
Von: Aaron Bertrand | Updated: 2019-12-03 | Comments (1) | Related: Mehr > Leistungstuning
Problem
Vor einigen Jahren habe ich darüber gebloggt, wie man die Auswirkungen auf das Transaktionsprotokoll reduzieren kann, indem man Löschvorgänge in kleine Stücke aufteilt. Anstatt 100.000 Zeilen in einer großen Transaktion zu löschen, können Sie 100 oder 1.000 oder eine beliebige Anzahl von Zeilen in mehreren kleineren Transaktionen in einer Schleife löschen. Dadurch werden nicht nur die Auswirkungen auf das Protokoll verringert, sondern auch lang andauernde Blockierungen beseitigt. Zu dieser Zeit waren SSDs gerade auf dem Vormarsch, und neuere Technologien wie Clustered Columnstore Indexes, Delayed Durability und Accelerated Database Recovery gab es noch nicht. Daher dachte ich, es wäre an der Zeit für eine Aktualisierung, um ein besseres Bild davon zu vermitteln, wie sich dies in SQL Server2019 auswirkt.
Lösung
Das Löschen großer Teile einer Tabelle ist nicht immer die einzige Lösung. Wenn Sie 95 % einer Tabelle löschen und 5 % behalten, kann es schneller sein, die zu behaltenden Zeilen in eine neue Tabelle zu verschieben, die alte Tabelle zu löschen und die neue Tabelle umzubenennen oder die zu behaltenden Zeilen herauszukopieren, die Tabelle abzuschneiden und sie dann wieder hineinzukopieren. Aber selbst wenn die Bereinigung so viel größer ist als die Beibehaltung, ist dies aufgrund anderer Einschränkungen der Tabelle, SLAs und anderer Faktoren nicht immer möglich.
Wenn Sie Zeilen löschen müssen, sollten Sie die Auswirkungen auf das Transaktionsprotokoll und die Auswirkungen der Operationen auf den Rest der Arbeitslast minimieren.Der Chunking-Ansatz ist keine neue oder neuartige Idee, aber er kann gut mit einigen dieser neueren Technologien funktionieren.
Zur Vorbereitung haben wir mehrere Konstanten, die für jeden Test gelten werden:
- SQL Server 2019 RC1, mit vier Kernen und 32 GB RAM (maximaler Serverspeicher =28 GB)
- Tabelle mit 10 Millionen Zeilen
- Neustart von SQL Server nach jedem Test (um Speicher, Puffer, und Plancache zurückzusetzen)
- Wiederherstellen eines Backups, bei dem die Statistiken bereits aktualisiert und die automatischen Statistiken deaktiviert wurden (um zu verhindern, dass ausgelöste Statistikaktualisierungen Löschvorgänge beeinträchtigen)
Wir haben auch viele Variablen, die sich pro Test ändern werden:
Daraus ergeben sich 864 einzigartige Tests, und Sie können mir glauben, dass ich alle diese Permutationen automatisieren werde.
Und die Metriken, die wir messen werden:
- Gesamtdauer
- Durchschnitts-/Spitzen-CPU-Nutzung
- Durchschnitts-/Spitzenspeichernutzung
- Transaktionsprotokollnutzung/Dateiwachstum
- Datenbankdatei-Nutzung, Größe des Versionsspeichers (bei Verwendung von Accelerated DatabaseRecovery)
- Größe der Delta-Zeilengruppen (bei Verwendung von Columnstore)
Quelltabelle
Zunächst habe ich eine Kopie von AdventureWorks (AdventureWorks2017.bak, um genau zu sein). Um eine Tabelle mit 10 Millionen Zeilen zu erstellen, habe ich eine Kopie von Sales.SalesOrderDetail mit einer eigenen Identitätsspalte und fügte eine Füllspalte hinzu, um jeder Zeile etwas mehr Inhalt zu geben und die Seitendichte zu verringern:
CREATE TABLE dbo.SalesOrderDetailCopy
(
SalesOrderDetailID int IDENTITY,
SalesOrderID int,
CarrierTrackingNumber nvarchar(25),
OrderQty smallint,
ProductID int,
SpecialOfferID int,
UnitPrice money,
UnitPriceDiscount money,
LineTotal numeric(38,6),
rowguid uniqueidentifier,
ModifiedDate datetime,
filler char(50) NOT NULL DEFAULT ''
);
GO
Um dann die 10.000.000 Zeilen zu erzeugen, fügte ich jeweils 100.000 Zeilen ein und führte die Einfügung 100 Mal aus:
INSERT dbo.SalesOrderDetailCopy
(
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
)
SELECT TOP(100000)
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
FROM Sales.SalesOrderDetail;GO 100
Ich habe keine Indizes für die Tabelle erstellt; je nach Speicherkonzept werde ich nach der Wiederherstellung der Datenbank im Rahmen jedes Tests einen neuen geclusterten Index erstellen (zur Hälfte im Spaltenstore).
