
Af: Aaron Bertrand | Opdateret: 2019-12-03 | Kommentarer (1) | Relateret: Mere > Performance Tuning
Problem
For flere år siden bloggede jeg om, hvordan du kan reducere påvirkningen af transaktionsloggen ved at bryde sletteoperationer op i bidder. I stedet for at slette 100.000 rækker i én stor transaktion kan du slette 100 eller 1.000 eller et vilkårligt antal rækker ad gangen i flere mindre transaktioner i en løkke. Ud over at reducere påvirkningen af loggen kan du også afhjælpe langvarige blokeringer. På det tidspunkt var SSD’er lige begyndt at vinde indpas, og nyere teknologier somClustered Columnstore Indexes,Delayed Durability ogAccelerated Database Recovery fandtes endnu ikke. Så jeg tænkte, at det måske var på tide med en opdatering for at give et bedre billede af, hvordan det ser ud i SQL Server2019.
Løsning
Sletning af store dele af en tabel er ikke altid den eneste løsning. Hvis du sletter 95% af en tabel og beholder 5%, kan det faktisk være hurtigere at flytte de rækker, du vil beholde, over i en ny tabel, droppe den gamle tabel og omdøbe den nye tabel eller kopiere de rækker, der skal bevares, ud, afkort tabellen og derefter kopiere dem tilbage i den. Men selv når udrensningen er så meget større end beholdningen, er dette ikke altid muligt på grund af andre begrænsninger på tabellen, SLA’er og andre faktorer.
Og hvis det viser sig, at du er nødt til at slette rækker, vil du også gerne minimere virkningen på transaktionsloggen, og hvordan operationerne påvirker resten af arbejdsbyrden.Chunking-tilgangen er ikke en ny eller ny idé, men den kan fungere godt med nogle af disse nyere teknologier, så lad os sætte dem på prøve i en række forskellige kombinationer.
For at sætte det op har vi flere konstanter, som vil være sande for hver test:
- SQL Server 2019 RC1, med fire kerner og 32 GB RAM (maks. serverhukommelse =28 GB)
- 10 millioner rækker tabel
- Start SQL Server efter hver test (for at nulstille hukommelse, buffere, og plancache)
- Restore en backup, der havde stats allerede opdateret og auto-stats deaktiveret(for at forhindre, at eventuelle udløste statsopdateringer forstyrrer sletteoperationer)
Vi har også mange variabler, der vil ændre sig pr. test:
Dette vil producere 864 unikke tests, og du kan tro, at jeg vil automatisere alle disse permutationer.
Og de målepunkter, vi vil måle:
- Gennemsnitlig varighed
- Gennemsnitligt/spids CPU-forbrug
- Gennemsnitligt/spids hukommelsesforbrug
- Transaktionslogforbrug/filvækst
- Databasefilforbrug, størrelse af versionslager (ved brug af Accelerated DatabaseRecovery)
- Delta-rækkegruppestørrelse (ved brug af Columnstore)
Kildetabel
Først gendannede jeg en kopi af AdventureWorks (AdventureWorks2017.bak,for at være specifik). For at oprette en tabel med 10 millioner rækker, lavede jeg en kopi af Sales.SalesOrderDetail,med sin egen identitetskolonne, og tilføjede en fyldkolonne bare for at give hver række lidt mere kød og reducere sidetætheden:
CREATE TABLE dbo.SalesOrderDetailCopy
(
SalesOrderDetailID int IDENTITY,
SalesOrderID int,
CarrierTrackingNumber nvarchar(25),
OrderQty smallint,
ProductID int,
SpecialOfferID int,
UnitPrice money,
UnitPriceDiscount money,
LineTotal numeric(38,6),
rowguid uniqueidentifier,
ModifiedDate datetime,
filler char(50) NOT NULL DEFAULT ''
);
GO
For at generere de 10.000.000.000 rækker indsatte jeg derefter 100.000 rækker ad gangen og kørte indsættelsen 100 gange:
INSERT dbo.SalesOrderDetailCopy
(
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
)
SELECT TOP(100000)
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
FROM Sales.SalesOrderDetail;GO 100
