
- Få adgang til de bedste ML-projekter
- Maskinlæringsprojekter for begyndere i 2021
- Salgsprognoser ved hjælp af Walmart-datasæt
- BigMart Sales Prediction ML Project
- Music Recommendation System Projekt
- Menneskelig aktivitetsgenkendelse ved hjælp af smartphone-datasæt
- Børskursforudsigelse ved hjælp af tidsserier
- Forudsigelse af vinkvalitet ved hjælp af datasæt om vinkvalitet
- MNIST Klassifikation af håndskrevne tal
- Lær at opbygge anbefalingssystemer med Movielens-datasæt
- Boston Housing Price Prediction ML Project
- Social Media Sentiment Analysis using Twitter Datasæt
- Iris Flowers Classification ML Project
- Optimering af detailhandelspriser ved hjælp af maskinlæring
- Analyse af forudsigelse af kundeafgang
- 1. Salgsprognoser ved hjælp af Walmart-datasæt
- 2. BigMart Sales Prediction ML Project – Lær om uovervågede maskinlæringsalgoritmer
- Music Recommendation System Project
- Human Activity Recognition using Smartphone Dataset
- Stock Prices Predictor using TimeSeries
- Forudsigelse af vinkvalitet ved hjælp af vinkvalitetsdatasæt
- MNIST Handwritten Digit Classification
- Lær at opbygge anbefalingssystemer med Movielens datasæt
- Boston Housing Price Prediction ML Project
- Social Media Sentiment Analysis using Twitter Dataset
- Iris Flowers Classification ML Project- Learn about Supervised Machine Learning Algorithms
- Machine Learning Projects for Beginners with Source Code in Python for 2021
- 12) Retail Price Optimization ML Project – Dynamic Pricing Machine Learning Model for a Dynamic Market
- 13) Customer Churn Prediction Analysis Using Ensemble Techniques in Machine Learning
- Hvordan starter jeg et maskinlæringsprojekt?
- 1) Første trin: Machine Learning Project Scoping
- 2) Andet trin: Data
- 3) Tredje trin – Opbygning af modellen
- 4) Fjerde trin – Udrulning af model til produktion
- Hvordan får du maskinlæringsprojekter på dit cv?
- What Next?
Få adgang til de bedste ML-projekter
×
Sidst opdateret: 05 mar 2021

Du ønsker at lære maskinlæring, men har svært ved at komme i gang med det. Bøger og kurser er måske ikke bare nok, når det kommer til maskinlæring selvom de altid giver eksempler på maskinlæringskoder og snippets, får du ikke mulighed for at implementere maskinlæring til virkelige problemer og se, hvordan disse kode-snippets passer sammen. Den bedste måde at komme i gang med at lære maskinlæring på er at gennemføre maskinlæringsprojekter på begynder- til avanceret niveau. Det er altid nyttigt at få indsigt i, hvordan rigtige mennesker begynder deres karriere inden for maskinlæring ved at implementere end-to-end ML-projekter.
I dette blogindlæg vil du finde ud af, hvordan begyndere som dig kan gøre store fremskridt med at anvende maskinlæring på virkelige problemer med disse fantastiske maskinlæringsprojekter for begyndere, der anbefales af brancheeksperter. ProjectPro-branchens eksperter har omhyggeligt kurateret listen over de bedste maskinlæringsprojekter for begyndere, der dækker de centrale aspekter af maskinlæring som f.eks. overvåget læring, uovervåget læring, dyb læring og neurale netværk. I alle disse maskinlæringsprojekter vil du begynde med virkelige datasæt, som er offentligt tilgængelige. Vi forsikrer, at du vil finde denne blog absolut interessant og værd at læse på grund af alle de ting, du kan lære herfra om de mest populære maskinlæringsprojekter.
“Hvilke projekter kan jeg lave med maskinlæring ?” Vi får ofte stillet dette spørgsmål meget fra nybegyndere, der skal i gang med maskinlæring. ProjectPro brancheeksperter anbefaler, at du udforsker nogle spændende, seje, sjove og nemme ideer til maskinlæringsprojekter på tværs af forskellige forretningsdomæner for at få praktisk erfaring med de maskinlæringsfærdigheder, du har lært. Vi har kurateret en liste over innovative og interessante maskinlæringsprojekter med kildekode for fagfolk, der begynder deres karriere inden for maskinlæring. Disse begynderprojekter om maskinlæring er en perfekt blanding af forskellige typer udfordringer, som man kan støde på, når man arbejder som maskinlæringsingeniør eller datavidenskabsmand.