Automatisierung der Tests
Nachdem die 10-Millionen-Zeilen-Tabelle existierte, stellte ich einige Optionen ein, sicherte die Datenbank, sicherte das Protokoll zweimal und sicherte dann die Datenbank erneut (damit das Protokoll bei der Wiederherstellung so wenig Platz wie möglich beansprucht):
Als Nächstes erstellte ich eine Kontrolldatenbank, in der ich die gespeicherten Prozeduren, mit denen die Tests ausgeführt werden sollten, und die Tabellen mit den Testergebnissen (nur die Start- und Endzeit jedes Tests) sowie die während aller Tests erfassten Leistungskennzahlen speichern würde.
Das Erfassen der Permutationen aller 864 Tests, die ich durchführen wollte, nahm einige Versuche in Anspruch, aber am Ende hatte ich folgendes Ergebnis:
Wie erwartet, wurden 864 Zeilen mit all diesen Kombinationen eingefügt.
Als Nächstes erstellte ich eine gespeicherte Prozedur, um den zuvor beschriebenen Satz von Metriken zu erfassen.Ich überwache die Instanz auch mit SentryOne SQL Sentry, so dass dort sicherlich noch einige andere interessante Informationen verfügbar sind, aber ich wollte die wichtigen Details auch ohne die Verwendung von Drittanbieter-Tools erfassen. Hier ist die Prozedur, die sich die Mühe macht, alle Metriken für einen bestimmten Zeitstempel in einer einzigen Zeile auszugeben:
Ich habe diese gespeicherte Prozedur in einen Job-Step eingefügt und ihn gestartet. Möglicherweise möchten Sie eine andere Verzögerung als drei Sekunden verwenden – es gibt einen Kompromiss zwischen den Kosten der Erfassung und der Vollständigkeit der Daten, der für Sie eher in die eine als in die andere Richtung geht.
Schließlich erstellte ich die Prozedur, die die gesamte Logik enthalten würde, um genau zu bestimmen, was mit der Kombination von Parametern für jeden einzelnen Test zu tun ist.Auch hier waren mehrere Iterationen erforderlich, aber das Endprodukt sieht wie folgt aus:
Es gibt eine Menge zu tun, aber die grundlegende Logik ist wie folgt:
- Die testspezifischen Daten (TestID und alle Parameter) werden aus der dbo.Teststable
- Geben Sie SQL Server einen Kick, indem Sie eine sp_configure-Änderung vornehmen und die Puffer und den Plan-Cache löschen
- Stellen Sie eine saubere Kopie von AdventureWorks wieder her, wobei alle 10 Millionen Zeilen intakt sind,und ohne Indizes
- Ändern Sie die Optionen der Datenbank in Abhängigkeit von den Parametern für den aktuellen Test
- Erstellen Sie entweder einen geclusterten Columnstore-Index oder einen geclusterten B-Baum-Index
- Aktualisieren Sie die Statistiken für die Tabelle manuell, nur um sicherzugehen
- Protokollieren Sie, dass wir den Test gestartet haben
- Bestimmen Sie, wie viele Iterationen der Schleife wir benötigen und wie viele Zeilen in jeder Iteration gelöscht werden sollen
- Innerhalb der Schleife:
- Bestimmen, ob wir in dieser Iteration eine Transaktion starten müssen
- Das Löschen durchführen
- Bestimmen, ob wir in dieser Iteration die Transaktion festschreiben müssen
- Bestimmen, ob wir in dieser Iteration einen Checkpoint setzen / das Protokoll sichern müssen
- Nach der Schleife, wird protokolliert, dass dieser Test abgeschlossen ist, und alle nicht bestätigten Transaktionen werden übertragen
Um den Test tatsächlich auszuführen, möchte ich dies nicht in Management Studio tun (auch nicht auf derselben VM), da dies zu viel Aufwand bedeutet und zusätzliche Daten und Ressourcen verbraucht werden.Ich habe eine gespeicherte Prozedur erstellt und diese auch in einen Job eingefügt:
Das hat viel länger gedauert, als ich zugeben möchte. Das lag zum Teil daran, dass ich ursprünglich einen 0,1 %-Test für Zeile pro Schleife eingebaut hatte, was in einigen Fällen mehrere Stunden dauerte. Ich habe diese also nach ein paar Tagen aus der Tabelle entfernt und kann mit Leichtigkeit sagen: Wenn man 1.000.000 Zeilen entfernt, ist es höchst unwahrscheinlich, dass das Löschen von 1.000 Zeilen auf einmal die optimale Wahl ist, unabhängig von allen anderen Variablen:

(Das scheint zwar eine Anomalie im Vergleich zu den meisten anderen Tests zu sein, aber ich wette, das wäre nicht viel schneller als das Löschen von einer oder 10 Zeilen auf einmal. Und tatsächlich war es in jedem anderen Szenario langsamer als das Löschen der halben Tabelle oder des größten Teils der Tabelle.)
