
- Získejte přístup k nejlepším ML projektům
- Projekty strojového učení pro začátečníky v roce 2021
- Předpovídání prodeje pomocí datové sady Walmart
- Projekt ML předpovídání prodeje BigMart
- Systém doporučování hudby. Projekt
- Rozpoznávání lidské činnosti pomocí datasetu chytrých telefonů
- Předpověď cen akcií pomocí časových řad
- Předpovídání kvality vína pomocí datasetu kvality vína
- MNIST Klasifikace ručně psaných číslic
- Učení se vytvářet doporučovací systémy s datasetem Movielens
- ML projekt predikce cen bydlení v Bostonu
- Analýza sentimentu sociálních médií pomocí Twitteru Dataset
- Iris Flowers Classification ML Project
- Optimalizace maloobchodních cen pomocí strojového učení
- Analýza predikce odchodu zákazníků
- 1. Předpovídání prodeje pomocí datové sady Walmart
- 2. BigMart Sales Prediction ML Project – Learn about Unsupervised Machine Learning Algorithms
- Projekt systému doporučování hudby
- Rozpoznávání lidské aktivity pomocí datasetu smartphonu
- Prediktor cen akcií pomocí časových řad
- Předpovídání kvality vína pomocí souboru dat o kvalitě vína
- Klasifikace ručně psaných číslic MNIST
- Naučte se vytvářet doporučovací systémy s datasetem Movielens
- Bostonský ML projekt predikce cen bydlení
- Analýza sentimentu v sociálních médiích pomocí datové sady Twitter
- Klasifikační ML projekt Iris Flowers – seznamte se s algoritmy supervisovaného strojového učení
- Projekty strojového učení pro začátečníky se zdrojovým kódem v jazyce Python pro rok 2021
- 12) ML projekt optimalizace maloobchodních cen – dynamický model strojového učení cen pro dynamický trh
- 13) Analýza predikce odchodu zákazníků pomocí ansámblových technik strojového učení
- Jak začít projekt strojového učení?
- 1) První krok:
- 2) Druhý krok: Data
- 3) Třetí krok – sestavení modelu
- 4) Čtvrtý krok – Nasazení modelu do výroby
- Jak si projekty strojového učení zapsat do životopisu?
- Co dál?
Získejte přístup k nejlepším ML projektům
×
Naposledy aktualizováno:
Chcete se naučit strojové učení, ale nedaří se vám s ním začít. Knihy a kurzy nemusí právě stačit, pokud jde o strojové učení, i když vždy poskytují ukázkové kódy a úryvky strojového učení, nedostanete příležitost implementovat strojové učení na reálné problémy a zjistit, jak tyto úryvky kódu do sebe zapadají. Nejlepší způsob, jak začít s výukou strojového učení, je realizovat projekty strojového učení na úrovni začátečníků až pokročilých. Vždy je užitečné získat přehled o tom, jak skuteční lidé začínají svou kariéru v oblasti strojového učení realizací komplexních projektů ML.
V tomto příspěvku na blogu se dozvíte, jak mohou začátečníci jako vy udělat velký pokrok v aplikaci strojového učení na reálné problémy díky těmto fantastickým projektům strojového učení pro začátečníky doporučeným odborníky z oboru. Odborníci z oboru ProjectPro pečlivě sestavili seznam nejlepších projektů strojového učení pro začátečníky, které pokrývají základní aspekty strojového učení, jako je učení pod dohledem, učení bez dohledu, hluboké učení a neuronové sítě. Ve všech těchto projektech strojového učení budete začínat s reálnými soubory dat, které jsou veřejně dostupné. Ujišťujeme vás, že tento blog je pro vás naprosto zajímavý a stojí za přečtení, protože se zde dozvíte vše o nejoblíbenějších projektech strojového učení.
„Jaké projekty mohu dělat se strojovým učením ?“. Tuto otázku nám často kladou začátečníci, kteří se strojovým učením začínají. Odborníci z oboru ProjectPro doporučují prozkoumat několik zajímavých, zajímavých, zábavných a snadných nápadů na projekty strojového učení v různých oblastech podnikání, abyste získali praktické zkušenosti s dovednostmi strojového učení, které jste se naučili. Sestavili jsme seznam inovativních a zajímavých projektů strojového učení se zdrojovými kódy pro profesionály, kteří začínají svou kariéru v oblasti strojového učení. Tyto projekty pro začátečníky v oblasti strojového učení jsou dokonalou směsicí různých typů výzev, se kterými se člověk může setkat při práci inženýra strojového učení nebo datového vědce.