Maskinlæringsprojekter for begyndere i 2021
-
Salgsprognoser ved hjælp af Walmart-datasæt
-
BigMart Sales Prediction ML Project
-
Music Recommendation System Projekt
-
Menneskelig aktivitetsgenkendelse ved hjælp af smartphone-datasæt
-
Børskursforudsigelse ved hjælp af tidsserier
-
Forudsigelse af vinkvalitet ved hjælp af datasæt om vinkvalitet
-
MNIST Klassifikation af håndskrevne tal
-
Lær at opbygge anbefalingssystemer med Movielens-datasæt
-
Boston Housing Price Prediction ML Project
-
Social Media Sentiment Analysis using Twitter Datasæt
-
Iris Flowers Classification ML Project
-
Optimering af detailhandelspriser ved hjælp af maskinlæring
-
Analyse af forudsigelse af kundeafgang
Lad os dykke ned i det!

1. Salgsprognoser ved hjælp af Walmart-datasæt
Salgsprognoser er et af de mest almindelige anvendelsesområder for maskinlæring til identifikation af faktorer, der påvirker salget af et produkt og estimering af fremtidig salgsmængde. Dette maskinlæringsprojekt gør brug af Walmart-datasættet, der har salgsdata for 98 produkter på tværs af 45 forretninger. Datasættet indeholder salg pr. butik, pr. afdeling på ugentlig basis. Målet med dette maskinlæringsprojekt er at forudsige salget for hver afdeling i hver forretning for at hjælpe dem med at træffe bedre datadrevne beslutninger med henblik på kanaloptimering og lagerplanlægning. Det udfordrende aspekt ved at arbejde med Walmart-datasættet er, at det indeholder udvalgte markdown-hændelser, der påvirker salget, og som skal tages i betragtning.
Dette er et af de mest enkle og seje maskinlæringsprojekter, hvor du skal opbygge en prædiktiv model ved hjælp af Walmart-datasættet for at estimere antallet af salg, de vil lave i fremtiden, og her er hvordan –
- Importér dataene og udforsk dem for at forstå strukturen og værdierne i dataene – Begynd med at importere en CSV-fil og udfør grundlæggende Exploratory Data Analysis (EDA).
- Forbered dataene til modellering – Sammenlæg flere datasæt, og anvend group by-funktionen til at analysere data.
- Plot en tidsseriediagram, og analysér den.
- Fit de udviklede salgsprognosemodeller til træningsdataene- Opret en ARIMA-model til tidsserieprognoser
- Sammenlign de udviklede modeller på testdataene.
- Optimer salgsprognosemodellerne ved at vælge vigtige funktioner for at forbedre nøjagtighedsscoren.
- Gør brug af den bedste maskinlæringsmodel til at forudsige næste års salg.
Når du har arbejdet med dette Kaggle-maskinlæringsprojekt, vil du forstå, hvordan kraftfulde maskinlæringsmodeller kan gøre den overordnede salgsprognoseproces enkel. Genbrug disse end-to-end salgsprognosemodeller til maskinlæringsmodeller i produktionen for at forudsige salget for enhver afdeling eller detailbutik.
Vil du arbejde med Walmart Dataset? Få adgang til den komplette løsning til dette fantastiske maskinlæringsprojekt her – Walmart Store Sales Forecasting Machine Learning Project
2. BigMart Sales Prediction ML Project – Lær om uovervågede maskinlæringsalgoritmer
BigMart salgsdatasæt består af 2013 salgsdata for 1559 produkter på tværs af 10 forskellige forretninger i forskellige byer. Målet med BigMart-salgsforudsigelses-ML-projektet er at opbygge en regressionsmodel til at forudsige salget af hvert af de 1559 produkter for det følgende år i hver af de 10 forskellige BigMart-forretninger. BigMart-salgsdatasættet består også af visse attributter for hvert produkt og hver butik. Denne model hjælper BigMart med at forstå de egenskaber ved produkter og butikker, der spiller en vigtig rolle for at øge deres samlede salg.
