
Podle: Aaron Bertrand | Aktualizováno: 2019-12-03 | Komentáře (1) | Související: Více >Tuning výkonu
Problém
Před několika lety jsem na blogu psal o tom, jak lze snížit dopad na transakční protokol rozdělením operací mazání na části. Místo mazání 100 000 řádkův jedné velké transakci můžete mazat 100 nebo 1 000 nebo libovolný počet řádků najednou v několika menších transakcích ve smyčce. Kromě snížení dopadu na protokol můžete ulevit dlouhotrvajícímu blokování. V té době se SSD disky teprve prosazovaly a novější technologie, jako jsou clustered Columnstore Indexes, Delayed Durability aAccelerated Database Recovery, ještě neexistovaly. Říkal jsem si tedy, že je možná čas na osvěžení, abychom si udělali lepší obrázek o tom, jak to vypadá v SQL Serveru2019.
Řešení
Odstranění velkých částí tabulky není vždy jediným řešením. Pokud odstraníte 95 % tabulky a ponecháte si 5 %, může být ve skutečnosti rychlejší přesunout řádky, které chcete ponechat, do nové tabulky, starou tabulku zrušit a novou přejmenovat. nebo zkopírovat řádky, které chcete ponechat, ven, tabulku zkrátit a pak je zkopírovat zpět. Ale i když je pročištění o tolik větší než zachování, není to vždy možné vzhledem k jiným omezením tabulky, SLA a dalším faktorům.
Pokud se ukáže, že musíte řádky odstranit, budete chtít minimalizovat dopad na transakční protokol a to, jak operace ovlivní zbytek pracovní zátěže.Přístup chunkingu není nová nebo neotřelá myšlenka, ale může dobře fungovat s některými z těchto novějších technologií, takže si je vyzkoušejme v různýchkombinacích.
Pro nastavení máme několik konstant, které budou platit pro každý test:
- SQL Server 2019 RC1, se čtyřmi jádry a 32 GB RAM (maximální paměť serveru =28 GB)
- Tabulka s 10 miliony řádků
- Po každém testu restartujte SQL Server (kvůli obnovení paměti, vyrovnávacích pamětí, a plancache)
- Obnovit zálohu, která již měla aktualizované statistiky a vypnuté automatické statistiky (aby případné spuštěné aktualizace statistik nezasahovaly do operací mazání)
Máme také mnoho proměnných, které se budou v každém testu měnit:
Tímto způsobem vznikne 864 jedinečných testů a věřte, že se chystámautomatizovat všechny tyto permutace.
A metriky, které budeme měřit:
- Celkové trvání
- Průměrné/špičkové využití procesoru
- Průměrné/špičkové využití paměti
- Využití transakčního protokolu/nárůst souborů
- Využití souborů databáze, velikost úložiště verzí (při použití Accelerated DatabaseRecovery)
- Velikost skupiny řádků (při použití Columnstore)
Zdrojová tabulka
Nejprve jsem obnovil kopii AdventureWorks (AdventureWorks2017.bak, abych byl konkrétní). Pro vytvoření tabulky s 10 miliony řádků jsem vytvořil kopii Sales.SalesOrderDetail,s vlastním sloupcem identity, a přidal jsem výplňový sloupec jen proto, abych dal každému řádku trochu více masa a snížil hustotu stránky:
CREATE TABLE dbo.SalesOrderDetailCopy
(
SalesOrderDetailID int IDENTITY,
SalesOrderID int,
CarrierTrackingNumber nvarchar(25),
OrderQty smallint,
ProductID int,
SpecialOfferID int,
UnitPrice money,
UnitPriceDiscount money,
LineTotal numeric(38,6),
rowguid uniqueidentifier,
ModifiedDate datetime,
filler char(50) NOT NULL DEFAULT ''
);
GO
Poté jsem pro vytvoření 10 000 000 řádků vložil 100 000 řádků najednou a vložení provedl 100krát:
INSERT dbo.SalesOrderDetailCopy
(
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
)
SELECT TOP(100000)
SalesOrderID,
CarrierTrackingNumber,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
LineTotal,
rowguid,
ModifiedDate
FROM Sales.SalesOrderDetail;GO 100
Na tabulce jsem nevytvářel žádné indexy; v závislosti na přístupu k ukládání vytvořím po obnovení databáze v rámci každého testu nový clusterový index (v polovině případů sloupcový).
Automatizace testů
Jakmile existovala tabulka s 10 miliony řádků, nastavil jsem několik voleb, zazálohoval databázi,dvakrát zazálohoval log a pak znovu zazálohoval databázi (aby měl log při obnově co nejméně využitého místa):
Dále jsem vytvořil databázi Control, kam jsem ukládal uložené procedury, které spouštěly testy, a tabulky, které uchovávaly výsledky testů (pouze čas zahájení a ukončení každého testu) a metriky výkonu zachycené v průběhu všech testů.
Zachycení permutací všech 864 testů, které jsem chtěl provést, mi zabralo několik pokusů, ale skončil jsem takto:
Podle očekávání to vložilo 864 řádků se všemi těmito kombinacemi.
Dále jsem vytvořil uloženou proceduru pro zachycení sady metrik popsaných dříve.Instanci také monitoruji pomocíSentryOne SQL Sentry, takže tam budou jistě k dispozici další zajímavé informace, ale chtěl jsem také zachytit důležité podrobnosti bez použití nástrojů třetích stran. Zde je procedura, která vychází ze své cesty a vytváří všechny metriky pro danou časovou značku v jediném řádku:
Vložil jsem tuto uloženou proceduru do kroku úlohy a spustil ji. Možná budete chtít použít jiné zpoždění než tři sekundy – existuje kompromis mezi náklady na sběr a úplností dat, který se pro vás může přiklonit více na jednu stranu než na druhou.
Nakonec jsem vytvořil proceduru, která by obsahovala veškerou logiku pro přesné určení, co se má udělat s kombinací parametrů pro každý jednotlivý test.To opět zabralo několik iterací, ale konečný produkt je následující:
Děje se tam toho hodně, ale základní logika je následující:
- Vytáhnout data specifická pro test (TestID a všechny parametry) z dbo.Teststable
- Dejte SQL Serveru zabrat provedením změny sp_configure a vymazáním vyrovnávací paměti a cache plánu
- Obnovte čistou kopii AdventureWorks se všemi 10 miliony řádků,a bez indexů
- Změňte možnosti databáze v závislosti na parametrech aktuálního testu
- Vytvořte buď clusterový index sloupcového skladu, nebo clusterový index B-stromu
- Ručně aktualizujte statistiky tabulky, jen pro jistotu
- Zaznamenejte, že jsme zahájili test
- Určete, kolik iterací smyčky potřebujeme a kolik řádků uvnitř každé iterace odstraníme
- Uvnitř smyčky:
- Určit, zda potřebujeme v této iteraci spustit transakci
- Provést smazání
- Určit, zda potřebujeme v této iteraci odevzdat transakci
- Určit, zda potřebujeme v této iteraci provést checkpoint / zálohovat log
- Po ukončení smyčky, zaznamenáme, že tento test je dokončen, a odevzdáme všechny neodevzdané transakce
Pro skutečné spuštění testu to nechci dělat v Management Studiu(ani na stejném virtuálním stroji), kvůli všem výstupům, dalšímu provozu a využití prostředků.Vytvořil jsem uloženou proceduru a vložil ji také do úlohy:
To trvalo mnohem déle, než je mi příjemné přiznat. Částečně to bylo proto, že jsem původně zahrnul 0,1% test pro rowperloopcož v některých případech trvalo několik hodin. Takže jsem je z tabulky po několika dnech odstranil a mohu snadno říci: pokud odstraňujete 1 000 000 řádků, je velmi nepravděpodobné, že by mazání 1 000 řádků najednou bylo optimální volbou, bez ohledu na další proměnné:

(I když se to zdá být anomálie ve srovnání s většinou ostatních testů, vsadím se, že by to nebylo o moc rychlejší než mazání jednoho řádku nebo 10 řádků najednou. A ve skutečnosti to bylo pomalejšínež smazání poloviny tabulky nebo většiny tabulky v každém jiném scénáři.“
Výsledky výkonnosti
Po vyřazení výsledků z 0,1% testů jsem zbytek vložil do druhémetrické tabulky s načtenými dobami trvání:
Musel jsem použít vnější spojení na metrickou tabulku, protože některé testy probíhaly tak rychle,že nebyl dostatek času na zachycení jakýchkoli dat. To znamená, že u některýchrychlejších testů nebude žádná korelace s jinými výkonnostními údaji než s tím, jak rychle běžely.
Poté jsem začal hledat trendy a anomálie. Nejprve jsem zkontroloval dobu trvání a CPU podle toho, zda byla zapnuta funkce Delayed Durability (DD) a/nebo Accelerated Database Recovery (ADR):
Výsledky (se zvýrazněnými anomáliemi):

Vypadá to, že celková doba trvání se v průměru zlepšila přibližně stejně, když je zapnuta jedna z těchto možností (nebo obě – a když jsou zapnuty obě, je špička nižší). Zdá se, že pro samotné ADR existuje odlehlá hodnota trvání, která neovlivnila průměr (tento konkrétní test zahrnoval mazání 9 000 000 řádků, 90 000řádků najednou, v režimu FULL recovery, v tabulce s řádkovým úložištěm). Odlehlá hodnota CPU pro DD rovněž neovlivnila průměr – tento konkrétní příklad spočíval v odstranění 1 000 000řádků najednou v tabulce se sloupcovým úložištěm.
A co celkové rozdíly při porovnání řádkového a sloupcového úložiště?
Výsledky:

Sloupcové úložiště je v průměru o 20 % pomalejší, ale vyžaduje méně paměti. Chtěl jsem také zjistit dopad na velikost a využití datového souboru a souboru protokolu:
Výsledky:

Nakonec se zdá, že na dnešním hardwaru nemá mazání po částech takové výhody jako kdysi, alespoň co se týče doby trvání. Osmnáct nejrychlejšíchvýsledků zde a 72 z nejrychlejších 100 byly testy, kde byly všechny řádky smazánynajednou, což odhalil tento dotaz:
Výsledky:
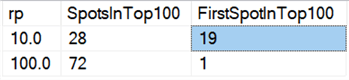
A pokud se podíváme na průměry napříč všemi daty, jako v tomto dotazu:
Vidíme, že mazání všech řádků najednou, bez ohledu na to, zda mažeme10 %, 50 % nebo 90 %, je rychlejší než mazání po částech jakýmkoli způsobem (opět v průměru):
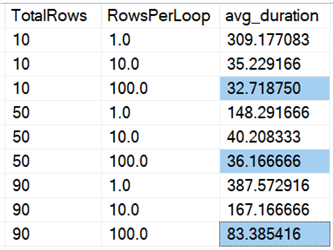
V podobě grafu:
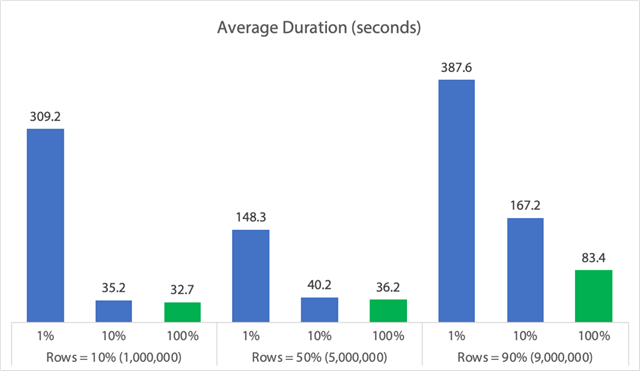
(Všimněte si, že pokud odstraníme dříve identifikovanou hodnotu max_durationoutlier 6,062 sekundy, první sloupec klesne z 309 sekund na 162 sekund.)
Tedy i v nejlepším případě je to stále 33, 36 nebo 83 sekund, kdy běží adelete a potenciálně blokuje všechny ostatní, a to ignorujeme dalšíměřené dopady, jako je paměť, soubor protokolu, procesor atd. Doba trvání by rozhodně neměla být jediným kritériem; jen se stává, že je to obvykle první (a někdy jediná) věc, na kterou se lidé dívají. Tento testovací svazek měl ukázat, že můžete a měli byste zachycovat i několik dalších metrik, a výsledky ukazují, že odlehlé hodnoty mohou pocházet odkudkoli.
Pomocí tohoto svazku jako modelu můžete sestavit vlastní testy zaměřené úžeji na omezení a možnosti ve vašem prostředí. Nezaútočil jsem na metriky ze všech možných úhlů, protože to je spousta permutací,ale hodlám si tuto databázi ponechat. Takže pokud existují další způsoby, jak chcete vidět data rozřezaná na plátky, dejte mi vědět v komentářích níže a já se podívám, co se dá dělat. Jen po mně nechtějte, abych znovu spustil všechny testy.
Caveats
Toto vše nebere v úvahu souběžnou zátěž, vliv omezení tabulky, jako jsou cizí klíče, přítomnost triggerů a řadu dalších možných scénářů.Další věcí k otestování (potenciálně v budoucím tipu) je mít více úloh, kteréinteragují s touto stejnou tabulkou v průběhu operace, a měřit věci, jako je doba trvání blokování, typy a časy čekání, a posoudit, ve kterých situacích má jedna sada činností dramatičtější dopad na druhou sadu.
Další kroky
Přečtěte si související tipy a další zdroje:
- Operace CRUD v SQL Serveru
- Rozdíl mezi Delete a Truncate v SQL Serveru
- Odstranění historických dat z velké vysoce souběžné tabulky databáze SQL Serveru
- Rozdělení velkých operací mazání na části
- .
- Příklad indexů v clusterovém a neclusterovém skladu sloupců SQL Serveru
- Odložená trvanlivost v SQL Serveru 2014
- Odložená trvanlivost při čištění dat
- Zrychlené obnovení databáze v SQL Serveru 2019
Posledně aktualizováno: 2019-12-03


O autorovi
 Aaron Bertrand (@AaronBertrand) je vášnivý technolog se zkušenostmi v oboru, které sahají až ke klasickému ASP a SQL Serveru 6.5. V současné době se věnuje vývoji SQL Serveru. Je šéfredaktorem blogu SQLPerformance.com zaměřeného na výkonnost a bloguje také na adrese sqlblog.org.
Aaron Bertrand (@AaronBertrand) je vášnivý technolog se zkušenostmi v oboru, které sahají až ke klasickému ASP a SQL Serveru 6.5. V současné době se věnuje vývoji SQL Serveru. Je šéfredaktorem blogu SQLPerformance.com zaměřeného na výkonnost a bloguje také na adrese sqlblog.org.Zobrazit všechny mé tipy
- Další tipy pro SQL Server DBA…