Projekty strojového učení pro začátečníky v roce 2021
-
Předpovídání prodeje pomocí datové sady Walmart
-
Projekt ML předpovídání prodeje BigMart
-
Systém doporučování hudby. Projekt
-
-
Předpověď cen akcií pomocí časových řad
-
Předpovídání kvality vína pomocí datasetu kvality vína
-
MNIST Klasifikace ručně psaných číslic
-
Učení se vytvářet doporučovací systémy s datasetem Movielens
-
ML projekt predikce cen bydlení v Bostonu
-
-
Iris Flowers Classification ML Project
-
Optimalizace maloobchodních cen pomocí strojového učení
-
Analýza predikce odchodu zákazníků
Pustíme se do toho!

1. Předpovídání prodeje pomocí datové sady Walmart
Předpovídání prodeje je jedním z nejčastějších případů použití strojového učení pro identifikaci faktorů, které ovlivňují prodej produktu, a odhad budoucího objemu prodeje. Tento projekt strojového učení využívá datovou sadu společnosti Walmart, která obsahuje údaje o prodeji 98 výrobků ve 45 prodejnách. Datová sada obsahuje prodeje v jednotlivých prodejnách a odděleních na týdenní bázi. Cílem tohoto projektu strojového učení je předpovídat prodeje pro každé oddělení v každé prodejně a pomoci jim tak činit lepší rozhodnutí založená na datech pro optimalizaci prodejních kanálů a plánování zásob. Náročným aspektem práce s datovou sadou Walmart je, že obsahuje vybrané události zlevnění, které ovlivňují prodeje a měly by být zohledněny.
Jedná se o jeden z nejjednodušších a nejzajímavějších projektů strojového učení, ve kterém vytvoříte prediktivní model s využitím datové sady Walmart, abyste odhadli počet prodejů, které uskuteční v budoucnu, a zde je návod, jak na to –
- Importujte data a prozkoumejte je, abyste pochopili strukturu a hodnoty v datech – Začněte importem souboru CSV a proveďte základní průzkumnou analýzu dat (EDA).
- Příprava dat pro modelování – Sloučení více datových souborů a použití funkce seskupení podle analýzy dat.
- Vytvořte graf časových řad a analyzujte jej.
- Přizpůsobte vytvořené modely pro předpovídání prodeje trénovacím datům- Vytvořte model ARIMA pro předpovídání časových řad
- Porovnejte vytvořené modely na testovacích datech.
- Optimalizujte modely pro předpovídání prodeje výběrem důležitých funkcí pro zlepšení skóre přesnosti.
- Využijte nejlepší model strojového učení k předpovědi prodeje v příštím roce.
Po práci na tomto projektu strojového učení Kaggle pochopíte, jak výkonné modely strojového učení mohou zjednodušit celkový proces předpovídání prodeje. Tyto komplexní modely strojového učení pro předpovídání prodeje můžete opakovaně použít ve výrobě k předpovídání prodeje pro jakýkoli obchodní nebo maloobchodní dům.
Chcete pracovat s datovou sadou Walmart? Získejte přístup ke kompletnímu řešení tohoto úžasného projektu strojového učení zde – Walmart Store Sales Forecasting Machine Learning Project
2. BigMart Sales Prediction ML Project – Learn about Unsupervised Machine Learning Algorithms
BigMart sales dataset consists of 2013 sales data for 1559 products across 10 different outlets in different cities. Cílem ML projektu predikce prodejů BigMart je sestavit regresní model pro predikci prodejů každého z 1559 výrobků pro následující rok v každé z 10 různých prodejen BigMart. Datová sada prodejů BigMart se také skládá z určitých atributů pro každý výrobek a prodejnu. Tento model pomáhá společnosti BigMart pochopit vlastnosti produktů a prodejen, které hrají důležitou roli při zvyšování jejich celkových prodejů.