Jeg oprettede ikke nogen indekser på tabellen; afhængigt af lagringstilgangen vil jeg oprette et nyt clusteret indeks (columnstore halvdelen af tiden), efter at databasen er gendannet som en del af hver test.
Automatisering af test
Når tabellen med 10 millioner rækker eksisterede, indstillede jeg nogle få indstillinger, sikkerhedskopierede databasen, sikkerhedskopierede loggen to gange og sikkerhedskopierede derefter databasen igen (således at loggen ville have mindst mulig brugt plads, når den blev gendannet):
Næst oprettede jeg en kontroldatabase, hvor jeg ville gemme de gemte procedurer, der ville køre testene, og de tabeller, der ville indeholde testresultaterne (blot start- og sluttidspunktet for hver test) og de præstationsmålinger, der blev opfanget i løbet af alle testene.
Det tog et par forsøg at indfange permutationerne af alle de 864 tests, jeg ønskede at udføre, men jeg endte med dette:
Som forventet indsatte dette 864 rækker med alle disse kombinationer.
Næst oprettede jeg en lagret procedure til at indfange det sæt af målinger, der er beskrevet tidligere.Jeg overvåger også instansen medSentryOne SQL Sentry, så der vil helt sikkert være nogle andre interessante oplysninger til rådighed der, men jeg ønskede også at fange de vigtige detaljer uden brug af tredjepartsværktøjer. Her er proceduren, som gør alt for at producere alle metrikker for et givet tidsstempel i en enkelt række:
Jeg satte den lagrede procedure i et jobtrin og startede den. Du ønsker måske at bruge en anden forsinkelse end tre sekunder – der er en afvejning mellem omkostningerne ved indsamlingen og fuldstændigheden af dataene, som måske hælder mere den ene vej end den anden for dig.
Sluttelig skabte jeg den procedure, der ville indeholde al logikken til at bestemme præcis, hvad der skal ske med kombinationen af parametre for hver enkelt test.Dette tog igen flere gentagelser, men det endelige produkt ser således ud:
Der foregår en masse, men den grundlæggende logik er denne:
- Hent de testspecifikke data (TestID og alle parametrene) fra dbo.Teststable
- Giv SQL Server et spark ved at foretage en sp_configure-ændring og rydde buffersand plan cache
- Gendan en ren kopi af AdventureWorks, med alle 10 millioner rækker intakte,og ingen indekser
- Ændre indstillingerne for databasen afhængigt af parametrene for den aktuelle test
- Opret enten et clustered columnstore-indeks eller et clustered B-tree-indeks
- Opdatere statistik på tabellen manuelt, bare for at være sikker
- Log, at vi har startet testen
- Bestemrk, hvor mange iterationer af løkken vi har brug for, og hvor mange rækker der skal slettes inden for hver iteration
- Inden for løkken:
- Bestem, om vi har brug for at starte en transaktion i denne iteration
- Udfør sletningen
- Bestem, om vi har brug for at committe transaktionen i denne iteration
- Bestem, om vi har brug for checkpoint/backup af loggen i denne iteration
- Efter sløjfen, vi logge, at denne test er færdig, og begå eventuelle uncommittedtransactions
For faktisk at køre testen, jeg ønsker ikke at gøre dette i Management Studio(selv på den samme VM), på grund af alle output, ekstra trafik, og ressourceforbrug.Jeg oprettede en lagret procedure og satte dette ind i et job også:
Det tog langt længere tid, end jeg er behageligt at indrømme. En del af det var fordiJeg havde oprindeligt inkluderet en 0,1% test for rowperloopwhich, som i nogle tilfælde tog flere timer. Så jeg fjernede dem fra tabellen et par dage inde, og kan nemt sige: Hvis du fjerner 1.000.000 rækker, er det højst usandsynligt at slette 1.000 rækker ad gangen er et optimalt valg, uanset andre variabler:

(Selvom det ser ud til at være en anomali i forhold til de fleste andre tests, vil jeg vædde med, at det ikke ville være meget hurtigere end at slette en række eller 10 rækker ad gangen. Og det var faktisk langsommere end at slette halvdelen af tabellen eller det meste af tabellen i alle andre scenarier.)
Præstationsresultater
Efter at have kasseret resultaterne fra 0,1%-testene lagde jeg resten i en andenmetritabel med de indlæste varigheder:
Jeg var nødt til at bruge et outer join på metrikabellen, fordi nogle tests kørte så hurtigt, at der ikke var tid nok til at fange nogen data. Det betyder, at der for nogle af de hurtigere tests ikke vil være nogen korrelation med andre præstationsdetaljer end hvor hurtigt de kørte.
Derpå begyndte jeg at lede efter tendenser og anomalier. Først undersøgte jeg varighed og CPU baseret på, om Delayed Durability (DD) og/eller Accelerated Database Recovery (ADR) var aktiveret:
Resultater (med anomalier fremhævet):

Det ser ud til, at den samlede varighed i gennemsnit forbedres omtrent lige meget, når en af mulighederne er slået til (eller begge – og når begge er aktiveret, er toppen lavere). Der ser ud til at være en udestående varighed for ADR alene, som ikke påvirkede gennemsnittet (denne specifikke test involverede sletning af 9.000.000 rækker, 90.000 rækker ad gangen, i FULL recovery, på et rowstore-bord). CPU-udslaget for DD påvirkede heller ikke gennemsnittet – dette specifikke eksempel var sletning af 1.000.000 rækker på én gang på et columnstore-tabeller.
Hvad med de overordnede forskelle ved sammenligning af rowstore og columnstore?
Resultater:

Columnstore er 20 % langsommere i gennemsnit, men krævede mindre hukommelse. Jeg ville også gerne se virkningen på datafilens og logfilens størrelse og forbrug:
Resultater:

Endeligt synes sletning i chunks på nutidens hardware ikke at have de samme fordele som tidligere, i hvert fald ikke med hensyn til varighed. De 18 hurtigste resultater her og 72 af de hurtigste 100 var tests, hvor alle rækker blev slettet i ét hug, hvilket denne forespørgsel afslører:
Resultater:
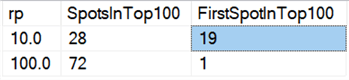
Og hvis vi ser på gennemsnittene på tværs af alle data, som i denne forespørgsel:
Vi ser, at det er hurtigere at slette alle rækker på én gang, uanset om vi sletter10 %, 50 % eller 90 %, end at dele sletninger i stykker på nogen måde (igen i gennemsnit):
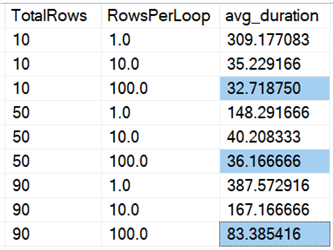
I diagramform:
(Bemærk, at hvis vi fjerner den tidligere identificerede max_durationoutlier på 6.062 sekunder, falder den første kolonne fra 309 sekunder til 162 sekunder.)
Nu er det selv i det bedste tilfælde stadig 33, 36 eller 83 sekunder, hvor adelete kører og potentielt blokerer alle andre, og det er uden hensyntagen til andre målte påvirkninger som hukommelse, logfil, CPU osv. Varighed bør bestemt ikke være dit eneste kriterium; det er bare sådan, at det normalt er det første (og nogle gange det eneste), folk kigger på. Denne test harness skulle vise, at man også kan og bør registrere flere andre målinger, og resultaterne viser, at outliers kan komme hvor som helst fra.
Med denne harness som model kan du konstruere dine egne tests, der fokuserer mere snævert på begrænsningerne og mulighederne i dit miljø. Jeg har ikke undersøgt målingerne fra alle mulige vinkler, da det er mange permutationer, men jeg vil beholde denne database. Så hvis der er andre måder, du ønsker at se dataene opdelt på, så lad mig vide det i kommentarerne nedenfor, så skal jeg se, hvad jeg kan gøre. Du skal bare ikke bede mig om at køre alle testene igen.
Caveats
Dette alt sammen tager ikke højde for en samtidig arbejdsbyrde, virkningen af tabelbegrænsninger som fremmednøgler, tilstedeværelsen af triggers og et væld af andre mulige scenarier.En anden ting at teste (potentielt i et fremtidigt tip) er at have flere jobs, der interagerer med den samme tabel under hele operationen, og måle ting som blokeringsvarigheder, ventetyper og -tider og måle, i hvilke situationer et sæt af aktivitet har en mere dramatisk indvirkning på det andet sæt.
Næste skridt
Læs videre for at få relaterede tips og andre ressourcer:
- CRUD-operationer i SQL Server
- Forskelle mellem Delete og Truncate i SQL Server
- Sletning af historiske data fra en stor højkonkurrent SQL Server-databaseTabel
- Bryd store sletteoperationer op i bidder
- SQL Server Clustered and Nonclustered Columnstore Index Example
- Delayed Durability in SQL Server 2014
- Delayed Durability while Purging Data
- Accelerated Database Recovery in SQL Server 2019
Sidst opdateret: 2019-12-03


Om forfatteren
 Aaron Bertrand (@AaronBertrand) er en passioneret tekniker med brancheerfaring, der går tilbage til Classic ASP og SQL Server 6.5. Han er chefredaktør for den præstationsrelaterede blog SQLPerformance.com og blogger også på sqlblog.org.
Aaron Bertrand (@AaronBertrand) er en passioneret tekniker med brancheerfaring, der går tilbage til Classic ASP og SQL Server 6.5. Han er chefredaktør for den præstationsrelaterede blog SQLPerformance.com og blogger også på sqlblog.org.Se alle mine tips
- Mere SQL Server DBA Tips…