Access the complete solution to this ML Project Here – BigMart Sales Prediction Machine Learning Project Solution
Music Recommendation System Project
Dette er et af de mest populære maskinlæringsprojekter og kan bruges på tværs af forskellige domæner. Du er måske meget bekendt med et anbefalingssystem, hvis du har brugt et e-handelswebsted eller et film/musikwebsted. På de fleste e-handelswebsteder som Amazon vil systemet på tidspunktet for kassen anbefale produkter, der kan føjes til din kurv. På Netflix eller Spotify viser systemet på samme måde lignende film eller sange, som du måske kan lide, på grundlag af de film, du har syntes om. Hvordan gør systemet dette? Dette er et klassisk eksempel, hvor Machine Learning kan anvendes.
I dette projekt bruger vi datasættet fra Asiens førende musikstreamingtjeneste til at opbygge et bedre musikanbefalingssystem. Vi vil forsøge at afgøre, hvilken ny sang eller hvilken ny kunstner en lytter måske vil kunne lide på baggrund af deres tidligere valg. Den primære opgave er at forudsige chancerne for, at en bruger lytter til en sang gentagne gange inden for en tidsramme. I datasættet er forudsigelsen markeret som 1, hvis brugeren har lyttet til den samme sang inden for en måned. Datasættet består af, hvilken sang der er blevet hørt af hvilken bruger og på hvilket tidspunkt.
Vil du bygge et anbefalingssystem – tjek dette løste ML-projekt her – Music Recommendation Machine Learning Project
Human Activity Recognition using Smartphone Dataset
Smartphone-datasættet består af fitnessaktivitetsoptagelser af 30 personer, der er optaget via smartphone-enabled med inertialsensorer. Målet med dette maskinlæringsprojekt er at opbygge en klassifikationsmodel, der præcist kan identificere menneskelige fitnessaktiviteter. Arbejdet med dette maskinlæringsprojekt vil hjælpe dig med at forstå, hvordan man løser multiklassificeringsproblemer.
Få adgang til dette ML-projekts kildekode her Human Activity Recognition using Smartphone Dataset Project
Klik her for at se en liste med 50+ løste, end-to-end Big Data and Machine Learning Project Solutions (genanvendelig kode + videoer)
Stock Prices Predictor using TimeSeries
Dette er en anden interessant projektidé om maskinlæring for dataloger/maskinlæringsingeniører, der arbejder eller planlægger at arbejde med finansområdet. En forudsigelse af aktiekurser er et system, der lærer om et selskabs præstationer og forudsiger fremtidige aktiekurser. De udfordringer, der er forbundet med at arbejde med aktiekursdata, er, at de er meget granulære, og desuden er der forskellige typer data som volatilitetsindeks, priser, globale makroøkonomiske indikatorer, fundamentale indikatorer og meget mere. En god ting ved at arbejde med aktiemarkedsdata er, at de finansielle markeder har kortere feedbackcyklusser, hvilket gør det lettere for dataeksperter at validere deres forudsigelser på nye data. For at begynde at arbejde med aktiemarkedsdata kan du tage fat på et simpelt maskinlæringsproblem som f.eks. at forudsige 6-måneders prisbevægelser baseret på fundamentale indikatorer fra en organisations kvartalsrapport. Du kan downloade aktiemarkedsdatasæt fra Quandl.com eller Quantopian.com. Der findes forskellige tidsserieprognosemetoder til at forudsige aktiekurser, efterspørgsel osv.