Přistupte ke kompletnímu řešení tohoto ML projektu zde – Řešení projektu strojového učení předpovídání prodejů BigMart
Projekt systému doporučování hudby
Jedná se o jeden z nejoblíbenějších projektů strojového učení, který lze použít v různých oblastech. Doporučovací systém možná dobře znáte, pokud jste používali nějaký web elektronického obchodu nebo filmový/hudební web. Na většině webů elektronického obchodu, jako je například Amazon, vám systém v okamžiku objednávky doporučí produkty, které si můžete přidat do košíku. Podobně na Netflixu nebo Spotify vám na základě filmů, které se vám líbily, zobrazí podobné filmy nebo skladby, které by se vám mohly líbit. Jak to systém dělá? To je klasický příklad, kde lze použít strojové učení.
V tomto projektu používáme datovou sadu z přední asijské služby pro streamování hudby, abychom vytvořili lepší systém pro doporučování hudby. Pokusíme se určit, která nová skladba nebo který nový interpret by se mohl posluchači líbit na základě jeho předchozích voleb. Hlavním úkolem je předpovědět pravděpodobnost, že uživatel bude danou skladbu poslouchat opakovaně v určitém časovém horizontu. V souboru dat je předpověď označena jako 1, pokud uživatel poslouchal stejnou skladbu během jednoho měsíce. Dataset se skládá z toho, kterou píseň slyšel který uživatel a v jakém čase.
Chcete vytvořit doporučovací systém – podívejte se na tento řešený ML projekt zde – Music Recommendation Machine Learning Project
Dataset smartphonu se skládá ze záznamů fitness aktivit 30 lidí zachycených prostřednictvím smartphonu vybaveného inerciálními senzory. Cílem tohoto projektu strojového učení je vytvořit klasifikační model, který dokáže přesně identifikovat lidské fitness aktivity. Práce na tomto projektu strojového učení vám pomůže pochopit, jak řešit problémy s více klasifikacemi.
Přístup ke zdrojovému kódu tohoto ML projektu získáte zde: Human Activity Recognition using Smartphone Dataset Project
Kliknutím sem zobrazíte seznam více než 50 řešených, komplexních řešení projektů velkých dat a strojového učení (opakovaně použitelný kód + videa)
Prediktor cen akcií pomocí časových řad
Jedná se o další zajímavý nápad na projekt strojového učení pro datové vědce/inženýry strojového učení, kteří pracují nebo plánují pracovat s finanční oblastí. Prediktor cen akcií je systém, který se učí o výkonnosti společnosti a předpovídá budoucí ceny akcií. Problémy spojené s prací s daty o cenách akcií spočívají v tom, že jsou velmi granulární, a navíc existují různé typy dat, jako jsou indexy volatility, ceny, globální makroekonomické ukazatele, fundamentální ukazatele a další. Jednou z dobrých vlastností práce s údaji o akciových trzích je to, že finanční trhy mají kratší cykly zpětné vazby, což odborníkům na údaje usnadňuje ověřování jejich předpovědí na základě nových údajů. Chcete-li začít pracovat s daty z akciových trhů, můžete si vybrat jednoduchý problém strojového učení, jako je předpovídání šestiměsíčních cenových pohybů na základě základních ukazatelů ze čtvrtletní zprávy organizací. Datové sady akciového trhu si můžete stáhnout ze stránek Quandl.com nebo Quantopian.com. Existují různé metody předpovídání časových řad pro předpovídání ceny akcií, poptávky atd.
Podívejte se na tento projekt strojového učení, kde se naučíte určit, kterou metodu předpovídání kdy použít a jak ji použít na příkladu předpovídání časových řad. Projekt předpovídání cen akcií pomocí časových řad
Předpovídání kvality vína pomocí souboru dat o kvalitě vína
Je známo, že čím starší víno, tím lepší chuť. Při certifikaci kvality vína se však kromě stáří uplatňuje i několik dalších faktorů, které zahrnují fyziochemické testy, jako je množství alkoholu, pevná kyselost, těkavá kyselost, stanovení hustoty, pH a další. Hlavním cílem tohoto projektu strojového učení je vytvořit model strojového učení pro předpovídání kvality vín na základě zkoumání jejich různých chemických vlastností. Soubor dat o kvalitě vína se skládá ze 4898 pozorování s 11 nezávislými a 1 závislou proměnnou.