Leistungsergebnisse
Nachdem ich die Ergebnisse der 0,1 %-Tests verworfen hatte, legte ich den Rest in einer zweiten Metrik-Tabelle ab, in die die Dauern geladen wurden:
Ich musste einen Outer-Join auf die Metrik-Tabelle anwenden, weil einige Tests so schnell liefen, dass nicht genug Zeit zum Erfassen der Daten blieb. Das bedeutet, dass es für einige der schnelleren Tests keine Korrelation mit anderen Leistungsdetails gibt, außer wie schnell sie liefen.
Dann begann ich nach Trends und Anomalien zu suchen. Zunächst habe ich die Dauer und die CPU-Leistung in Abhängigkeit davon untersucht, ob Delayed Durability (DD) und/oder Accelerated Database Recovery (ADR) aktiviert waren:
Ergebnisse (mit hervorgehobenen Anomalien):

Sieht so aus, als ob die Gesamtdauer im Durchschnitt etwa gleich stark verbessert wird, wenn eine der beiden Optionen aktiviert ist (oder beide – und wenn beide aktiviert sind, ist die Spitze niedriger). Es scheint einen Ausreißer bei der Dauer für ADR allein zu geben, der sich nicht auf den Durchschnitt auswirkt (bei diesem speziellen Test wurden 9.000.000 Zeilen gelöscht, 90.000 Zeilen auf einmal, in FULL recovery, in einer Rowstore-Tabelle). Der CPU-Ausreißer für DD hatte ebenfalls keinen Einfluss auf den Durchschnitt – in diesem speziellen Beispiel wurden 1.000.000 Zeilen auf einmal in einer Columnstore-Tabelle gelöscht.
Wie sieht es mit den Gesamtunterschieden beim Vergleich von Rowstore und Columnstore aus?
Ergebnisse:

Columnstore ist im Durchschnitt 20% langsamer, benötigt aber weniger Speicher. Ich wollte auch die Auswirkungen auf die Größe und Nutzung von Datendateien und Protokolldateien sehen:
Ergebnisse:

Schließlich scheint das Löschen in Paketen auf der heutigen Hardware nicht mehr die gleichen Vorteile zu haben wie früher, zumindest was die Dauer betrifft. Die 18 schnellsten Ergebnisse hier und 72 der schnellsten 100 waren Tests, bei denen alle Zeilen in einem Zug gelöscht wurden, wie diese Abfrage zeigt:
Ergebnisse:
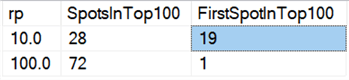
Und wenn wir die Durchschnittswerte für alle Daten betrachten, wie in dieser Abfrage:
Wir sehen, dass das Löschen aller Zeilen auf einmal, unabhängig davon, ob wir 10 %, 50 % oder 90 % löschen, schneller ist als das Chunking von Löschungen (wiederum im Durchschnitt):
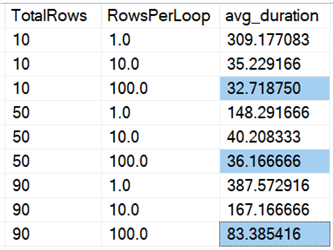
In Diagrammform:
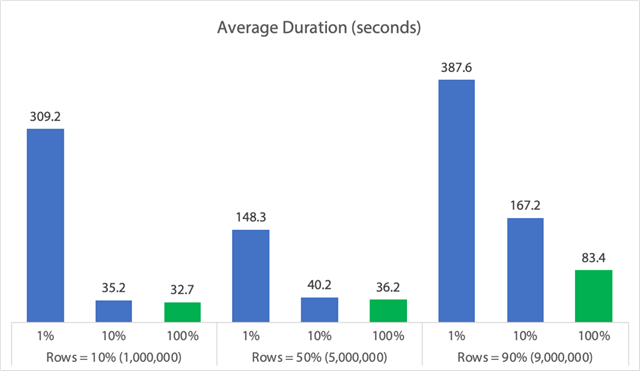
(Beachten Sie, dass die erste Spalte von 309 Sekunden auf 162 Sekunden sinkt, wenn wir den zuvor identifizierten 6.062-Sekunden-Ausreißer bei max_duration herausnehmen.)