Kig på dette maskinlæringsprojekt, hvor du lærer at afgøre, hvilken prognosemetode der skal bruges hvornår, og hvordan den skal anvendes med tidsserieprognoseeksempel. Forudsigelse af aktiekurser ved hjælp af tidsserieprojekt
Forudsigelse af vinkvalitet ved hjælp af vinkvalitetsdatasæt
Det er et kendt faktum, at jo ældre vinen er, jo bedre smag er den. Der er dog flere andre faktorer end alder, der indgår i certificering af vinkvalitet, som omfatter fysiokemiske tests som alkoholmængde, fast syreindhold, flygtig syre, bestemmelse af densitet, pH-værdi og meget mere. Hovedformålet med dette maskinlæringsprojekt er at opbygge en maskinlæringsmodel til at forudsige vinens kvalitet ved at udforske dens forskellige kemiske egenskaber. Datasættet for vinkvalitet består af 4898 observationer med 11 uafhængige og 1 afhængig variabel.
Få adgang til den komplette løsning af dette maskinlæringsprojekt her – Wine Quality Prediction in R
MNIST Handwritten Digit Classification
Dyb indlæring og neurale netværk spiller en afgørende rolle inden for billedgenkendelse, automatisk tekstgenerering og endda selvkørende biler. For at begynde at arbejde inden for disse områder skal du begynde med et simpelt og håndterbart datasæt som MNIST-datasættet. Det er vanskeligt at arbejde med billeddata frem for flade relationelle data, og som nybegynder foreslår vi, at du kan samle op og løse MNIST Handwritten Digit Classification Challenge. MNIST-datasættet er for lille til at passe ind i din pc-hukommelse og er begyndervenligt. Men genkendelse af håndskrevne tal vil udfordre dig.
Gør din klassiske indgang til at løse billedgenkendelsesproblemer ved at få adgang til den komplette løsning her – MNIST Handwritten Digit Classification Project
Lær at opbygge anbefalingssystemer med Movielens datasæt
Fra Netflix til Hulu har behovet for at opbygge et effektivt filmanbefalingssystem fået større betydning over tid med den stigende efterspørgsel fra moderne forbrugere efter tilpasset indhold. Et af de mest populære datasæt, der er tilgængelige på nettet for begyndere til at lære at opbygge anbefalingssystemer, er Movielens-datasættet, som indeholder ca. 1.000.209 filmvurderinger af 3.900 film foretaget af 6.040 Movielens-brugere. Du kan komme i gang med at arbejde med dette datasæt ved at opbygge en world-cloud-visualisering af filmtitler for at opbygge et filmanbefalingssystem.
Fri adgang til løste kodeeksempler kan findes her (disse er klar til brug for dine ML-projekter)
Boston Housing Price Prediction ML Project
Boston House Prices Dataset består af priser på huse på tværs af forskellige steder i Boston. Datasættet består også af oplysninger om områder med andre forretningsområder end detailhandel (INDUS), kriminalitetsfrekvens (CRIM), alder for personer, der ejer et hus (AGE), og flere andre attributter (datasættet har i alt 14 attributter). Boston Housing-datasættet kan downloades fra UCI Machine Learning Repository. Målet med dette maskinlæringsprojekt er at forudsige salgsprisen på et nyt hus ved at anvende grundlæggende maskinlæringsbegreber på boligprisdataene. Dette datasæt er for lille med 506 observationer og anses for at være en god start for begyndere inden for maskinlæring til at kickstarte deres praktiske øvelse i regressionsbegreber.
Anbefalet læsning – 15+ Data Science Projects for Beginners
Social Media Sentiment Analysis using Twitter Dataset
Sociale medieplatforme som Twitter, Facebook, YouTube, Reddit genererer enorme mængder af big data, der kan udvindes på forskellige måder for at forstå tendenser, offentlige følelser og holdninger. Data fra sociale medier er i dag blevet relevante for branding, markedsføring og forretning som helhed. En sentimentanalysator lærer om forskellige følelser bag et “indholdsstykke” (kan være IM, e-mail, tweet eller et andet indlæg på sociale medier) gennem maskinlæring og forudsiger det samme ved hjælp af AI.Twitter-data betragtes som et definitivt indgangspunkt for begyndere til at øve sig i maskinlæringsproblemer i forbindelse med sentimentanalyse. Ved hjælp af Twitter-datasættet kan man få en fængslende blanding af tweetindhold og andre relaterede metadata såsom hashtags, retweets, placering, brugere m.m., som baner vejen for indsigtsfulde analyser. Twitter-datasættet består af 31.962 tweets og er 3 MB stort. Ved hjælp af Twitter-data kan du finde ud af, hvad verden siger om et emne, uanset om det er film, følelser om det amerikanske valg eller et andet trending emne som f.eks. at forudsige, hvem der ville vinde FIFA World Cup 2018. Arbejdet med Twitter-datasættet vil hjælpe dig med at forstå de udfordringer, der er forbundet med data mining på sociale medier, og du vil også lære om klassifikatorer i dybden. Det første problem, som du kan begynde at arbejde med som nybegynder, er at opbygge en model til at klassificere tweets som positive eller negative.