Přístup ke kompletnímu řešení tohoto projektu strojového učení získáte zde – Předpovídání kvality vína v jazyce R
Klasifikace ručně psaných číslic MNIST
Hluboké učení a neuronové sítě hrají důležitou roli v rozpoznávání obrazu, automatickém generování textu a dokonce i v samořídících automobilech. Chcete-li začít pracovat v těchto oblastech, musíte začít s jednoduchou a zvládnutelnou sadou dat, jako je datová sada MNIST. Práce s obrazovými daty je obtížnější než s plochými relačními daty a jako začátečníkovi vám doporučujeme vzít a vyřešit úlohu MNIST Handwritten Digit Classification Challenge. Datová sada MNIST je příliš malá na to, aby se vešla do paměti počítače, a je vhodná pro začátečníky. Rozpoznávání ručně psaných číslic však pro vás bude výzvou.
Klasický vstup do řešení problémů rozpoznávání obrazu si můžete udělat přístupem ke kompletnímu řešení zde – MNIST Handwritten Digit Classification Project
Naučte se vytvářet doporučovací systémy s datasetem Movielens
Od Netflixu po Hulu, potřeba vytvořit efektivní filmový doporučovací systém získává postupem času na důležitosti s rostoucí poptávkou moderních spotřebitelů po obsahu na míru. Jednou z nejoblíbenějších datových sad dostupných na webu pro začátečníky, kteří se chtějí naučit vytvářet doporučovací systémy, je datová sada Movielens, která obsahuje přibližně 1 000 209 hodnocení 3 900 filmů od 6 040 uživatelů Movielens. S touto datovou sadou můžete začít pracovat tak, že vytvoříte vizualizaci světového mraku filmových titulů a sestavíte filmový doporučovací systém.
Volný přístup k vyřešeným příkladům kódu naleznete zde (jsou připraveny k použití pro vaše ML projekty)
Bostonský ML projekt predikce cen bydlení
Bostonský datový soubor cen domů obsahuje ceny domů v různých místech Bostonu. Dataset se dále skládá z informací o oblastech, kde se provozuje jiná než maloobchodní činnost (INDUS), míře kriminality (CRIM), věku lidí, kteří vlastní dům (AGE), a několika dalších atributů (dataset má celkem 14 atributů). Datovou sadu Boston Housing si můžete stáhnout z úložiště UCI Machine Learning Repository. Cílem tohoto projektu strojového učení je předpovědět prodejní cenu nového domu pomocí aplikace základních konceptů strojového učení na data o cenách bydlení. Tato datová sada je příliš malá, má 506 pozorování a je považována za dobrý začátek pro začátečníky ve strojovém učení, aby mohli začít s praktickým procvičováním konceptů regrese.
Doporučená četba – 15+ projektů datové vědy pro začátečníky
Platformy sociálních médií, jako jsou Twitter, Facebook, YouTube, Reddit, generují obrovské množství velkých dat, která lze různými způsoby vytěžit k pochopení trendů, nálad a názorů veřejnosti. Data ze sociálních médií se dnes stala důležitými pro budování značky, marketing a podnikání jako celek. Analyzátor sentimentu se učí o různých náladách, které se skrývají za „kusem obsahu“ (může to být IM, e-mail, tweet nebo jakýkoli jiný příspěvek v sociálních médiích), prostřednictvím strojového učení a předpovídá totéž pomocí umělé inteligence. data Twitteru jsou považována za definitivní vstupní bod pro začátečníky, kteří si chtějí procvičit problémy strojového učení analýzy sentimentu. Pomocí datové sady Twitter lze získat poutavou směs obsahu tweetů a dalších souvisejících metadat, jako jsou hashtagy, retweety, umístění, uživatelé a další, které otevírají cestu k pronikavé analýze. Datová sada Twitter se skládá z 31 962 tweetů a má velikost 3 MB. Pomocí dat Twitteru můžete zjistit, co se ve světě říká o daném tématu, ať už jde o filmy, nálady ohledně amerických voleb nebo jakékoli jiné trendové téma, například předpověď, kdo vyhraje mistrovství světa ve fotbale 2018. Práce s datovou sadou Twitter vám pomůže pochopit problémy spojené s dolováním dat ze sociálních médií a také se do hloubky seznámit s klasifikátory. Především problémem, na kterém můžete začít pracovat jako začátečníci, je sestavení modelu pro klasifikaci tweetů jako pozitivních nebo negativních.
