ein kritischer Schritt, denn wenn ein Modell mit historischen Daten perfekt funktioniert und mit zukünftigen Daten eine schlechte Leistung erbringt, ist es nutzlos.
4) Vierter Schritt – Bereitstellung des Modells in der Produktion
Dieser Schritt beinhaltet die Bereitstellung von Software oder Anwendungen für Endbenutzer, damit neue Daten in das maschinelle Lernmodell für weiteres Lernen einfließen können. Die Bereitstellung des maschinellen Lernmodells ist nicht genug, Sie müssen auch sicherstellen, dass das maschinelle Lernmodell die erwartete Leistung erbringt. Sie sollten Ihr Modell anhand der neuen Live-Produktionsdaten neu trainieren, um seine Genauigkeit oder Leistung zu gewährleisten – dies ist die Modelloptimierung. Die Modellabstimmung erfordert auch eine Validierung des Modells, um sicherzustellen, dass es nicht abdriftet oder verzerrt wird.
Wie können Sie Projekte zum maschinellen Lernen in Ihren Lebenslauf aufnehmen?
Reale Erfahrungen bereiten Sie wie nichts anderes auf den endgültigen Erfolg vor. Je mehr Sie als Anfänger im Bereich des maschinellen Lernens Echtzeit-Erfahrungen bei der Arbeit an maschinellen Lernprojekten sammeln können, desto besser sind Sie darauf vorbereitet, die heißesten Jobs des Jahrzehnts zu ergattern. Ob Sie nach einer Data-Science-Ausbildung einen Job im Bereich maschinelles Lernen bekommen oder als Data Scientist erfolgreich werden, hängt von Ihrer Fähigkeit ab, sich selbst zu verkaufen. Nachdem Sie eine umfassende Data-Science-Ausbildung absolviert haben, besteht der nächste Schritt auf dem Weg zu einem Top-Job als Ingenieur für maschinelles Lernen oder als Datenwissenschaftler darin, ein hervorragendes Portfolio zu erstellen, um Ihre Fähigkeit, Techniken des maschinellen Lernens anzuwenden, Ihren potenziellen Arbeitgebern zu präsentieren. Die Arbeit an interessanten ML-Projekten ist ein guter Weg, um Ihre Karriere als Ingenieur für maschinelles Lernen oder Datenwissenschaftler in Unternehmen zu starten. Arbeitgeber möchten sehen, an welcher Art von Projekten im Zusammenhang mit Datenwissenschaft und maschinellem Lernen Sie gearbeitet haben, um die Bandbreite Ihrer Fähigkeiten in den Bereichen Datenwissenschaft und maschinelles Lernen zu bewerten. Wenn Sie in Ihrem Lebenslauf einige lustige, coole und interessante Projektbeispiele aus den Bereichen Datenwissenschaft und maschinelles Lernen anführen, hat das mehr Gewicht, als wenn Sie erzählen, wie viel Sie wissen.
- Sie können die Projekte zum maschinellen Lernen direkt nach dem Abschnitt Berufserfahrung im Lebenslauf zum maschinellen Lernen erwähnen.
- Befolgen Sie eine fortlaufende Nummerierung zusammen mit dem Titel der Projekte, an denen Sie gearbeitet haben.
- Dem Titel des Projekts sollte eine kurze Beschreibung des Datensatzes und der Problemstellung folgen.
- Erwähnen Sie die Tools und Technologien für maschinelles Lernen, die Sie für die Fertigstellung eines Projekts verwendet haben.
- Zu guter Letzt sollten Sie in Ihrem Portfolio/Lebenslauf jedes Projekt für maschinelles Lernen mit GitHub, Ihrer persönlichen Website oder Ihrem Blog verlinken, um ein tieferes Verständnis Ihrer Leistungen zu erhalten.
Ob Sie nun ein starkes Portfolio für maschinelles Lernen aufbauen oder die analytischen Fähigkeiten, die Sie in Ihrem Data-Science-Kurs erlernt haben, in der Praxis anwenden möchten, wir haben alles für Sie. Viele Anfänger im Bereich des maschinellen Lernens sind sich nicht sicher, wo sie anfangen sollen, welche maschinellen Lernprojekte sie durchführen sollen und welche maschinellen Lernwerkzeuge, Techniken und Frameworks sie verwenden sollen. Wir haben es Anfängern in den Bereichen Datenwissenschaft und maschinelles Lernen leicht gemacht, indem wir eine Liste interessanter Ideen für Projekte zum maschinellen Lernen zusammen mit ihren Lösungen zusammengestellt haben. Diese Ideen für Projekte zum maschinellen Lernen stammen aus beliebten Kaggle Data Science Challenges und sind eine gute Möglichkeit, maschinelles Lernen zu lernen. Diese Liste von Projekten ist eine perfekte Möglichkeit, Projekte zum maschinellen Lernen in Ihren Lebenslauf aufzunehmen. Die richtige Einstellung, die Bereitschaft zu lernen und eine Menge Datenexploration sind erforderlich, um die Lösung für Projekte im Bereich Datenwissenschaft und maschinelles Lernen zu verstehen. Sie können 50+ Data Science- und ML-Projekte erkunden, die auf den Fähigkeiten, Tools und Techniken basieren, die Sie lernen müssen.
Bevor Sie mit Ihrem Projekt beginnen, ist es hilfreich, Zugang zu einer Bibliothek mit Codebeispielen für maschinelles Lernen zu haben. Wann immer Sie bei einem Projekt nicht weiterkommen, können Sie diese gelösten Beispiele verwenden, um sich aus der Patsche zu helfen.
Zugriff auf Code-Beispiele für Data Science und maschinelles Lernen
Wie geht es weiter?
Ein Meister des maschinellen Lernens kann man nur mit viel Übung und Experimentieren werden. Theoretisches Wissen ist sicherlich hilfreich, aber es ist die Anwendung, die den Fortschritt am meisten fördert. Kein noch so großes theoretisches Wissen kann die praktische Anwendung ersetzen. Es ist jedoch hilfreich, wenn Sie sich zunächst mit den oben aufgeführten innovativen Projekten zum maschinellen Lernen vertraut machen.
Wenn Sie Anfänger sind und sich noch nicht mit dem maschinellen Lernen auskennen, dann ist die Arbeit an Projekten zum maschinellen Lernen, die von den Branchenexperten bei ProjectPro entwickelt wurden, eine der besten Investitionen Ihrer Zeit. Diese Projekte wurden für Anfänger entwickelt, um ihnen dabei zu helfen, ihre Fähigkeiten im Bereich des maschinellen Lernens schnell zu verbessern, und ihnen gleichzeitig die Möglichkeit zu geben, interessante Geschäftsanwendungen in verschiedenen Bereichen zu erforschen – Einzelhandel, Finanzen, Versicherungen, Fertigung und mehr. Wenn Sie also Spaß am maschinellen Lernen haben, motiviert bleiben und schnell Fortschritte machen wollen, dann sind die interessanten ML-Projekte von ProjectPro genau das Richtige für Sie. Fügen Sie diese Projekte zum maschinellen Lernen zu Ihrem Portfolio hinzu und landen Sie einen Top-Auftrag mit einem höheren Gehalt und lohnenden Vergünstigungen.

Klicken Sie hier, um eine Liste von 50+ gelösten, durchgängigen Projektlösungen im Bereich maschinelles Lernen und Big Data zu sehen
|
VORHERIGES |
NÄCHSTES |