Gratis adgang til løst kode Python- og R-eksempler kan findes her (disse er klar til brug for dine Data Science- og ML-projekter)
Iris Flowers Classification ML Project- Learn about Supervised Machine Learning Algorithms
Dette er et af de mest enkle maskinlæringsprojekter med Iris Flowers, der er det enkleste maskinlæringsdatasæt i klassifikationslitteraturen. Dette maskinlæringsproblem omtales ofte som maskinlæringens “Hello World”. Datasættet har numeriske attributter, og ML-nybegyndere skal finde ud af, hvordan de skal indlæse og håndtere data. Iris-datasættet er lille, hvilket nemt passer ind i hukommelsen og kræver ingen særlige transformationer eller skalering til at begynde med.
Iris-datasættet kan downloades fra UCI ML Repository – Download Iris Flowers Dataset
Målet med dette maskinlæringsprojekt er at klassificere blomsterne i blandt de tre arter – virginica, setosa eller versicolor baseret på længde og bredde af kronblade og bægerblade.
Gratis adgang til løste maskinlæring Python og R kodeeksempler kan findes her (disse er klar til brug for dine projekter)
Machine Learning Projects for Beginners with Source Code in Python for 2021
12) Retail Price Optimization ML Project – Dynamic Pricing Machine Learning Model for a Dynamic Market
Pricing racer vokser non-stop på tværs af alle vertikale industrier, og optimering af priserne er nøglen til at styre overskuddet effektivt for enhver virksomhed. Det har altid været en stor udfordring i detailbranchen at identificere et rimeligt prisinterval og foretage en justering af prisfastsættelsen af produkter for at øge salget og samtidig holde fortjenstmargenerne optimale. Den hurtigste måde, hvorpå detailhandlere kan sikre den højeste ROI i dag, samtidig med at de optimerer prisfastsættelsen, er at udnytte kraften i maskinlæring til at opbygge effektive prisfastsættelsesløsninger. E-handelsgiganten Amazon var en af de tidligste adoptanter af maskinlæring i detailhandelsprisoptimering, der bidrog til dens stjernevækst fra 30 milliarder i 2008 til ca. 1 billion i 2019.

Image Credit: spd. group
100+ Datasets for Machine Learning Projects Curated Specially For You
Den maskinlæringsmæssige problemløsning for detailhandelsprisoptimering kræver træning af en maskinlæringsmodel, der er i stand til automatisk at prissætte produkter på samme måde, som de ville blive prissat af mennesker. Maskinlæringsmodeller til optimering af detailprisoptimering inddrager historiske salgsdata, forskellige egenskaber ved produkterne og andre ustrukturerede data som billeder og tekstinformationer for at lære prisfastsættelsesreglerne uden menneskelig indgriben, hvilket hjælper detailhandlere med at tilpasse sig et dynamisk prismiljø for at maksimere indtægterne uden at miste fortjenstmarginer. Retail price optimization machine learning-algoritmen behandler et uendeligt antal prissætningsscenarier for at vælge den optimale pris for et produkt i realtid ved at overveje tusindvis af latente relationer inden for et produkt.
Kig på dette seje machine learning-projekt om retail price optimization for et dybt dyk ind i virkelighedens salgsdataanalyse for en Café, hvor du skal bygge en end-to-end machine learning-løsning, der automatisk foreslår de rigtige produktpriser.