Volný přístup k vyřešeným příkladům kódu Pythonu a R naleznete zde (jsou připraveny k použití pro vaše projekty v oblasti datové vědy a ML)
Klasifikační ML projekt Iris Flowers – seznamte se s algoritmy supervisovaného strojového učení
Jedná se o jeden z nejjednodušších projektů strojového učení, přičemž Iris Flowers je nejjednodušší datovou sadou strojového učení v klasifikační literatuře. Tento problém strojového učení se často označuje jako „Hello World“ strojového učení. Datová sada má číselné atributy a začátečníci v ML musí přijít na to, jak data načíst a zpracovat. Dataset kosatců je malý, takže se snadno vejde do paměti a pro začátek nevyžaduje žádné speciální transformace nebo škálování.
Dataset kosatců lze stáhnout z UCI ML Repository – Download Iris Flowers Dataset
Cílem tohoto projektu strojového učení je klasifikovat květy mezi tři druhy – virginica, setosa nebo versicolor na základě délky a šířky okvětních lístků a kališních lístků.
Volný přístup k vyřešeným příkladům strojového učení v jazycích Python a R najdete zde (jsou připraveny k použití pro vaše projekty)
Projekty strojového učení pro začátečníky se zdrojovým kódem v jazyce Python pro rok 2021
12) ML projekt optimalizace maloobchodních cen – dynamický model strojového učení cen pro dynamický trh
Cenové závody rostou nepřetržitě napříč všemi průmyslovými vertikálami a optimalizace cen je klíčem k efektivnímu řízení zisku každého podniku. Určení rozumného cenového rozpětí a provedení úpravy cen produktů za účelem zvýšení prodeje při zachování optimálních ziskových marží bylo v maloobchodě vždy velkou výzvou. Nejrychlejším způsobem, jak dnes mohou maloobchodníci zajistit nejvyšší návratnost investic a zároveň optimalizovat tvorbu cen, je využít sílu strojového učení k vytvoření efektivních cenových řešení. Gigant v oblasti elektronického obchodování Amazon byl jedním z prvních, kdo použil strojové učení při optimalizaci maloobchodních cen, což přispělo k jeho hvězdnému růstu z 30 miliard v roce 2008 na přibližně 1 bilion v roce 2019.

Obrázek: spd. group
100+ Datasets for Machine Learning Projects Curated Specially For You
Řešení problému strojového učení optimalizace maloobchodních cen vyžaduje trénování modelu strojového učení schopného automaticky stanovit ceny produktů tak, jak by je stanovili lidé. Modely strojového učení pro optimalizaci maloobchodních cen přebírají historická data o prodeji, různé charakteristiky produktů a další nestrukturovaná data, jako jsou obrázky a textové informace, aby se naučily pravidla tvorby cen bez lidského zásahu a pomohly maloobchodníkům přizpůsobit se dynamickému prostředí tvorby cen s cílem maximalizovat tržby bez ztráty ziskových marží. Algoritmus strojového učení pro optimalizaci maloobchodních cen zpracovává nekonečné množství cenových scénářů, aby vybral optimální cenu pro produkt v reálném čase tím, že zohlední tisíce latentních vztahů v rámci produktu.
Podívejte se na tento skvělý projekt strojového učení o optimalizaci maloobchodních cen, kde se důkladně ponoříte do analýzy reálných prodejních dat pro kavárnu, kde vytvoříte komplexní řešení strojového učení, které automaticky navrhuje správné ceny produktů.