Nun, selbst im besten Fall sind das immer noch 33, 36 oder 83 Sekunden, in denen das Löschen läuft und möglicherweise alle anderen blockiert, und das ohne Berücksichtigung anderer gemessener Auswirkungen wie Speicher, Protokolldatei, CPU usw. Die Dauer sollte sicherlich nicht das einzige Kriterium sein; es ist nur so, dass sie in der Regel das erste (und manchmal einzige) Kriterium ist, auf das die Leute achten. Dieses Test-Kabelbaum sollte zeigen, dass Sie auch mehrere andere Metriken erfassen können und sollten, und die Ergebnisse zeigen, dass Ausreißer von überall her kommen können.
Mit diesem Kabelbaum als Modell können Sie Ihre eigenen Tests konstruieren, die sich enger auf die Einschränkungen und Fähigkeiten in Ihrer Umgebung konzentrieren. Ich habe die Metriken nicht aus allen möglichen Blickwinkeln betrachtet, da es eine Vielzahl von Permutationen gibt, aber ich werde diese Datenbank beibehalten. Wenn es also andere Möglichkeiten gibt, die Daten aufzuschlüsseln, lassen Sie es mich in den Kommentaren wissen, und ich werde sehen, was ich tun kann. Verlangen Sie nur nicht, dass ich alle Tests noch einmal durchführe.
Caveats
Dies alles berücksichtigt nicht die gleichzeitige Arbeitslast, die Auswirkungen von Tabellenbeschränkungen wie Fremdschlüsseln, das Vorhandensein von Triggern und eine Vielzahl anderer möglicher Szenarien.Eine weitere Testmöglichkeit (möglicherweise in einem zukünftigen Tipp) besteht darin, mehrere Aufträge zu haben, die während des gesamten Vorgangs mit derselben Tabelle interagieren, und Dinge wie Blockierungsdauer, Wartetypen und -zeiten zu messen und zu beurteilen, in welchen Situationen ein Satz von Aktivitäten einen stärkeren Einfluss auf den anderen Satz hat.
Nächste Schritte
Lesen Sie weiter für verwandte Tipps und andere Ressourcen:
- CRUD-Operationen in SQL Server
- Unterschiede zwischen Löschen und Trunkieren in SQL Server
- Löschen historischer Daten aus einer großen, hochgradig konkurrierenden SQL Server-Datenbanktabelle
- Große Löschvorgänge in Stücke unterteilen
- Beispiel für geclusterte und nicht geclusterte Columnstore-Indizes in SQL Server
- Verzögerte Haltbarkeit in SQL Server 2014
- Verzögerte Haltbarkeit beim Bereinigen von Daten
- Beschleunigte Datenbankwiederherstellung in SQL Server 2019
Letzte Aktualisierung: 2019-12-03


Über den Autor
 Aaron Bertrand (@AaronBertrand) ist ein leidenschaftlicher Technologe mit Branchenerfahrung, die bis zu Classic ASP und SQL Server 6.5 zurückreicht. Er ist Chefredakteur des leistungsbezogenen Blogs SQLPerformance.com und bloggt auch auf sqlblog.org.
Aaron Bertrand (@AaronBertrand) ist ein leidenschaftlicher Technologe mit Branchenerfahrung, die bis zu Classic ASP und SQL Server 6.5 zurückreicht. Er ist Chefredakteur des leistungsbezogenen Blogs SQLPerformance.com und bloggt auch auf sqlblog.org.Alle meine Tipps anzeigen
- Weitere SQL Server DBA-Tipps…