13) Customer Churn Prediction Analysis Using Ensemble Techniques in Machine Learning
Kunderne er en virksomheds største aktiv, og det er vigtigt for enhver virksomhed at fastholde kunderne for at øge omsætningen og opbygge et langvarigt meningsfuldt forhold til kunderne. Desuden er omkostningerne ved at skaffe en ny kunde fem gange større end omkostningerne ved at fastholde en eksisterende kunde. Kundeafgang er et af de mest anerkendte problemer i erhvervslivet, hvor kunder eller abonnenter holder op med at gøre forretninger med en tjeneste eller en virksomhed. Ideelt set holder de op med at være betalende kunder. En kunde siges at være afbrudt, hvis der er gået et bestemt tidsrum, siden kunden sidst interagerede med virksomheden.
Det er afgørende for at reducere afbrydelsen at identificere, om og hvornår en kunde vil afbryde og hurtigt levere handlingsanvisende oplysninger med henblik på at fastholde kunderne. Det er ikke muligt for vores hjerner at komme på forkant med kundeafgang for millioner af kunder, det er her, maskinlæring kan hjælpe. Maskinlæring giver effektive metoder til at identificere de underliggende faktorer for kundeafgang og proskriptive værktøjer til at imødegå dem. Maskinlæringsalgoritmer spiller en afgørende rolle i proaktiv churn management, da de afslører adfærdsmønstre hos kunder, som allerede er holdt op med at bruge tjenesterne eller købe produkterne. Derefter kontrollerer maskinlæringsmodellerne de eksisterende kunders adfærd i forhold til sådanne mønstre for at identificere potentielle churnere.

Image Credit. :gallery.azure.ai
Men hvordan starter man med at løse problemet med maskinlæring til forudsigelse af kundeafgangshastighed? Som ethvert andet maskinlæringsproblem skal dataloger eller maskinlæringsingeniører indsamle og forberede dataene til behandling. For at enhver tilgang til maskinlæring kan være effektiv, er det fornuftigt at konstruere dataene i det rigtige format. Feature Engineering er den mest kreative del af churn prediction machine learning-modellen, hvor dataspecialister bruger deres erfaring, forretningskontekst, domæneviden om dataene og kreativitet til at skabe funktioner og skræddersy machine learning-modellen til at forstå, hvorfor kundeafgang sker i en specifik virksomhed.
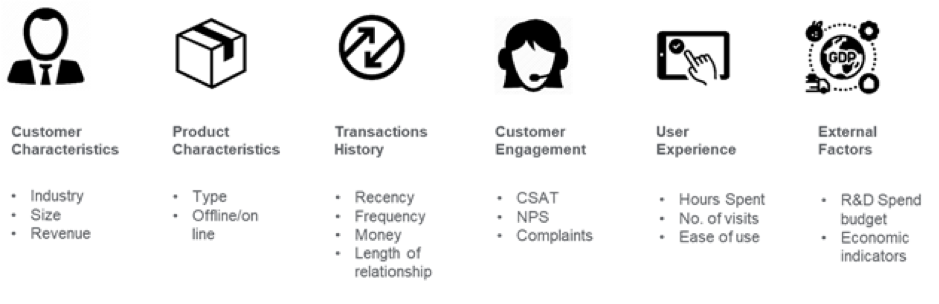
Image Credit: medium.com
For eksempel kan to konti i banksektoren, der har den samme månedlige slutsaldo, være vanskelige at skelne med henblik på churn prediction. Men feature engineering kan tilføje en tidsdimension til disse data, så ML-algoritmer kan skelne, om den månedlige slutsaldo har afveget fra det, der normalt forventes af en kunde. Indikatorer som hvilende konti, stigende udbetalinger, brugstendenser, nettosaldoafstrømning i løbet af de sidste par dage kan være tidlige advarselstegn på churn. Disse interne data kombineret med eksterne data som f.eks. konkurrenters tilbud kan hjælpe med at forudsige kundeafgang. Efter at have identificeret funktionerne er det næste skridt at forstå, hvorfor churns opstår i en forretningssammenhæng, og fjerne de funktioner, der ikke er stærke forudsigere, for at reducere dimensionaliteten.
Kig på dette end-to-end maskinlæringsprojekt med kildekode i Python om Customer Churn Prediction Analysis using Ensemble Learning to combat churn.
Hvordan starter jeg et maskinlæringsprojekt?