13) Analýza predikce odchodu zákazníků pomocí ansámblových technik strojového učení
Zákazníci jsou největším aktivem společnosti a udržení zákazníků je důležité pro každou firmu, aby zvýšila příjmy a vybudovala si se zákazníky dlouhodobý smysluplný vztah. Náklady na získání nového zákazníka jsou navíc pětkrát vyšší než náklady na udržení stávajícího zákazníka. Odliv/odchod zákazníků je jedním z nejuznávanějších problémů v podnikání, kdy zákazníci nebo odběratelé přestávají spolupracovat se službou nebo společností. V ideálním případě přestanou být placenými zákazníky. O odchodu zákazníka se hovoří, pokud od jeho poslední interakce s podnikem uplynula určitá doba.
Identifikace toho, zda a kdy zákazník odejde, a rychlé poskytnutí akčních informací zaměřených na udržení zákazníka je pro snížení odchodu klíčové. Není v silách našeho mozku předvídat odchod milionů zákazníků, zde může pomoci strojové učení. Strojové učení poskytuje účinné metody pro identifikaci základních faktorů odchodu zákazníků a preskriptivní nástroje pro jeho řešení. Algoritmy strojového učení hrají zásadní roli při proaktivním řízení odchodu zákazníků, protože odhalují vzorce chování zákazníků, kteří již přestali využívat služby nebo nakupovat produkty. Modely strojového učení pak porovnávají chování stávajících zákazníků s těmito vzorci a identifikují potenciální churnery.

Obrázek Kredit. :gallery.azure.ai
Jak ale začít s řešením problému strojového učení předpovídání míry odchodu zákazníků? Jako u každého jiného problému strojového učení musí datoví vědci nebo inženýři strojového učení shromáždit a připravit data ke zpracování. Aby byl jakýkoli přístup strojového učení účinný, má smysl připravit data ve správném formátu. Feature Engineering je nejkreativnější část modelu strojového učení pro predikci míry odchodu zákazníků, kde datoví specialisté využívají své zkušenosti, obchodní kontext, doménovou znalost dat a kreativitu, aby vytvořili funkce a přizpůsobili model strojového učení tak, aby pochopili, proč v konkrétním podniku dochází k odchodu zákazníků.
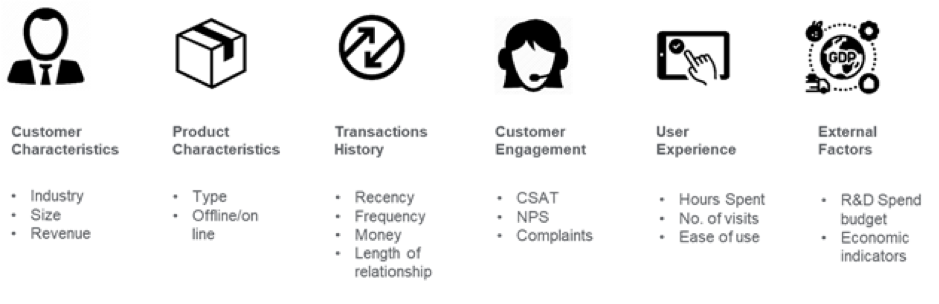
Obrázek Kredit: medium.com
Například v bankovnictví lze pro predikci míry odchodu zákazníků obtížně rozlišit dva účty, které mají stejný měsíční konečný zůstatek. Příznakové inženýrství však může těmto datům přidat časovou dimenzi, takže ML algoritmy mohou rozlišit, zda se měsíční uzávěrkový zůstatek odchýlil od toho, co se od zákazníka obvykle očekává. Indikátory, jako jsou neaktivní účty, rostoucí výběry, trendy používání, čistý odliv zůstatku za posledních několik dní, mohou být včasnými varovnými signály odchodu. Tyto interní údaje v kombinaci s externími údaji, jako jsou nabídky konkurence, mohou pomoci předpovědět odchod zákazníků. Po identifikaci znaků je dalším krokem pochopení důvodů, proč k odchodu dochází v obchodním kontextu, a odstranění znaků, které nejsou silnými prediktory, aby se snížila dimenzionalita.
Podívejte se na tento komplexní projekt strojového učení se zdrojovým kódem v jazyce Python na téma Analýza predikce odchodu zákazníků pomocí ensemble learningu pro boj s odchodem zákazníků.
Jak začít projekt strojového učení?
Žádný projekt nepostupuje úspěšně bez důkladného plánování a strojové učení není výjimkou. Vytvoření prvního projektu strojového učení ve skutečnosti není tak obtížné, jak se zdá, za předpokladu, že máte pevnou strategii plánování. Pro zahájení jakéhokoli projektu ML je třeba dodržet komplexní komplexní přístup – počínaje stanovením rozsahu projektu až po nasazení modelu a jeho správu v produkci Zde je náš pohled na základní kroky plánu projektu strojového učení, který zajistí, že z každého jedinečného projektu vytěžíte maximum –
1) První krok:
Před čímkoli dalším si ujasněte, jaké jsou obchodní požadavky projektu strojového učení
. Při zahájení projektu ML je základním krokem výběr příslušného obchodního případu užití, k jehož řešení bude model strojového učení vytvořen. Výběr správného případu užití strojového učení a vyhodnocení jeho návratnosti je důležité pro úspěch každého projektu strojového učení.
2) Druhý krok: Data
Data jsou krví každého modelu strojového učení a bez dat není možné model strojového učení trénovat. Fáze dat v životním cyklu projektu strojového učení je proces o čtyřech krocích –
-
Požadavky na data – Důležité je porozumět tomu, jaký druh dat bude potřeba, jaký bude formát dat, jaké budou zdroje dat a jaké jsou požadavky na shodu zdrojů dat.
-
Sběr dat – S pomocí správců databází, datových architektů nebo vývojářů je třeba nastavit strategii sběru dat, abyste získali data z míst, kde se nacházejí v rámci organizace, nebo od jiných dodavatelů třetích stran.
-
Průzkumná analýza dat – Tento krok v podstatě zahrnuje ověření požadavků na data, abyste se ujistili, že máte správná data, data jsou v dobrém stavu a bez chyb.
-
Příprava dat – Tento krok zahrnuje přípravu dat pro použití algoritmy strojového učení. Oprava chyb, tvorba příznaků, kódování do datových formátů srozumitelných strojům a oprava anomálií jsou úkoly spojené s přípravou dat.
3) Třetí krok – sestavení modelu
V závislosti na povaze projektu může tento krok trvat několik dní nebo měsíců. Ve fázi modelování přijmete rozhodnutí, který algoritmus strojového učení použijete, a začnete model trénovat na datech. Pro výběr modelu je důležité pochopit míru přesnosti, chybovosti a správnosti, kterou by měl model strojového učení dodržovat. Po natrénování modelu jej vyhodnotíte na validačních datech, abyste analyzovali jeho výkonnost a zabránili nadměrnému přizpůsobení. Vyhodnocení modelu je kritickým krokem, protože pokud model funguje perfektně s historickými daty a vrací špatný výkon s budoucími daty, je k ničemu.
4) Čtvrtý krok – Nasazení modelu do výroby
Tento krok zahrnuje nasazení softwaru nebo aplikace koncovým uživatelům, aby do modelu strojového učení mohla proudit nová data pro další učení. Nasazení modelu strojového učení nestačí, je třeba také zajistit, aby model strojového učení fungoval podle očekávání. Měli byste model přeškolit na nových živých produkčních datech, abyste zajistili jeho přesnost nebo výkonnost – to je ladění modelu. Ladění modelu také vyžaduje ověření modelu, abyste se ujistili, že nedochází k jeho driftu nebo zkreslení.
Jak si projekty strojového učení zapsat do životopisu?