Ingen projekter skrider frem med succes uden en solid planlægning, og maskinlæring er ingen undtagelse. Det er faktisk ikke så svært at opbygge dit første maskinlæringsprojekt, som det ser ud til, forudsat at du har en solid planlægningsstrategi. For at starte et ML-projekt skal man følge en omfattende end-to-end-tilgang – lige fra projektafgrænsning til modeludrulning og -styring i produktionen Her er vores bud på de grundlæggende trin i en plan for et maskinlæringsprojekt for at sikre, at du får mest muligt ud af hvert enkelt projekt –
1) Første trin: Machine Learning Project Scoping
Før alt andet skal du forstå, hvad der er forretningskravene til ML-projektet. Når man starter et ML-projekt, er det grundlæggende skridt at vælge den relevante forretningsbrugssag, som maskinlæringsmodellen skal bygges til at løse. At vælge den rigtige machine learning use case og evaluere dens ROI er vigtigt for succesen af ethvert machine learning-projekt.
2) Andet trin: Data
Data er livsblodet i enhver maskinlæringsmodel, og det er umuligt at træne en maskinlæringsmodel uden data. Datafasen i livscyklussen for et maskinlæringsprojekt er en proces i fire trin –
-
Datakrav – Det er vigtigt at forstå, hvilken type data der vil være behov for, dataenes format, datakilderne og kravene til datakildernes overholdelse af reglerne.
-
Dataindsamling – Med hjælp fra databaseadministratorer, dataarkitekter eller udviklere skal du opstille dataindsamlingsstrategien for at udtrække data fra steder, hvor de findes i organisationen eller fra andre tredjepartsleverandører.
-
Udforskende dataanalyse – Dette trin indebærer grundlæggende at validere datakravene for at sikre, at du har de korrekte data, at dataene er i god stand og fri for fejl.
-
Dataforberedelse – Dette trin indebærer at forberede dataene til brug for maskinlæringsalgoritmer. Fejlkorrektion, feature engineering, kodning til dataformater, som maskinerne kan forstå, og korrektion af anomalier er de opgaver, der indgår i dataforberedelsen.
3) Tredje trin – Opbygning af modellen
Afhængigt af projektets karakter kan dette trin tage et par dage eller måneder. I modelleringsfasen træffer du en beslutning om, hvilken maskinlæringsalgoritme der skal bruges, og begynder at træne modellen på dataene. Det er vigtigt at forstå, hvilke mål for nøjagtighed, fejl og korrekthed en maskinlæringsmodel skal overholde i forbindelse med valg af model. Når du har trænet modellen, evaluerer du den på valideringsdata, så du analyserer dens ydeevne og forhindrer overfitting. Evaluering af modellen er et kritisk skridt, for hvis en model fungerer perfekt med historiske data og returnerer dårlig ydeevne med fremtidige data, er den ubrugelig.
4) Fjerde trin – Udrulning af model til produktion
Dette trin indebærer udrulning af software eller app til slutbrugere, så nye data kan strømme ind i maskinlæringsmodellen til yderligere læring. Udrulning af maskinlæringsmodellen er ikke nok, du skal også sikre, at maskinlæringsmodellen fungerer som forventet. Du bør genoptræne din model på de nye live produktionsdata for at sikre dens nøjagtighed eller ydeevne – dette er modelafstemning. Model tuning kræver også validering af modellen for at sikre, at den ikke driver eller bliver skævvredet.
Hvordan får du maskinlæringsprojekter på dit cv?