Zkušenosti z reálného světa vás připraví na konečný úspěch jako nic jiného. Čím více jako začátečník v oblasti strojového učení získáte zkušeností s prací na projektech strojového učení v reálném čase, tím lépe budete připraveni uchvátit nejžhavější pracovní místa tohoto desetiletí. Získat práci v oblasti strojového učení po absolvování školení v oblasti datové vědy nebo se stát úspěšným datovým vědcem bude záviset na vaší schopnosti prodat se. Po absolvování komplexního školení v oblasti datové vědy je dalším krokem k získání špičkové pozice inženýra strojového učení nebo datového vědce vytvoření vynikajícího portfolia, které potenciálním zaměstnavatelům ukáže vaši schopnost aplikovat techniky strojového učení. Práce na zajímavých projektech ML je skvělým způsobem, jak nastartovat kariéru podnikového inženýra strojového učení nebo datového vědce. Zaměstnavatelé chtějí vidět, na jakých projektech souvisejících s datovou vědou a strojovým učením jste pracovali, aby mohli posoudit rozsah vašich schopností v oblasti datové vědy a strojového učení. Zdůraznění některých zábavných, skvělých a zajímavých příkladů projektů v oblasti datové vědy a strojového učení ve vašem životopise bude mít větší váhu než vyprávění o tom, kolik toho víte. Zde je návod, jak můžete do životopisu strojového učení přidat úžasné projekty –
- V životopise strojového učení můžete projekty strojového učení zmínit hned za sekcí pracovních zkušeností.
- Sledujte pořadí číslování spolu s názvem projektů, na kterých jste pracovali.
- Po názvu projektu by měla následovat malá stručná informace o datové sadě a zadání problému.
- Zmiňte se o nástrojích a technologiích strojového učení, které jste při dokončení projektu použili.
- V neposlední řadě ve svém portfoliu/životopisu uveďte u každého projektu strojového učení odkaz na GitHub, osobní webové stránky nebo blog, abyste důkladně porozuměli svým úspěchům.
Ať už si chcete vytvořit silné portfolio strojového učení, nebo si chcete procvičit analytické dovednosti, které jste se naučili v kurzu datové vědy, máme pro vás řešení. Mnoho začátečníků v oblasti strojového učení si není jisto, kde začít, jaké projekty strojového učení dělat, jaké nástroje, techniky a rámce strojového učení používat. Začátečníkům v oblasti datové vědy a strojového učení jsme to usnadnili tím, že jsme pro ně připravili seznam zajímavých nápadů na projekty strojového učení spolu s jejich řešením. Tyto nápady na projekty strojového učení jsou převzaty z populárních datových vědeckých výzev Kaggle a jsou skvělým způsobem, jak se strojové učení naučit. Tento seznam projektů je ideálním způsobem, jak si projekty strojového učení zapsat do životopisu. K pochopení řešení projektů z oblasti datové vědy a strojového učení je zapotřebí správné myšlení, ochota učit se a hodně zkoumání dat. Můžete si prohlédnout více než 50 projektů datové vědy a ML založených na souboru dovedností, nástrojů a technik, které se potřebujete naučit.
Předtím, než začnete pracovat na svém projektu, je užitečné mít přístup ke knihovně příkladů kódu projektů strojového učení. Kdykoli se tedy na projektu zaseknete, můžete použít tyto vyřešené příklady, abyste se z této situace dostali.
Přístup k příkladům kódu projektů datové vědy a strojového učení
Co dál?
Mistrem strojového učení se člověk může stát pouze s velkým množstvím praxe a experimentování. Mít teoretické znalosti jistě pomáhá, ale k pokroku nejvíce přispívá aplikace. Žádné teoretické znalosti nemohou nahradit praktické cvičení. Pomůže vám však, když se nejprve seznámíte s výše uvedenými inovativními projekty strojového učení.
Jestliže jste začátečník a se strojovým učením teprve začínáte, pak práce na projektech strojového učení navržených odborníky z oboru na ProjectPro bude jednou z nejlepších investic vašeho času. Tyto projekty byly navrženy pro začátečníky, aby jim pomohly rychle zlepšit jejich dovednosti v oblasti aplikovaného strojového učení a zároveň jim daly možnost prozkoumat zajímavé obchodní případy použití v různých oblastech – maloobchod, finance, pojišťovnictví, výroba a další. Pokud vás tedy učení strojového učení baví, chcete si udržet motivaci a dosáhnout rychlého pokroku, pak jsou zajímavé ML projekty ProjectPro určeny právě vám. Navíc si tyto projekty strojového učení přidejte do svého portfolia a získejte špičkovou práci s vyšším platem a odměňujícími výhodami.

Klikněte sem a prohlédněte si seznam více než 50 vyřešených, komplexních projektových řešení v oblasti strojového učení a velkých dat
|
PŘEDCHOZÍ |
NÁSLEDUJÍCÍ |
.