Erfaring fra den virkelige verden forbereder dig til den endelige succes som intet andet. Jo mere du som nybegynder inden for maskinlæring kan få realtidserfaring ved at arbejde med maskinlæringsprojekter, jo bedre forberedt vil du være til at få fat i de hotteste job i dette årti. At få et job inden for maskinlæring efter at have afsluttet datalogiuddannelsen eller at få succes som datalog afhænger af din evne til at sælge dig selv. Når du har taget en omfattende datavidenskabsuddannelse, er det næste skridt for at få et topjob som maskinlæringsingeniør eller datavidenskabsmand at opbygge en fremragende portefølje for at vise din evne til at anvende maskinlæringsteknikker over for dine potentielle arbejdsgivere. At arbejde på interessante ML-projekter er en fantastisk måde at kickstarte din karriere som maskinlæringsingeniør eller datavidenskabsmand i en virksomhed på. Arbejdsgiverne vil gerne se, hvilke projekter relateret til datalogi og maskinlæring du har arbejdet med for at vurdere dine evner inden for datalogi og maskinlæring. Hvis du fremhæver nogle sjove, seje og interessante eksempler på datalogi og maskinlæringsprojekter i dit CV, vil det have større vægt end at fortælle dem, hvor meget du ved. Her er hvordan du kan tilføje fede projekter til dit cv om maskinlæring –
- Du kan nævne maskinlæringsprojekterne lige efter afsnittet om din erhvervserfaring i cv’et om maskinlæring.
- Følg en sekventiel nummerering sammen med titlen på de projekter, du har arbejdet på.
- Projektets titel bør efterfølges af en lille kort beskrivelse af datasættet og problemformuleringen.
- Nævn de maskinlæringsværktøjer og teknologier, du har brugt til at gennemføre et projekt.
- Sidst, men ikke mindst, skal du i din portefølje/dit CV linke hvert maskinlæringsprojekt til GitHub, dit personlige websted eller din blog for at få en dybdegående forståelse af dine resultater.
Hvad enten du ønsker at opbygge en stærk maskinlæringsportfolio, eller du ønsker at øve dig i analytiske færdigheder, som du har lært i dit datalogiuddannelseskursus, har vi styr på det. Mange begyndere inden for maskinlæring er ikke sikre på, hvor de skal starte, hvilke maskinlæringsprojekter de skal lave, hvilke maskinlæringsværktøjer, teknikker og frameworks de skal bruge. Vi har gjort det til en problemfri opgave for begyndere inden for datalogi og maskinlæring ved at kuratere en liste over interessante ideer til maskinlæringsprojekter sammen med deres løsninger. Disse ideer til maskinlæringsprojekter er hentet fra populære Kaggle-datavidenskabsudfordringer og er en fantastisk måde at lære maskinlæring på. Denne liste over projekter er en perfekt måde at sætte maskinlæringsprojekter på dit cv. Det rigtige mindset, vilje til at lære og en masse dataudforskning er alt sammen nødvendigt for at forstå løsningen på projekter om datalogi og maskinlæring. Du kan udforske 50+ datavidenskab og ML-projekter baseret på det sæt af færdigheder, værktøjer og teknikker, du har brug for at lære.
Hvor du går i gang med dit projekt, er det nyttigt at have adgang til et bibliotek med kodeeksempler på maskinlæringsprojekter. Så når som helst du sidder fast i projektet, kan du bruge disse løste eksempler til at komme videre.
Få adgang til Data Science and Machine Learning Project Code Examples
What Next?
Man kan kun blive en mester i maskinlæring med masser af øvelse og eksperimentering. At have teoretisk viden hjælper helt sikkert, men det er anvendelsen, der hjælper mest med at gøre fremskridt. Ingen mængde teoretisk viden kan erstatte praktisk praksis. Det vil dog hjælpe, hvis du først gør dig bekendt med de ovenfor anførte innovative maskinlæringsprojekter.
Hvis du er nybegynder og ny inden for maskinlæring, så vil arbejdet med maskinlæringsprojekter designet af brancheeksperter hos ProjectPro være nogle af de bedste investeringer af din tid. Disse projekter er designet til begyndere for at hjælpe dem med at forbedre deres anvendte maskinlæringsfærdigheder hurtigt og samtidig give dem en chance for at udforske interessante forretningsanvendelsestilfælde på tværs af forskellige domæner – detailhandel, finans, forsikring, produktion og meget mere. Så hvis du ønsker at nyde at lære maskinlæring, forblive motiveret og gøre hurtige fremskridt, så er ProjectPro’s interessante ML-projekter noget for dig. Tilføj desuden disse maskinlæringsprojekter til din portefølje, og få et topjob med en højere løn og givende frynsegoder.

Klik her for at se en liste over 50+ løste, end-to-end projektløsninger inden for maskinlæring og Big Data
|
PREVIOUS |
NEXT |